













/前言/
前几天给大家分享了在Scrapy中如何利用Xpath选择器从网页中采集目标数据——详细教程(上篇),没来得及上车的小伙伴可以戳进去看看,今天继续上篇的内容往下进行。
/具体实现/
9、根据点赞数采集的方法,我们可以很快的定位到收藏数,其对应的网页结构稍微有些不同,但是分析方法是一致的,不再赘述,如下图所示。
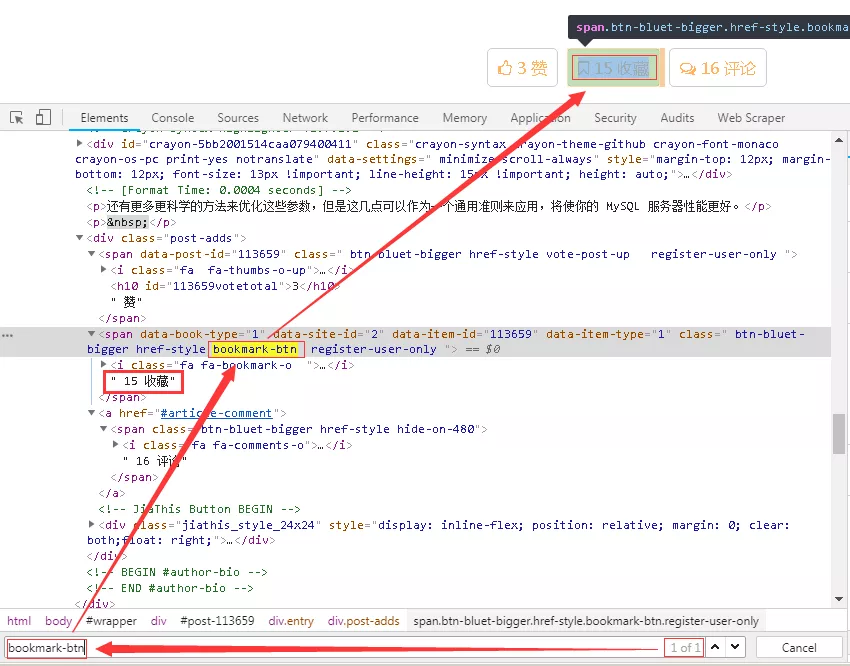
10、这里直接给出调试的代码,如下图所示。

11、不过我们需要的是其中的数字,这时候就可以利用正则表达式进行匹配,关于正则表达式的文章,之前有过连载,不熟悉正则表达式的小伙伴可以翻看历史文章,有详细说明的。在Pycharm中进行调试,代码也很简单,如下图所示。
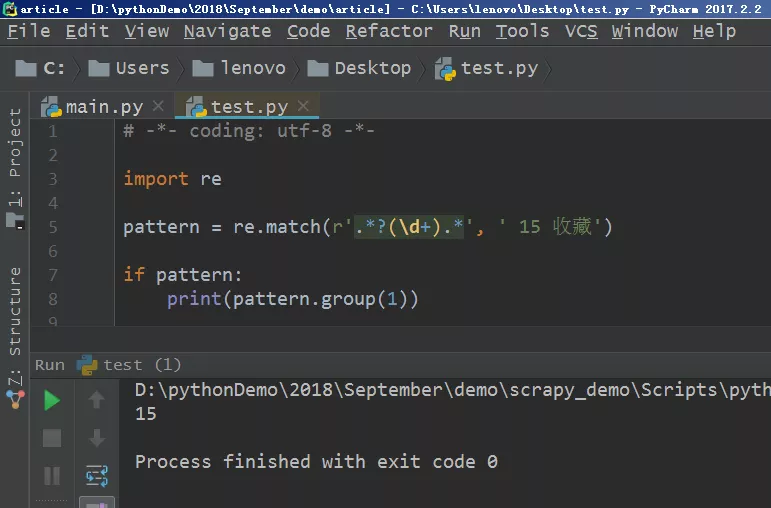
