10月22日,巨杉数据库将正式发布其金融级分布式数据库「SequoiaDB v5.0」。在正式发布前,就让我们一起来尝尝鲜,看看5.0版本将有哪些技术新特性。
作为国内最早布局分布式数据库产品的公司,巨杉数据库自2011年成立起,9年来一直坚持以原生分布式数据库作为核心产品,聚焦于金融业。2017年,巨杉数据库成为首批入选Gartner数据库榜单的国产分布式数据库。
从发布1.0版本至今,已有超百家金融企业对巨杉数据库进行了大规模部署。特别在银行核心系统,巨杉数据库已累计为数百个应用提供高并发零宕机在线数据服务。

此次发布的「SequoiaDB v5.0」主要包括三大核心特性:跨引擎事务一致性、原生分布式金融级容灾、多云多平台开放架构。

「跨引擎事务一致性」
与众多云原生数据库一样,巨杉数据库提供存储计算分离云服务架构,并支持在此架构上构建包括:MySQL、PostgreSQL、Spark等多种数据库引擎。客户可以灵活选择需要的数据库引擎,实现无须代码修改的平滑迁移。
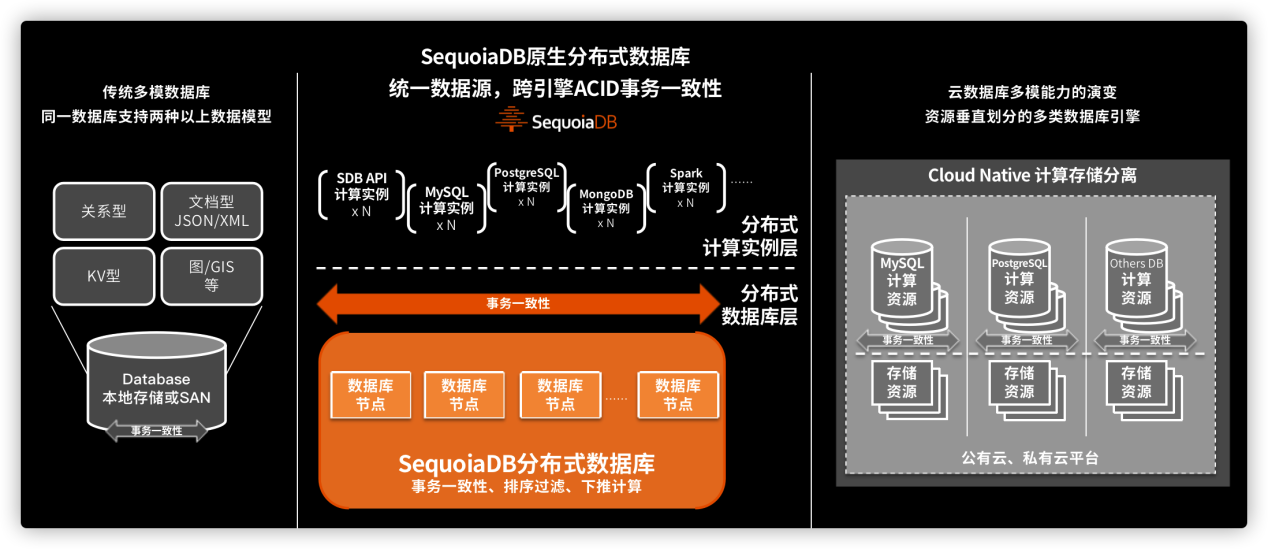
但不同的是,巨杉数据库底层并非构建与一个简单的分布式存储,或计算资源平台。巨杉数据库底层是一个完整的分布式数据库,具备完整的事务一致性、排序过滤、下推计算等能力。而上层计算实例层只承担SQL(兼容MySQL、PostgreSQL等)或API(SequoiaDB API、MongoDB API等)解析及业务计算的工作,所以不同引擎下发的操作,事务一致性在分布式引擎层进行控制。
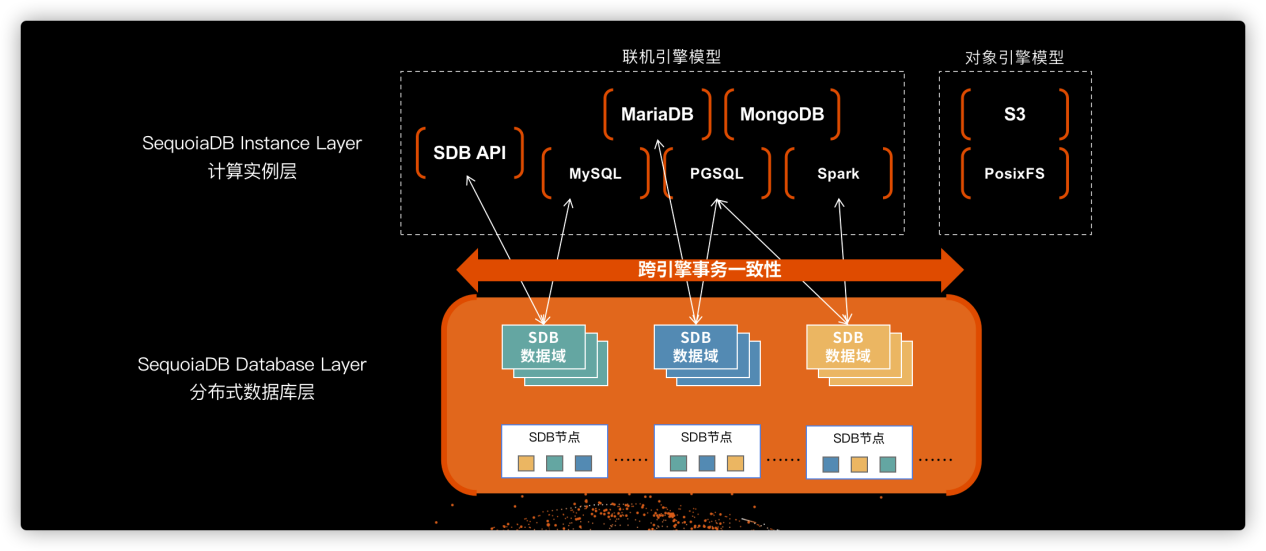
基于此特性不同微服务之间不但可以按照技术需求,灵活选择所需的数据库引擎。基于独有的跨事务一致性能力,更可以支持不同引擎之间灵活的数据共享,并保障ACID事务一致,为金融及对数据一致性要求极高的行业提供数据中台及微服务架构下的最佳分布式数据库应用实践。
「金融级四层容灾熔断保障」
巨杉数据库提供包括:“数据中心”、“服务器”、“磁盘”及“数据表”一共四层的金融级容灾熔断保障。为金融行业提供不同级别,灵活粒度的精细化容灾保障。

