介绍
自然语言处理(NLP)是一个令人生畏的领域名称。从非结构化文本中生成有用的结论是很困难的,而且有无数的技术和算法,每一种都有自己的用例和复杂性。作为一个接触NLP最少的开发人员,很难知道要使用哪些方法以及如何实现它们。
如果我以最小的努力提供尽量完美的结果。使用80/20原则,我将向你展示如何在不显著牺牲结果(80%)的情况下快速(20%)交付解决方案。
- “80/20原则认为,少数的原因、投入或努力通常导致大多数结果、产出或回报”
-理查德·科赫,80/20原则的作者
我们将如何实现这一目标?有一些很棒的Python库!我们可能站在巨人的肩膀上,迅速创新,而不是重新发明轮子。通过预先测试的实现和预训练的模型,我们将专注于应用这些方法并创造价值。
本文的目标读者是希望将自然语言处理快速集成到他们的项目中的开发人员。在强调易用性和快速效果的同时,性能也会下降。根据我的经验,80%的技术对于项目来说是足够的,但是也可以从其他地方寻找相关方法
不用多说了,我们开始吧!
什么是NLP?
自然语言处理是语言学、计算机科学和人工智能的一个分支领域,允许通过软件自动处理文本。NLP使机器能够阅读、理解和响应杂乱无章的非结构化文本。
人们通常将NLP视为机器学习的一个子集,但实际情况更为微妙。
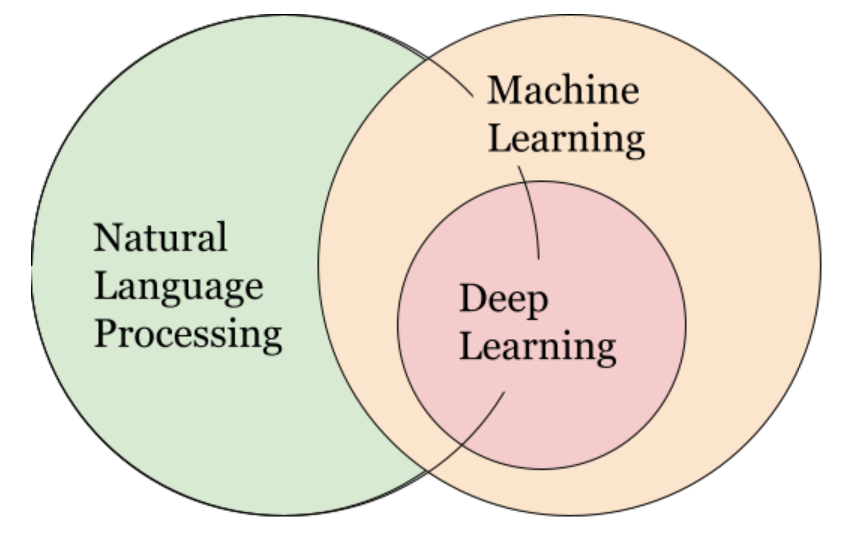
有些NLP工具依赖于机器学习,有些甚至使用深度学习。然而,这些方法往往依赖于大数据集,并且难以实现。相反,我们将专注于更简单、基于规则的方法来加快开发周期。
术语
从最小的数据单位开始,字符是单个字母、数字或标点符号。一个单词是一个字符列表,一个句子是一个单词列表。文档是句子的列表,而语料库是文档的列表。
预处理
预处理可能是NLP项目中最重要的一步,它涉及到清理输入,这样模型就可以忽略噪声,并将注意力集中在最重要的内容上。一个强大的预处理管道将提高所有模型的性能,所以必须强调它的价值。
以下是一些常见的预处理步骤:
- 分段:给定一长串字符,我们可以用空格分隔文档,按句点分隔句子,按空格分隔单词。实现细节将因数据集而异。
- 使用小写:大写通常不会增加性能,并且会使字符串比较更加困难。所以把所有的东西都改成小写。
- 删除标点:我们可能需要删除逗号、引号和其他不增加意义的标点。
- 删除停用词:停用词是像“she”、“the”和“of”这样的词,它们不会增加文本的含义,并且分散对关键字的注意力。
- 删除其他不相关单词:根据你的应用程序,你可能希望删除某些不相关的单词。例如,如果评估课程回顾,像“教授”和“课程”这样的词可能没有用。
- 词干/词根化:词干分析和词根化都会生成词形变化单词的词根形式(例如:“running”到“run”)。词干提取速度更快,但不能保证词根是英语单词。词根化使用语料库来确保词根是一个单词,但代价是速度。
- 词性标注:词性标注以词性(名词、动词、介词)为依据,根据词义和语境来标记单词。例如,我们可以专注于名词进行关键字提取。
这些步骤是成功的预处理的基础。根据数据集和任务的不同,你可以跳过某些步骤或添加新步骤。通过预处理手动观察数据,并在出现问题时进行更正。
Python库

让我们来看看NLP的两个主要Python库。这些工具将在预处理期间,占据非常大的作用
NLTK
自然语言工具包是Python中使用最广泛的NLP库。NLTK是UPenn为学术目的而开发的,它有大量的特征和语料库。NLTK非常适合处理数据和运行预处理:https://www.nltk.org/
NLTK是构建Python程序以处理人类语言数据的领先平台。它提供了易于使用的API
- >>> import nltk
- >>> sentence = "At eight o'clock on Thursday morning Arthur didn't feel very good."