尔后将该代码放入到爬虫主体文件中即可,记得将“15 收藏”这部分替换成collection_num即可。
12、评论数相对简单一些,其有专门的一个标签,如下图所示。
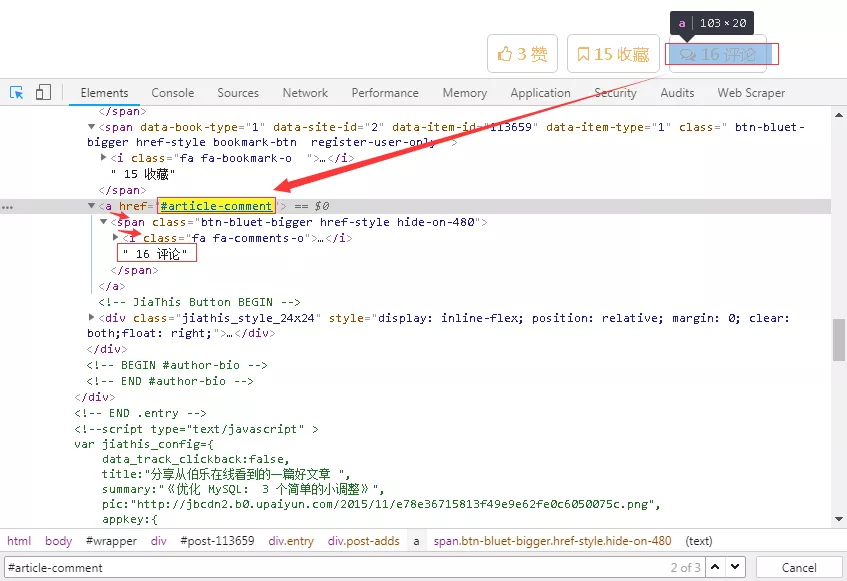
13、需要注意的是评论数这里的标签不是class,而是href,需要和网页上对应,否则取出的值为空列表。
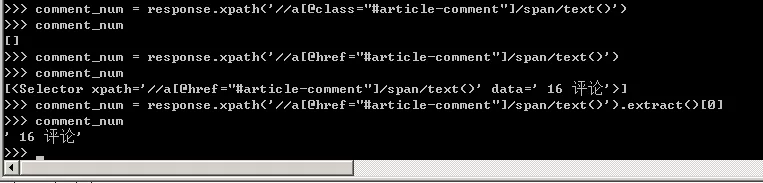
14、同收藏数一样,仍然要以正则表达式的形式去匹配数字,可以直接复制收藏数的代码,然后将收藏数collection_num改为评论数的comment_num即可。

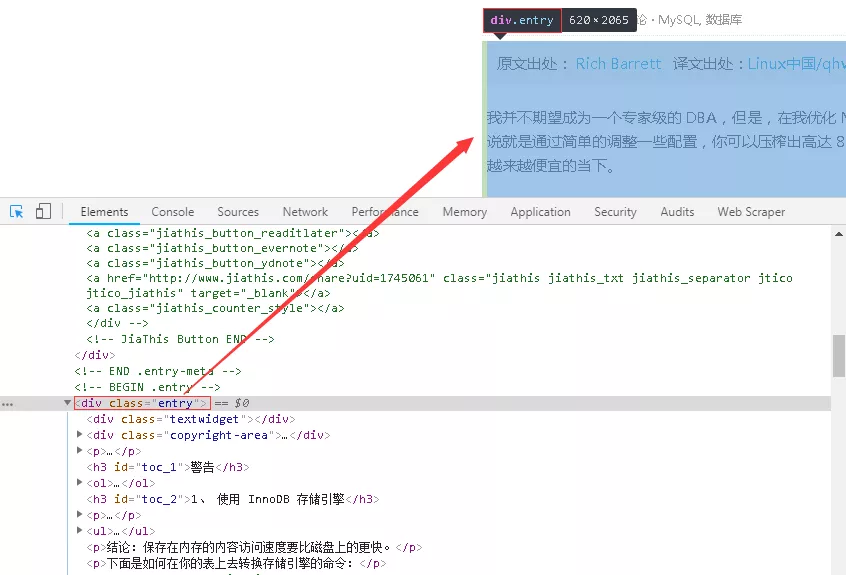
