云计算是新的服务形式,它有万亿级别的市场空间。人工智能迎来了高速发展阶段,正在引爆智能时代。云计算与人工智能看似是两个独立的技术生态,其实有千丝万缕的关系,两者的结合将会相得益彰,释放出更多价值。那么云上人工智能有什么样的价值呢?我们将在本文进行一些介绍。
一、 云计算与人工智能
现如今,无论是城市还是农村,自来水取水是绝对的主流,只需轻轻拧开水龙头,源源不断的水立刻就流出来了,这些水是经过处理和检测才送到了老百姓的家里的,无须担心水质问题,无需自己打井,更无需管理汲水设备。
云计算与此类似,只需连上云,计算应用就“自然来“了。这种集约式的转变正在IT世界如火如荼地进行当中,企业从自建机房/数据中心转而采用专业的云计算服务商的云服务,无需自己运维管理软硬件基础设施,只要按需求采购按用量付费,再也不用人人都要懂点运维知识,企业可以减少投入,将更多精力放在业务本身。
云计算虽然已经发展了十几年,但云计算本身并没有为IT技术发展带来质变,它本身更多是技术交付模式的变化,是一种按需多快好省地交付所需服务,以更集约的方式满足原有需求的方法。随着云计算发展变化的深入,这种集约的云服务模式逐渐从量变发展出了质变,特别是当云计算遇上人工智能和机器学习的时候。
从1956年达特茅斯的一场会议开始,人类开启了对于人工智能的探索,但受限于算力,人工智能经过了几次热潮,始终停留在实验室和影视作品的幻想里,与大多数人的生活相距甚远。但在摩尔定律的作用下,算力不断增强,而且算力的单位能源消耗成本越来越低,人工智能(具体而言是机器学习)终于迎来了属于它的时代。
这个时代里,云计算正在快速发展,云计算弹性的资源,灵活可用的部署方式,让人工智能更好更快地进行部署和落地。反过来说,人工智能的创新与发展的成果通过庞大的云计算平台来放大。两者相互促进、相互成就。云计算与人工智能的结合是必然的,会有越来越多的机器学习在云上进行。
亚马逊云科技是全球领先的云计算供应商,在云计算方面有非常丰富的云产品布局。在人工智能及机器学习方面也有完善的产品和服务集合,使得用户一方面有许多可直接调用API的服务,另一方面,还能在云上完成机器学习构建、训练、部署的全流程,例如,通过亚马逊云科技著名的机器学习开发服务Amazon SageMaker,即可达成这项目标。