- >>> tokens = nltk.word_tokenize(sentence)
- >>> tokens
- ['At', 'eight', "o'clock", 'on', 'Thursday', 'morning', 'Arthur', 'did', "n't", 'feel', 'very', 'good', '.']
- >>> tagged = nltk.pos_tag(tokens)
- >>> tagged[0:6]
- [('At', 'IN'), ('eight', 'CD'), ("o'clock", 'JJ'), ('or', 'IN'), ('Thursday', 'NNP'), ('morning', 'NN')]
这是NLTK网站上的一个例子,它展示了标记句子和标记词性是多么简单。
SpaCy
SpaCy是一个现代的的库
- import spacy
- nlp = spacy.load("en_core_web_sm")
- text = ("When Sebastian Thrun started working on self-driving cars at "
- "Google in 2007, few people outside of the company took him seriously")
- doc = nlp(text)
- for entity in doc.ents:
- print(entity.text, entity.label_)
- # 输出
- # Sebastian Thrun
- # 谷歌组织
- # 2007日期
们就可以使用SpaCy执行命名实体识别。使用SpaCy api可以快速完成许多其他任务。
GenSim
与NLTK和SpaCy不同,GenSim专门解决信息检索(IR)问题。GenSim的开发重点是内存管理,它包含许多文档相似性模型,包括Latent Semantic Indexing、Word2Vec和FastText。
Gensim是一个Python库,用于主题模型、文档索引和大型语料库的相似性检索。
下面是一个预先训练的GenSim Word2Vec模型的例子,它可以发现单词的相似性。不用担心那些杂乱无章的细节,我们可以很快得到结果。
- import gensim.downloader as api
- wv = api.load("word2vec-google-news-300")
- pairs = [
- ('car', 'minivan'), # 小型货车是一种汽车
- ('car', 'bicycle'), # 也是有轮子的交通工具
- ('car', 'airplane'), # 没有轮子,但仍然是交通工具
- ('car', 'cereal'), # ... 等等
- ('car', 'communism'),
- ]
- for w1, w2 in pairs:
- print('%r\t%r\t%.2f % (w1, w2, wv.similarity(w1, w2)))
- # 输出
- # 'car' 'minivan' 0.69
- # 'car' 'bicycle' 0.54
- # 'car' 'airplane' 0.42
- # 'car' 'cereal' 0.14
- # 'car' 'communism' 0.06
还有更多…
这个列表并不全面,但涵盖了一些用例。
应用
既然我们已经讨论了预处理方法和Python库,让我们用几个例子把它们放在一起。对于每种算法,我将介绍几个NLP算法,根据我们的快速开发目标选择一个,并使用其中一个库创建一个简单的实现。
应用1:预处理
预处理是任何NLP解决方案的关键部分,所以让我们看看如何使用Python库来加快处理速度。根据我的经验,NLTK拥有我们所需的所有工具,并针对独特的用例进行定制。让我们加载一个样本语料库:
- import nltk
- # 加载brown语料库
- corpus = nltk.corpus.brown
- # 访问语料库的文件
- print(corpus.fileids())
- # 输出
- ['ca01', 'ca02', 'ca03', 'ca04', 'ca05', 'ca06', 'ca07', 'ca08', 'ca09', 'ca10', 'ca11', 'ca12', 'ca13', 'ca14', 'ca15', 'ca16',
- 'ca17', 'ca18', 'ca19', 'ca20', 'ca21', 'ca22', 'ca23', 'ca24', 'ca25', 'ca26', 'ca27', 'ca28', 'ca29', 'ca30', 'ca31', 'ca32',
- 'ca33', 'ca34', 'ca35', 'ca36', 'ca37', 'ca38', 'ca39', 'ca40', 'ca41', 'ca42', 'ca43', 'ca44', 'cb01', 'cb02', 'cb03', 'c...
