Keras 和 PyTorch 都是对初学者非常友好的深度学习框架,两者各有优势,很多研究者和开发者在选择框架时可能会举棋不定。基于这种情况,grid.ai CEO、纽约大学博士 William Falcon 创建了 PyTorch Lightning,为 PyTorch 披上了一件 Keras 的外衣。
Lightning 是 PyTorch 非常轻量级的包装,研究者只需要编写最核心的训练和验证逻辑,其它过程都会自动完成。因此这就有点类似 Keras 那种高级包装,它隐藏了绝大多数细节,只保留了最通俗易懂的接口。Lightning 能确保自动完成部分的正确性,对于核心训练逻辑的提炼非常有优势。
今日,PyTorch Lightning 在推特宣布,1.0.0 版本现在可用了,并发布新的博客文章详细描述了 PyTorch Lightning 的运行原理和新的 API。William Falcon 表示自己非常期待有一天,当用户查看 GitHub 上的复杂项目时,深度学习代码不再那么令人望而生畏。
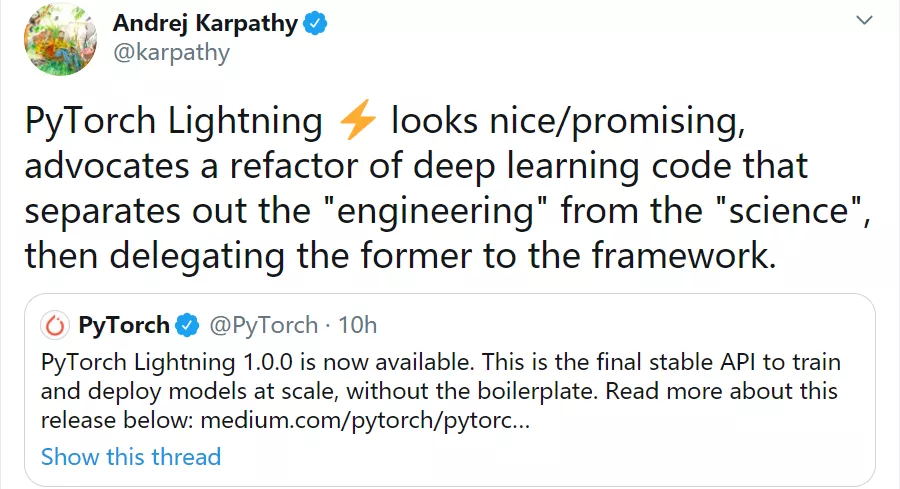
特斯拉 AI 负责人 Andrej Karpathy 也评论称:「这看起来很棒,也很有前途。PyTorch Lightning 倡导对深度学习代码进行重构,将『工程(硬件)』与『科学(代码)』分割开,然后将前者委托给框架。」
过去几个月里,PyTorch Lightning 团队一直在微调 API、完善文档和记录教程,最终使得 V1.0.0 顺利面世。在接下来的博客文章中,该团队对 PyTorch Lightning 进行了详尽的解读。
- 博客地址:https://medium.com/pytorch/pytorch-lightning-1-0-from-0-600k-80fc65e2fab0
- GitHub 地址:https://github.com/PyTorchLightning/pytorch-lightning
PyTorch Lightning 的运行原理和目标
人工智能的发展速度比单一框架发展要快得多。深度学习领域在不断发展,主要体现在复杂度与规模性两方面。Lightning 提供了一种为复杂模型交互设计的用户体验,同时抽象化了工程中许多零散的细节,如多 GPU 和多 TPU 训练、提前停止、日志记录等…
像 PyTorch 这样的框架出现的时间,正是人工智能主要关注网络架构的阶段。

这些框架提供所有的部件来组合极其复杂的模型,在研究和生产方面做得非常出色。但是,一旦模型开始交互,像 GAN, BERT 或者是自动编码器,范式就被打破,很快就失去了极好的灵活性,很难按照项目规模进行维护。
与之前的框架不同,PyTorch Lightning 用来封装一系列相互作用的模型,即深度学习系统。Lightning 是为当今世界更复杂的研究以及生产案例而建立的,在这种情况下,许多模型使用复杂的规则进行交互。

自动编码系统
PyTorch Lightning 的第二个关键原理是硬件和科学代码分开。Lightning 的发展可以大规模地利用大量计算,而不会向用户呈现任何抽象概念。通过这种分离,你可以获得以前不可能实现的新功能,比如,无需更改代码就可以在笔记本电脑上使用 CPU 调试 512 GPU。

最后,Lightning 希望成为一个社区驱动的框架。
构建良好的深度学习模型需要大量的专业知识和小技巧,才能使系统正常工作。在世界各地,数以百计的工程师和博士不断地实现同样的代码。现在,Lightning 的贡献者社区不断壮大,有超过 300 名最具天赋的深度学习人士,他们选择分配相同的能量并进行完全相同的优化,但却有成千上万的人从他们的努力中受益。
PyTorch Lightning 1.0.0 有哪些新功能
Lightning 1.0.0 标志着一个稳定的最终 API。这对使用 Lightning 的研究者来说是一件好事,因为他们的代码不会轻易被破坏或改变。
1. 研究与生产
Lightning 的核心优势是:使得最先进的人工智能研究能够大规模进行。这是一个为专业研究人员设计的框架,可以在最大的计算资源上尝试最难的想法,而不会失去任何灵活性。
Lightning 1.0.0 使大规模的部署模型变得简单。代码可以轻松导出。
这意味着数据科学家、研究人员等团队现在就可以成为生产模型的人,而不需要庞大的机器学习工程师团队。
Lightning 旨在提供一种帮助研究者大幅缩短生产时间的方法,同时又不丧失任何研究所需的灵活性
Grid AI 是用于在云上进行大规模训练模型的本机平台。该平台允许构建深度学习模型的研究者在大规模计算上进行迭代,然后将模型部署到可扩展环境中,该环境能够处理深度学习系统的最大流量。