Amazon SageMaker可以说是帮助企业踏入机器学习旅程的一张通票。Amazon SageMaker作为云上机器学习平台的典型代表,利用云的优势降低机器学习成本,成为了亚马逊云科技目前非常具有特色、非常实用的云上机器学习服务。
二、 为什么需要用云上机器学习平台
技术的发展史就是技术方案成本降低史,旧时王谢堂前燕,飞入寻常百姓家,说的是技术迭代造就的市场成就。
智能时代下,各种算法方面已有数十年的充足积累,数据存储成本也足够低,算力也是易于获得的资源,特别是在云计算基础设施的帮助下,将人工智能(机器学习)所需的三大要素进行了紧密集成,综合使用成本大大降低。当年,Wintel联盟打造的PC生态让电脑变成个人消费品;而今,云计算的发展对于人工智能的普及落地也将有同等重要的作用。
机器学习从数据准备、到模型训练,再到模型调优…… 整个流程对于基础设施的需求相对明确。数据准备阶段和模型部署阶段在满足需求的前提下尽可能要控制成本;而在训练阶段,则要求算力能在规定时间里完成训练任务。考虑到对算力的需求存在峰值和低谷,云计算弹性能力让资源召之即来,挥之即去,按需付费的特点对于降低成本非常合适。
企业在现有架构上部署一套机器学习的方案不是不行,只是除了要克服上述资源成本方面的问题,还要考虑到管理一整套方案的隐性成本,设立一套关于机器学习业务的流程,还要规避自行处理数据合规方面的问题,应对可能出现的数据泄露问题,等等。与其自行解决这些问题,不如选用一套成熟、经过众多企业验证的云上解决方案。
Amazon SageMaker是一个构建、训练与部署机器学习模型的全托管服务,作为典型的云上机器学习平台,能完美解决上述问题,同时避免了企业采购和部署软硬件平台的前期投入。机器学习环境配置需要安装配置许多软件, Amazon SageMaker可以节省后期运维升级维护上的投入,节省大量成本,利用云按需付费的特点让投入物尽其用。