按照上面定义的管道,我们可以使用NLTK来实现分段、删除标点和停用词、执行词干化等等。看看删除停用词是多么容易:
- from nltk.corpus import stopwords
- sw = stopwords.words("english")
- sw += "" # 空字符串
- def remove_sw(doc):
- sentences = []
- for sentence in doc:
- sentence = [word for word in sentence if word not in sw]
- sentences.append(sentence)
- return sentences
- print("With Stopwords")
- print(doc1[1])
- print()
- doc1 = remove_sw(doc1)
- print("Without Stopwords")
- print(doc1[1])
- # 输出
- # 有停用词
- # ['the', 'jury', 'further', 'said', 'in', 'presentments', 'that', 'the', 'city', 'executive', 'committee', 'which', 'had',
- # 'charge', 'of', 'the', 'election', 'deserves', 'the', 'praise', 'and', 'thanks', 'of', 'the', 'city', 'of', 'atlanta', 'for',
- # 'the', 'manner', 'in', 'which', 'the', 'election', 'was', 'conducted']
- # 没有停用词
- # ['jury', 'said', 'presentments', 'city', 'executive', 'committee', 'charge', 'election', 'deserves', 'praise', 'thanks', 'city',
- # 'atlanta', 'manner', 'election', 'conducted']
整个预处理管道占用了我不到40行Python。请参阅此处的完整代码。记住,这是一个通用的示例,你应该根据你的特定用例的需要修改流程。
应用2:文档聚类
文档聚类是自然语言处理中的一个常见任务,所以让我们来讨论一些方法。这里的基本思想是为每个文档分配一个表示所讨论主题的向量:
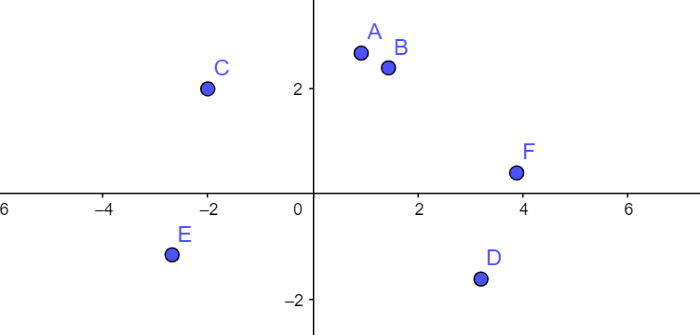
如果向量是二维的,我们可以像上面一样可视化文档。在这个例子中,我们看到文档A和B是紧密相关的,而D和F是松散相关的。即使这些向量是3维、100维或1000维,使用距离度量的话,我们也可以计算相似性。
下一个问题是如何使用非结构化文本输入为每个文档构造这些向量。这里有几个选项,从最简单到最复杂的:
- 词袋:为每个唯一的单词分配一个索引。给定文档的向量是每个单词出现的频率。
- TF-IDF:根据单词在其他文档中的常见程度来加强表示。如果两个文档共享一个稀有单词,则它们比共享一个公共单词更相似。
- 潜在语义索引(LSI):词袋和TF-IDF可以创建高维向量,这使得距离测量的准确性降低。LSI将这些向量压缩到更易于管理的大小,同时最大限度地减少信息损失。
- Word2Vec:使用神经网络,从大型文本语料库中学习单词的关联关系。然后将每个单词的向量相加得到一个文档向量。
- Doc2Vec:在Word2Vec的基础上构建,但是使用更好的方法从单词向量列表中近似文档向量。
Word2Vec和Doc2Vec非常复杂,需要大量的数据集来学习单词嵌入。我们可以使用预训练过的模型,但它们可能无法很好地适应领域内的任务。相反,我们将使用词袋、TF-IDF和LSI。
现在选择我们的库。GenSim是专门为这个任务而构建的,它包含所有三种算法的简单实现,所以让我们使用GenSim。
对于这个例子,让我们再次使用Brown语料库。它有15个文本类别的文档,如“冒险”、“编辑”、“新闻”等。在运行我们的NLTK预处理例程之后,我们可以开始应用GenSim模型。
首先,我们创建一个将标识映射到唯一索引的字典。
- from gensim import corpora, models, similarities
- dictionary = corpora.Dictionary(corpus)
- dictionary.filter_n_most_frequent(1) # removes ""
- num_words = len(dictionary)
- print(dictionary)
- print()
- print("Most Frequent Words")
- top10 = sorted(dictionary.cfs.items(), key=lambda x: x[1], reverse=True)[:10]
- for i, (id, freq) in enumerate(top10):
- print(i, freq, dictionary[id])
- # 输出
- # Dictionary(33663 unique tokens: ['1', '10', '125', '15th', '16']...)