「数据中心层」:提供包括双中心双活、两地三中心、甚至三地五中心的部署架构。为适应不同数据中心间网略延迟的不同,我们提供包括:最大保护、最大性能、最高可用三种策略,适应不同网络场景的需求。
「服务器层」:无论是分布式数据库底层,还是计算实例层,巨杉数据库都支持横向扩展。同时由于计算实例并不承担数据一致性及数据存储,因此每个计算节点实际上只是一个无状态的计算程序。
「磁盘层」:通过AI故障预判、故障自动剔除,以及HDD/SSD混合部署的能力,降低由单个磁盘损坏而导致的节点切换概率,从而提高系统的可用性。
「数据表层」:可以针对各个表的不同需求,独立设置最小副本数,灵活控制其数据的可靠性,所有配置在线生效无须停库。容灾熔断深度细化到基于数据表的维度,为特殊应用提供灵活的容灾熔断控制机制。
「企业级技术生态圈」
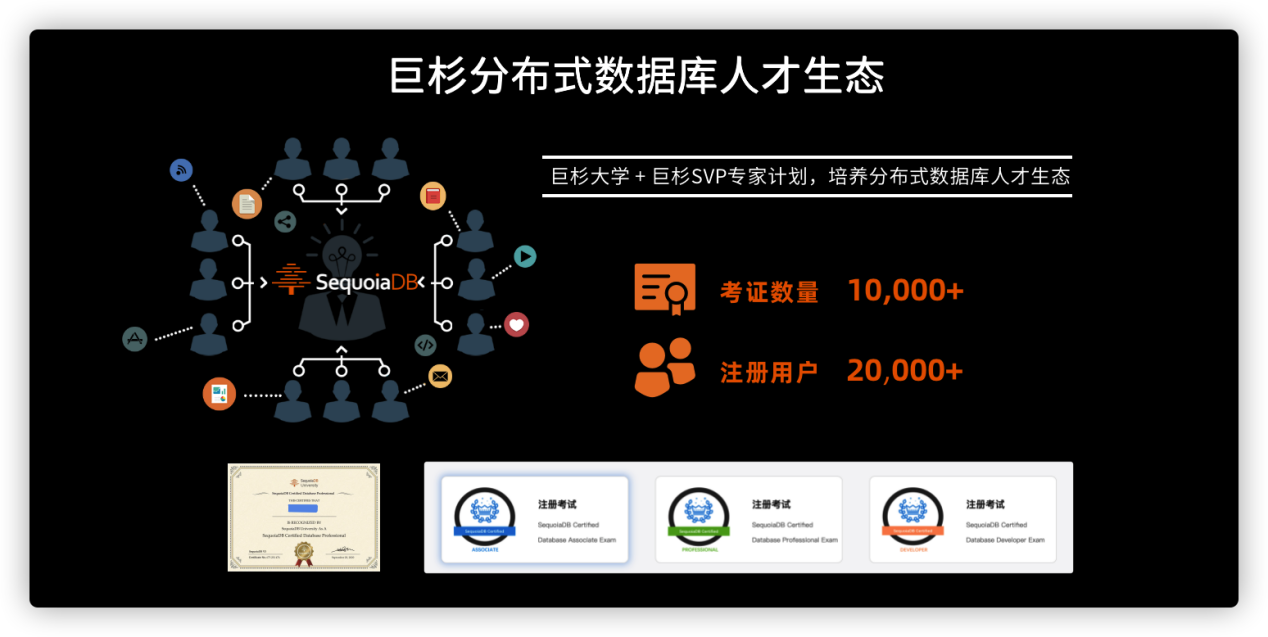
巨杉数据库专注金融行业应用,已积累大量银行客户的最佳实践,并已在近百家大型商业银行核心生产业务上线,广泛应用于金融领域多个场景。技术生态建设方面,当前已经有超过1万人通过巨杉数据库工程师认证,规模超过IBM DB2等传统数据库,成为全国最大的分布式数据库社区之一。
与开发者同行,深耕企业级数据沃土。更多「SequoiaDB v5.0」特性,敬请期待。
巨杉数据库5.0线上发布会链接 http://www.sequoiadb.com/cn/Release