












处理缺失的数据并不是一件容易的事。 方法的范围从简单的均值插补和观察值的完全删除到像MICE这样的更高级的技术。 解决问题的挑战性是选择使用哪种方法。 今天,我们将探索一种简单但高效的填补缺失数据的方法-KNN算法。
KNN代表" K最近邻居",这是一种简单算法,可根据定义的最接近邻居数进行预测。 它计算从您要分类的实例到训练集中其他所有实例的距离。
正如标题所示,我们不会将算法用于分类目的,而是填充缺失值。 本文将使用房屋价格数据集,这是一个简单而著名的数据集,仅包含500多个条目。
这篇文章的结构如下:
- 数据集加载和探索
- KNN归因
- 归因优化
- 结论
数据集加载和探索
如前所述,首先下载房屋数据集。 另外,请确保同时导入了Numpy和Pandas。 这是前几行的外观:
默认情况下,数据集缺失值非常低-单个属性中只有五个:

让我们改变一下。 您通常不会这样做,但是我们需要更多缺少的值。 首先,我们创建两个随机数数组,其范围从1到数据集的长度。 第一个数组包含35个元素,第二个数组包含20个(任意选择):
- i1 = np.random.choice(a=df.index, size=35)
- i2 = np.random.choice(a=df.index, size=20)
这是第一个数组的样子:

您的数组将有所不同,因为随机化过程是随机的。 接下来,我们将用NAN替换特定索引处的现有值。 这是如何做:
- df.loc[i1, 'INDUS'] = np.nan
- df.loc[i2, 'TAX'] = np.nan
现在,让我们再次检查缺失值-这次,计数有所不同:

这就是我们从归因开始的全部前置工作。 让我们在下一部分中进行操作。
KNN归因
整个插补可归结为4行代码-其中之一是库导入。 我们需要sklearn.impute中的KNNImputer,然后以一种著名的Scikit-Learn方式创建它的实例。 该类需要一个强制性参数– n_neighbors。 它告诉冒充参数K的大小是多少。
首先,让我们选择3的任意数字。稍后我们将优化此参数,但是3足以启动。 接下来,我们可以在计算机上调用fit_transform方法以估算缺失的数据。
最后,我们将结果数组转换为pandas.DataFrame对象,以便于解释。 这是代码:
- from sklearn.impute import KNNImputer
- imputer = KNNImputer(n_neighbors=3)
- imputed = imputer.fit_transform(df)
- df_imputed = pd.DataFrame(imputed, columns=df.columns)
非常简单。 让我们现在检查缺失值:

尽管如此,仍然存在一个问题-我们如何为K选择正确的值?
归因优化
该住房数据集旨在通过回归算法进行预测建模,因为目标变量是连续的(MEDV)。 这意味着我们可以训练许多预测模型,其中使用不同的K值估算缺失值,并查看哪个模型表现最佳。
但首先是导入。 我们需要Scikit-Learn提供的一些功能-将数据集分为训练和测试子集,训练模型并进行验证。 我们选择了"随机森林"算法进行训练。 RMSE用于验证:
- from sklearn.model_selection import train_test_split
- from sklearn.ensemble import RandomForestRegressor
- from sklearn.metrics import mean_squared_error
- rmse = lambda y, yhat: np.sqrt(mean_squared_error(y, yhat))
以下是执行优化的必要步骤:
迭代K的可能范围-1到20之间的所有奇数都可以
- 使用当前的K值执行插补
- 将数据集分为训练和测试子集
- 拟合随机森林模型
- 预测测试集
- 使用RMSE进行评估
听起来很多,但可以归结为大约15行代码。 这是代码段:
- def optimize_k(data, target):
- errors = []
- for k in range(1, 20, 2):
- imputer = KNNImputer(n_neighbors=k)
- imputed = imputer.fit_transform(data)
- df_imputed = pd.DataFrame(imputed, columns=df.columns)
- X = df_imputed.drop(target, axis=1)
- y = df_imputed[target]
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
- model = RandomForestRegressor()
- model.fit(X_train, y_train)
- preds = model.predict(X_test)
- error = rmse(y_test, preds)
- errors.append({'K': k, 'RMSE': error})
- return errors
现在,我们可以使用修改后的数据集(在3列中缺少值)调用optimize_k函数,并传入目标变量(MEDV):
- k_errors = optimize_k(data=df, target='MEDV')
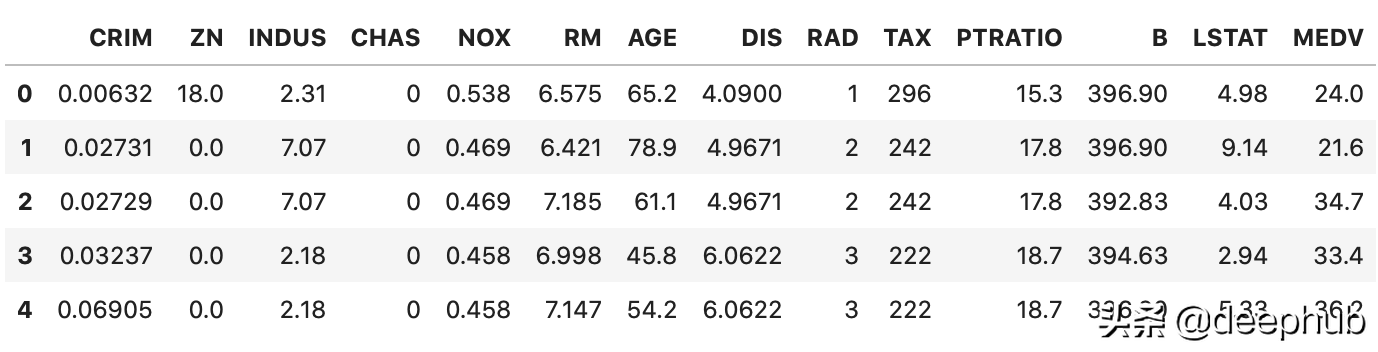
就是这样! k_errors数组如下所示:
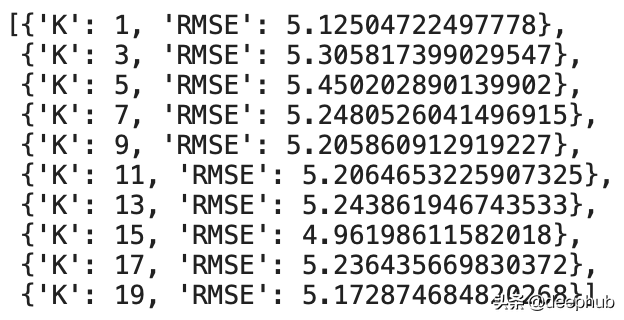
以视觉方式表示:
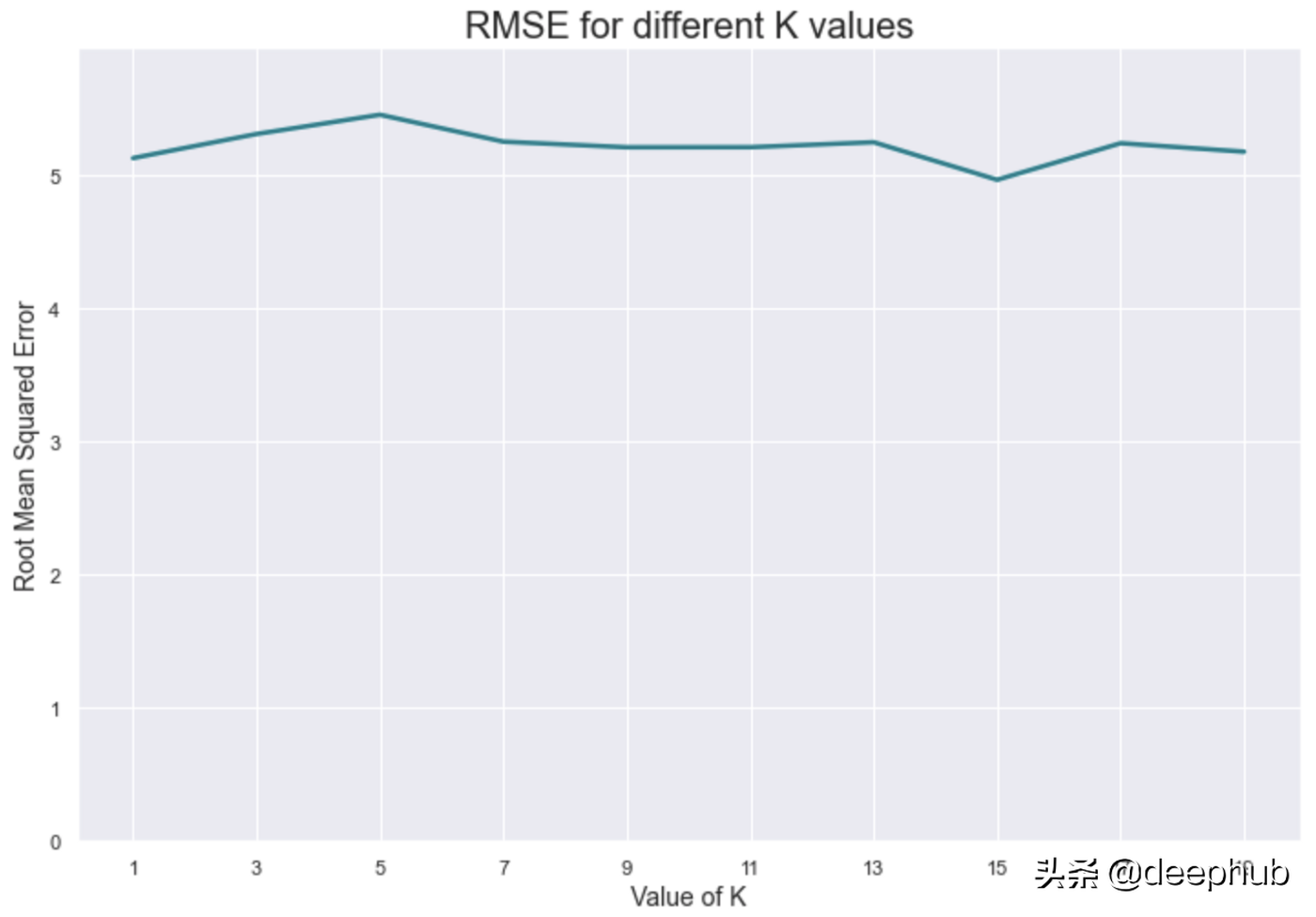
看起来K = 15是给定范围内的最佳值,因为它导致最小的误差。 我们不会涵盖该错误的解释,因为它超出了本文的范围。 让我们在下一节中总结一下。
总结
编写处理缺少数据归因的代码很容易,因为有很多现有的算法可以让我们直接使用。 但是我们很难理解里面原因-了解应该推定哪些属性,不应该推算哪些属性。 例如,可能由于客户未使用该类型的服务而缺失了某些值,因此没有必要执行估算。
最终确定是否需要进行缺失数据的处理,还需要有领域的专业知识,与领域专家进行咨询并研究领域是一种很好的方法。

