- # 频率最高的词
- # 0 3473 one
- # 1 2843 would
- # 2 2778 say
- # 3 2327 make
- # 4 1916 time
- # 5 1816 go
- # 6 1777 could
- # 7 1665 new
- # 8 1659 year
- # 9 1575 take
接下来,我们迭代地应用词袋、TF-IDF和潜在语义索引:
- corpus_bow = [dictionary.doc2bow(doc) for doc in corpus]
- print(len(corpus_bow[0]))
- print(corpus_bow[0][:20])
- # 输出
- # 6106
- # [(0, 1), (1, 3), (2, 1), (3, 1), (4, 1), (5, 1), (6, 1), (7, 1), (8, 1), (9, 2), (10, 1), (11, 1), (12, 2), (13, 2), (14, 2), (15,
- # 1), (16, 2), (17, 2), (18, 3), (19, 1)]
- tfidf_model = models.TfidfModel(corpus_bow)
- corpus_tfidf = tfidf_model[corpus_bow]
- print(len(corpus_tfidf[0]))
- print(corpus_tfidf[0][:20])
- # 输出
- # 5575
- # [(0, 0.001040495879718581), (1, 0.0011016669638018743), (2, 0.002351365659027428), (3, 0.002351365659027428), (4,
- # 0.0013108697793088472), (5, 0.005170600993729588), (6, 0.003391861538746009), (7, 0.004130105114011007), (8,
- # 0.003391861538746009), (9, 0.008260210228022013), (10, 0.004130105114011007), (11, 0.001955787484706956), (12,
- # 0.0015918258736505996), (13, 0.0015918258736505996), (14, 0.008260210228022013), (15, 0.0013108697793088472), (16,
- # 0.0011452524080876978), (17, 0.002080991759437162), (18, 0.004839366251287288), (19, 0.0013108697793088472)]
- lsi_model = models.LsiModel(corpus_tfidf, id2word=dictionary, num_topics=20)
- corpus_lsi = lsi_model[corpus_tfidf]
- print(len(corpus_lsi[0]))
- print(corpus_lsi[0])
- # 输出
- # 15
- # [(0, 0.18682238167974372), (1, -0.4437583954806601), (2, 0.22275580411969662), (3, 0.06534575527078117), (4,
- # -0.10021080420155845), (5, 0.06653745783577146), (6, 0.05025291839076259), (7, 0.7117552624193217), (8, -0.3768886513901333), (9,
- # 0.1650380936828472), (10, 0.13664364557932132), (11, -0.03947144082104315), (12, -0.03177275640769521), (13,
- # -0.00890543444745628), (14, -0.009715808633565214)]
在大约10行Python代码中,我们处理了三个独立的模型,并为文档提取了向量表示。利用余弦相似度进行向量比较,可以找到最相似的文档。
- categories = ["adventure", "belles_lettres", "editorial", "fiction", "government",
- "hobbies", "humor", "learned", "lore", "mystery", "news", "religion",
- "reviews", "romance", "science_fiction"]
- num_categories = len(categories)
- for i in range(3):
- print(categories[i])
- sims = index[lsi_model[corpus_bow[i]]]