15、关于正文的提取,不同的网页有不同的结构,而且相对复杂,这里不做细究,整体目标是将网页内容和标签均提取出来。分析网页结构,发现正文内容在“entry”标签下,如下图所示。
\
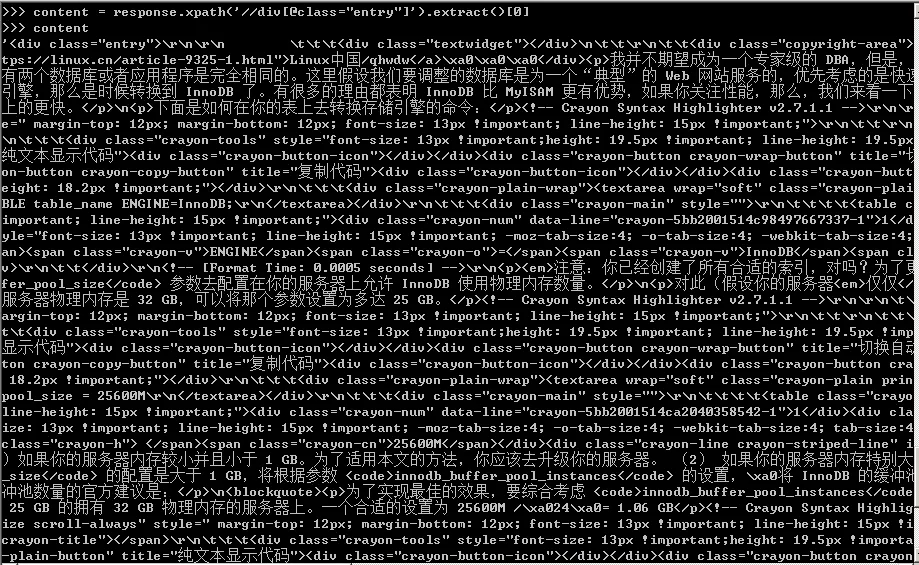
16、之后在scrapyshell调试,可以得到内容的Xpath表达式,如下图所示。
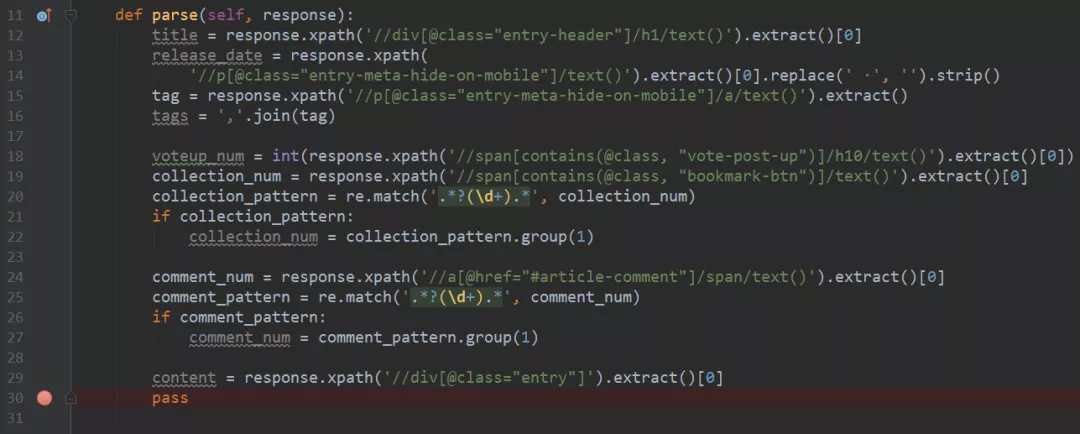
17、到这里,该网页中的信息提取的差不多了,结合上面的分析和Xpath表达式,我们得到的整体代码如下图所示。
18、尔后进行Debug调试,查看代码中获取的内容,如下图所示,十分清晰。
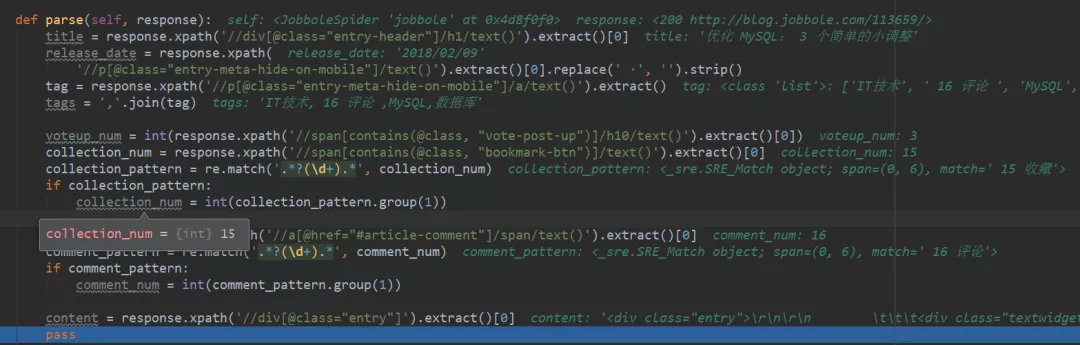
19、下图是控制台部分显示出的变量结果,与代码中显示的内容和网页上的信息都是保持一致的。
