













本文转载自公众号“读芯术”(ID:AI_Discovery)
这篇文章涵盖了几个最重要的新近发展和最具影响力的观点,涵盖的话题从数据科学工作流的编制到更快神经网络的突破,再到用统计学基本方法解决问题的再思考,同时也提供了将这些想法运用到工作中去的方法。
1. 机器学习系统中隐藏的技术债(Hidden Technical Debt in Machine LearningSystems)
链接:
https://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf
谷歌研究团队提供了在创建数据科学工作流时要避免的反模式的明确说明。这篇论文把技术债的隐喻从软件工程借鉴过来,将其应用于数据科学。

图源:DataBricks
下一篇论文更加详细地探讨了构建一个机器学习产品是软件工程下面一个专门的分支,这个学科中的许多经验也会运用到数据科学中。
如何使用:遵照专家提出的实用技巧简化开发和生产。
2. 软件2.0( Software 2.0)
链接:https://medium.com/@karpathy/software-2-0-a64152b37c35
安德烈·卡帕斯(Andrej Karpathy)的经典文章明确表达了一个范式,即机器学习模型是代码基于数据的软件运用。如果数据科学就是软件,我们所构建的会是什么呢?Ben Bengafort在一篇极有影响力的博文“数据产品的时代”中探讨了这个问题。
(https://districtdatalabs.silvrback.com/the-age-of-the-data-product)
数据产品代表了ML项目的运作化阶段。
如何使用:学习更多有关数据产品如何融入模型选择过程的内容。
3. BERT:语言理解深度双向转换的预训练(BERT: Pre-training of DeepBidirectional Transformers for Language Understanding)
链接:https://arxiv.org/abs/1810.04805
这篇论文里,谷歌研究团队提出了自然语言处理模型,代表了文本分析方面能力的大幅提升。虽然关于BERT为什么如此有效存在一些争议,但这也提示了我们机器学习领域会发现一些没有完全了解其工作方式的成功方法。像大自然一样,人工神经网络还浸没在神秘之中。
如何使用:
- BERT论文可读性很强,包括了一些建议在初始阶段使用的默认超参数设置。
- 不管你是否为NLP新手,请去看看Jay Alammar阐释BERT性能的“BERT的初次使用视图指南”。
- 也请看看ktrain——一个运用于Keras的组件(同时也运用于TensorFlow),能够帮助你在工作中毫不费力地执行BERT。Arun Maiya开发了这个强大的库来提升NLP、图像识别和图论方法的认知速度。
4. 彩票假说:找到稀疏且可训练的神经网络(The Lottery Ticket Hypothesis:Finding Sparse, Trainable Neural Networks)
链接:https://arxiv.org/abs/1803.03635
当NLP模型变得越来越大(看GTP-3的1750亿个参数),人们努力用正交的方式构建一个更小、更快、更有效的神经网络。这样的网络花费更短的运营时间、更低的训练成本和对计算资源更少的需求。
在这篇开创性的论文里,机器学习天才Jonathan Frankle和Michael Carbin概述了显示稀疏子网络的裁剪方法,可以在最初明显增大的神经网络中实现类似的性能。
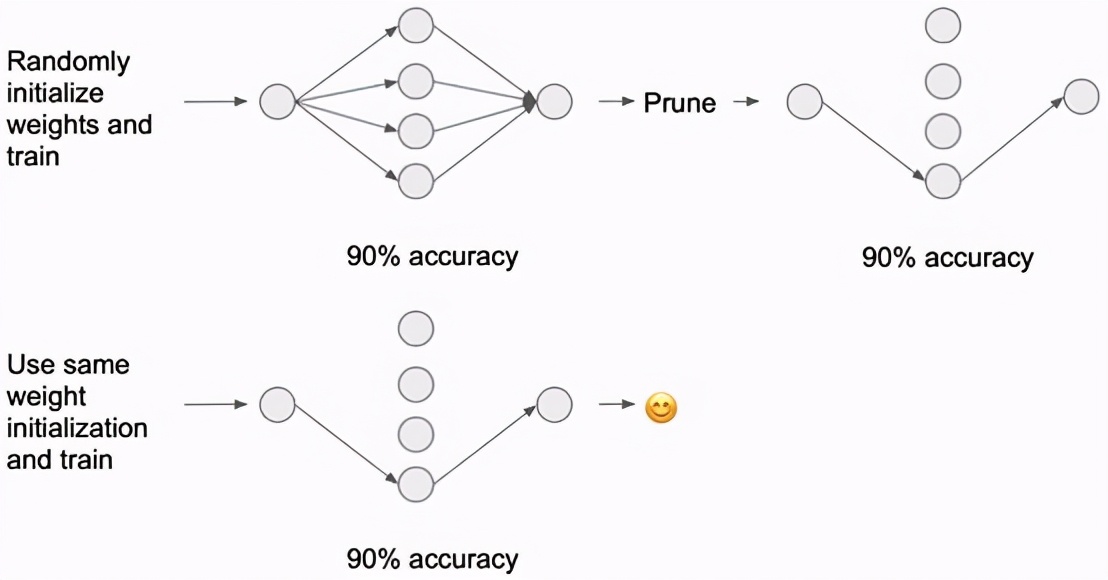
Nolan Day的“彩票分解假说”
彩票指的是与效能十分强大的联系。这个发现提供了许多在储存、运行时间和计算性能方面的优势,并获得了ICLR 2019的最佳论文奖。更深入的研究都建立在这项技术之上,证实了它的适用性并应用于原始稀疏网络。
如何使用:
- 在生产前先考虑删减神经网络。删减网络权重可以减少90%以上的参数,却仍能达到与初始网络相同的性能。
- 同时查看Ben Lorica向Neural Magic讲述的数据交换播客片段,这是一个寻求在灵活的用户界面上利用类似修剪和量化的技术简化稀疏性获取的开端。(https://neuralmagic.com/about/)
5. 松开零假设统计检验的死亡之手(p < .05)(Releasing the death-grip of nullhypothesis statistical testing (p < .05) )
链接:
https://www.researchgate.net/publication/312395254_Releasing_the_death-grip_of_null_hypothesis_statistical_testing_p_05_Applying_complexity_theory_and_somewhat_precise_outcome_testing_SPOT
假设检验的提出早于计算机的使用。考虑到与这个方法相关联的挑战(例如甚至是统计员都觉得解释p值近乎不可能),也许需要时间来想出类似稍精确结果检验(SPOT)的替代方法

xkcd的显著性
如何使用:查看这篇“假设统计检验之死”的博文,一位沮丧的统计员概述了一些与传统方法相关的挑战,并解释了利用置信区间的替代方式。
(https://www.datasciencecentral.com/profiles/blogs/the-death-of-the-statistical-test-of-hypothesis)
这5篇论文能帮助你更深入地认识数据科学!