- top3 = sorted(enumerate(sims), key=lambda x: x[1], reverse=True,)[1:4]
- for j, score in top3:
- print(score, categories[j])
- print()
- # 输出
- # adventure
- # 0.22929086 fiction
- # 0.20346783 romance
- # 0.19324714 mystery
- # belles_lettres
- # 0.3659389 editorial
- # 0.3413822 lore
- # 0.33065677 news
- # editorial
- # 0.45590898 news
- # 0.38146105 government
- # 0.2897901 belles_lettres
就这样,我们有结果了!冒险小说和浪漫小说最为相似,而社论则类似于新闻和政府。
应用3:情感分析
情感分析是将非结构化文本解释为正面、负面或中性。情感分析是分析评论、衡量品牌、构建人工智能聊天机器人等的有用工具。
与文档聚类不同,在情感分析中,我们不使用预处理。段落的标点符号、流程和上下文可以揭示很多关于情绪的信息,所以我们不想删除它们。
为了简单有效,我建议使用基于模式的情感分析。通过搜索特定的关键词、句子结构和标点符号,这些模型测量文本的积极消极性。以下是两个带有内置情感分析器的库:
VADER 情感分析:
VADER 是 Valence Aware Dictionary and sEntiment Recognizer的缩写,是NLTK用于情感分析的扩展。它使用模式来计算情绪,尤其适用于表情符号和短信俚语。它也非常容易实现。
- from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
- analyzer = SentimentIntensityAnalyzer()
- print(analyzer.polarity_scores("This class is my favorite!!!"))
- print(analyzer.polarity_scores("I hate this class :("))
- # 输出
- # {'neg': 0.0, 'neu': 0.508, 'pos': 0.492, 'compound': 0.5962}
- # {'neg': 0.688, 'neu': 0.312, 'pos': 0.0, 'compound': -0.765}
TextBlob情感分析:
一个类似的工具是用于情感分析的TextBlob。TextBlob实际上是一个多功能的库,类似于NLTK和SpaCy。在情感分析工具上,它与VADER在报告情感极性和主观性方面都有所不同。从我个人的经验来看,我更喜欢VADER,但每个人都有自己的长处和短处。TextBlob也非常容易实现:
- from textblob import TextBlob
- testimonial = TextBlob("This class is my favorite!!!")
- print(testimonial.sentiment)
- testimonial = TextBlob("I hate this class :(")
- print(testimonial.sentiment)
- # 输出
- # Sentiment(polarity=0.9765625, subjectivity=1.0)
- # Sentiment(polarity=-0.775, subjectivity=0.95)
注意:基于模式的模型在上面的例子中不能很好地处理这样的小文本。我建议对平均四句话的文本进行情感分析。
其他应用
这里有几个附加的主题和一些有用的算法和工具来加速你的开发。
- 关键词提取:命名实体识别(NER)使用SpaCy,快速自动关键字提取(RAKE)使用ntlk-rake
- 文本摘要:TextRank(类似于PageRank)使用PyTextRank SpaCy扩展,TF-IDF使用GenSim
- 拼写检查:PyEnchant,SymSpell Python端口
希望这些示例有助于演示Python中可用于自然语言处理的大量资源。不管问题是什么,有人开发了一个库来简化流程。使用这些库可以在短时间内产生很好的结果。
提示和技巧
通过对NLP的介绍、Python库的概述以及一些示例应用程序,你几乎可以应对自己的挑战了。最后,我有一些技巧和技巧来充分利用这些资源。
- Python工具:我推荐Poetry 用于依赖关系管理,Jupyter Notebook用于测试新模型,Black和/或Flake8用于保持代码风格,GitHub用于版本管理。
- 保持条理:从一个库跳到另一个库,复制代码到当前你编写的代码测试虽然很容易实现,但是不好。我建议采取你采取合适的更慎重的方法,因为你不想在匆忙中错过一个好的解决方案。
- 预处理:垃圾进,垃圾出。实现一个强大的预处理管道来清理输入非常重要。目视检查处理后的文本,以确保所有内容都按预期工作。
- 展示结果:选择如何展示你的结果会有很大的不同。如果输出的文本看起来有点粗糙,可以考虑显示聚合统计信息或数值结果。