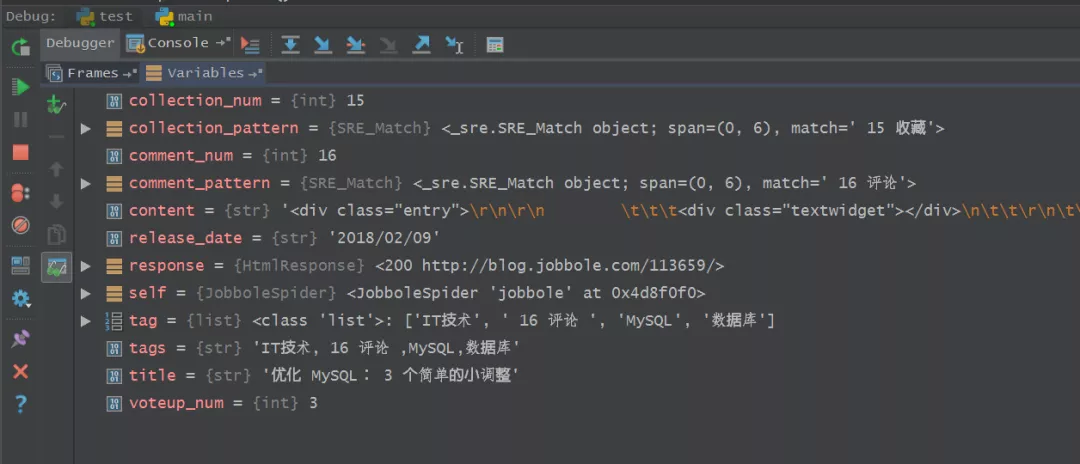
至此,关于Xpath表达式的具体应用教程先告一段落。总体来看,我们需要利用F12快捷键来审查网页元素,尔后分析网页结构并进行交互,然后根据网页结构写出Xpath表达式,习惯性的结合scrapy shell进行调试,得到调优的表达式,写入爬虫文件中去,最后执行爬虫程序或者Debug调试查看最终的数据采集结果。
/小结/
本文基于Xpath理论基础,主要介绍了Scrapy爬虫框架中利用Xpath选择器提取某个网页中目标数据的方法,结合scrapy shell进行调试,得到调优的表达式,写入爬虫文件中去,希望对大家的学习有帮助。
想学习更多关于Python的知识,可以参考学习网址:http://pdcfighting.com/,点击阅读原文,可以直达噢~
