2. 度量指标
pytorch_lightning.metrics 是一种 Metrics API,旨在在 PyTorch 和 PyTorch Lightning 中轻松地进行度量指标的开发和使用。更新后的 API 提供了一种内置方法,可针对每个步骤跨多个 GPU(进程)计算指标,同时存储统计信息。这可以让用户在一个阶段结束时计算指标,而无需担心任何与分布式后端相关的复杂度。
- class LitModel(pl.LightningModule):
- def __init__(self):
- ...
- self.train_acc = pl.metrics.Accuracy()
- self.valid_acc = pl.metrics.Accuracy()
- def training_step(self, batch, batch_idx):
- logits = self(x)
- ...
- self.train_acc(logits, y)
- # log step metric
- self.log('train_acc_step', self.train_acc)
- def validation_step(self, batch, batch_idx):
- logits = self(x)
- ...
- self.valid_acc(logits, y)
- # logs epoch metrics
- self.log('valid_acc', self.valid_acc)
要实现自定义指标,只需将 Metric 基类子类化,并实现__init__()、update() 和 compute() 方法。用户需要做的就是正确调用 add_state(),以用 DDP 实现自定义指标。对使用 add_state() 添加的度量指标状态变量要调用 reset()。
- from pytorch_lightning.metrics import Metric
- class MyAccuracy(Metric):
- def __init__(self, dist_sync_on_step=False):
- super().__init__(dist_sync_on_stepdist_sync_on_step=dist_sync_on_step)
- self.add_state("correct", default=torch.tensor(0), dist_reduce_fx="sum")
- self.add_state("total", default=torch.tensor(0), dist_reduce_fx="sum")
- def update(self, preds: torch.Tensor, target: torch.Tensor):
- preds, target = self._input_format(preds, target)
- assert preds.shape == target.shape
- self.correct += torch.sum(preds == target)
- self.total += target.numel()
- def compute(self):
- return self.correct.float() / self.total
3. 手动优化 VS 自动优化
使用 Lightning,用户不需要担心何时启用 / 停用 grad,只要从 training_step 中返回带有附加图的损失即可进行反向传播或更新优化器,Lightning 将会自动进行优化。
- def training_step(self, batch, batch_idx):
- loss = self.encoder(batch[0])
- return loss
但是,对于某些研究,如 GAN、强化学习或者是带有多个优化器或内部循环的某些研究,用户可以关闭自动优化,并完全由自己控制训练循环。
首先,关闭自动优化:
- trainer *=* Trainer(automatic_optimization*=False*)
现在训练循环已经由用户自己掌握。
- def training_step(self, batch, batch_idx, opt_idx):
- (opt_a, opt_b, opt_c) = self.optimizers()
- loss_a = self.generator(batch[0])
- # use this instead of loss.backward so we can automate half
- # precision, etc...
- self.manual_backward(loss_a, opt_a, retain_graph=True)
- self.manual_backward(loss_a, opt_a)
- opt_a.step()
- opt_a.zero_grad()
- loss_b = self.discriminator(batch[0])
- self.manual_backward(loss_b, opt_b)
- ...
4. Logging
Lightning 让带有 logger 的集成变得非常简单,只要在 LightningModule 中调用 log() 方法,系统就会将已记录的数量发送到用户选择的 logger 上。默认使用 Tensorboard,但是你也可以选择其他支持的 logger。
- def training_step(self, batch, batch_idx):
- self.log('my_metric', x)
根据调用. log() 的位置,Lightning 会自动确定何时记录(在每一步和每个阶段),但是用户也可以通过手动使用 on_step 和 on_epoch 来重写默认行为。
但是 on_epoch=True 将会在整个训练阶段累积记录值。
- def training_step(self, batch, batch_idx):
- self.log('my_loss', loss, on_step=True, on_epoch=True, prog_bar=True, logger=True)
5. 数据流
Lightning 弃用了 EvaResult 和 TrainResult,这有利于简化数据流并将训练和验证循环(loop)中的日志记录与数据解耦。
每个循环(训练、验证和测试)具有三个可以实现的 hook,具体如下:
- x_step
- x_step_end
- x_epoch_end
为了演示数据流的运行方式,以下代码实现中使用到了训练循环(即 x=training):
- outs *=* []
- *for* batch *in* data:
- out *=* training_step(batch)
- outs*.*append(out)training_epoch_end(outs)
在 training_step 中返回的任意内容可以作为 training_epoch_end 的输入。
- def training_step(self, batch, batch_idx):
- prediction = …
- return {'loss': loss, 'preds': prediction}
- def training_epoch_end(self, training_step_outputs):
- for out in training_step_outputs:
- prediction = out['preds']
- # do something with these
验证和测试循环的代码实现也是同样的步骤。如果想要使用 DP 或者 DDP2 分布式模式(即在 GPU 上分割 batch),则使用 x_step_end 进行手动聚合(或者不实现,令 lightning 进行自动聚合)。
6. 检查点
现在,Lightning 可以通过用户最后训练 epoch 的状态,在当前工作目录中自动保存检查点。这保证用户可以在训练中断的情况下重新开始。
此外,用户可以自定义检查点行为,以监控任意数量的训练或验证步骤。例如,如果用户想要基于自己的验证损失来更新检查点,则可以按照以下步骤完成:
- 计算想要监控的任意度量或其他数量,如验证损失;
- 通过 log() 方法记录下数量以及 val_loss 等键(key);
- 初始化 ModelCheckpoint 回调函数,将 monitor 设置为数量的 key;
- 将回调函数 checkpoint_callback 返回训练器 flag。
具体代码过程如下:
- from pytorch_lightning.callbacks import ModelCheckpoint
- class LitAutoEncoder(pl.LightningModule):
- def validation_step(self, batch, batch_idx):
- x, y = batch
- y_hat = self.backbone(x)
- # 1. calculate loss
- loss = F.cross_entropy(y_hat, y)
- # 2. log `val_loss`
- self.log('val_loss', loss)
- # 3. Init ModelCheckpoint callback, monitoring 'val_loss'
- checkpoint_callback = ModelCheckpoint(monitor='val_loss')
- # 4. Pass your callback to checkpoint_callback trainer flag
- trainer = Trainer(checkpoint_callbackcheckpoint_callback=checkpoint_callback)
所有 API 的变化,包括 bug 修复等可以参考 GitHub 项目。
【本文是51CTO专栏机构“机器之心”的原创译文,微信公众号“机器之心( id: almosthuman2014)”】