Amazon SageMaker能将繁琐的训练过程变得简单高效,减少训练过程耗费的时间和精力,让企业以很少的投入就能使用机器学习带来的诸多便利和优势。接下来,我们通过具体的操作来介绍Amazon SageMaker云上机器学习开发平台的优势。
三、云上机器学习开发平台实战
2020年4月底,亚马逊云科技在中国区的光环新网和西云数据都上线了Amazon SageMaker。为便于通俗讲解,这里选用亚马逊云科技全球区域的个人账户来进行实操。中国区域的Amazon SageMaker服务和全球区域的绝大部分服务是一样的,除了暂不提供数据标注(Labelling)以外,大部分与全球版的一致。
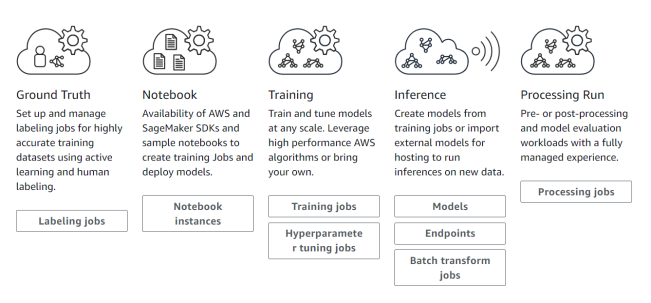
亚马逊云科技于2017年首次发布了Amazon SageMaker,自此就不断“迭代”更新。它提供从数据准备、模型构建、模型训练/调优、到模型部署推理等全流程支持。
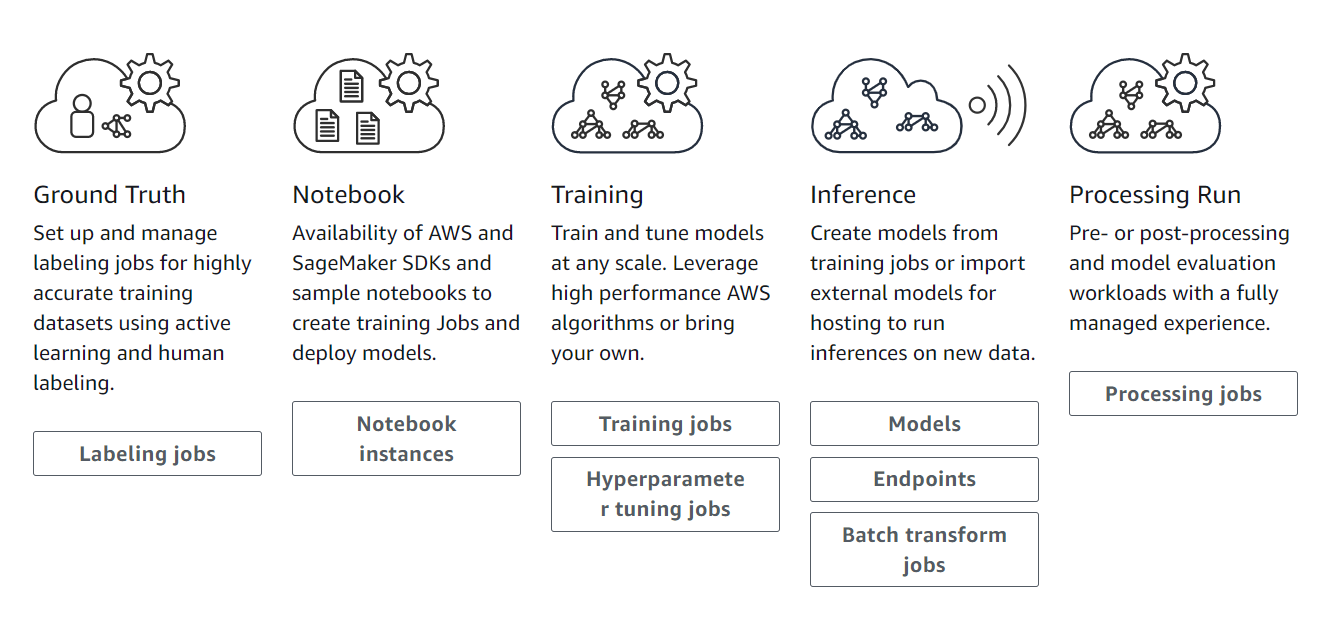
图片来源于亚马逊云科技全球网站截图
其中,数据准备能提供的服务就是数据标注,毕竟现在的机器学习还是以监督式学习为主,这一服务与Amazon Mechanical Turk的数据标注外包服务有关联,同时还提供了自动数据标注的能力。
模型构建和训练到部署,大部分都是在托管的Jupyter Notebook里完成的,以致于有人误以为Amazon SageMaker就只是亚马逊云科技托管的Jupyter Notebook。
1,Amazon SageMaker初步利用了云的优势
接下来,我们创建Notebook instances实例来实战体验一下,看看Amazon SageMaker是怎么利用云的优势打造AI方案的。
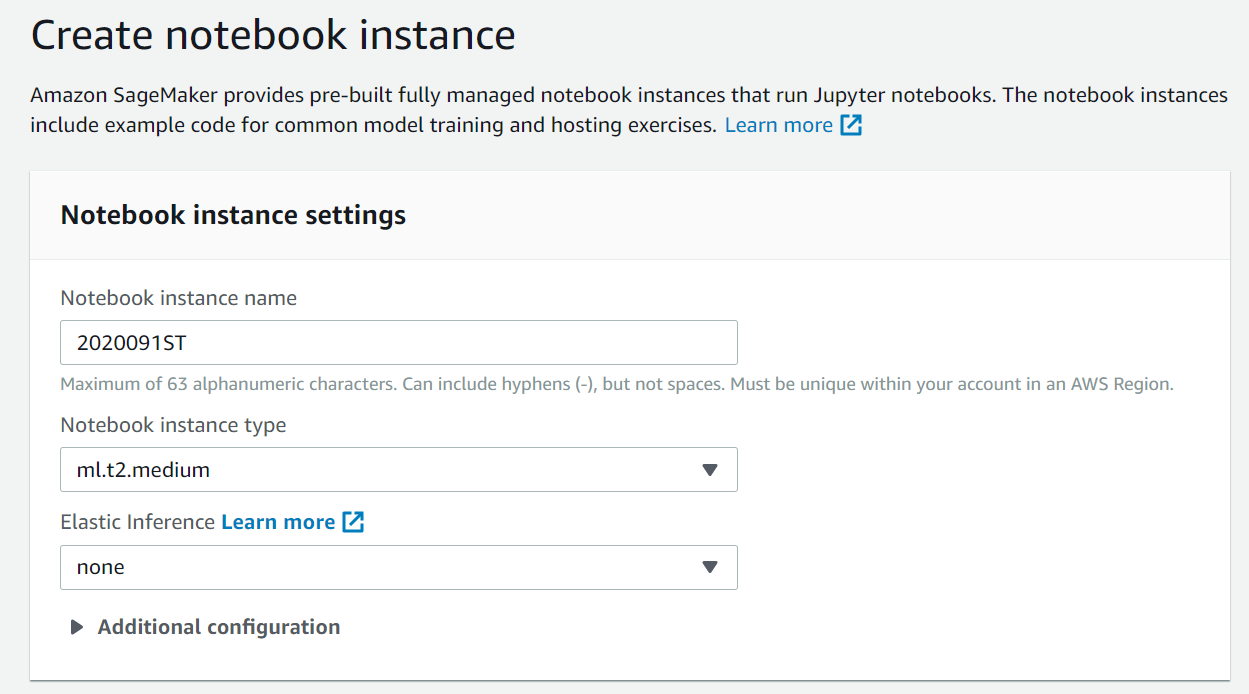
开启Amazon SageMaker ,创建一个实例。系统默认的实例类型是ml.t2.medium,Inference推理的实例可以暂不设置,权限和网络设置部分也可以不作修改。
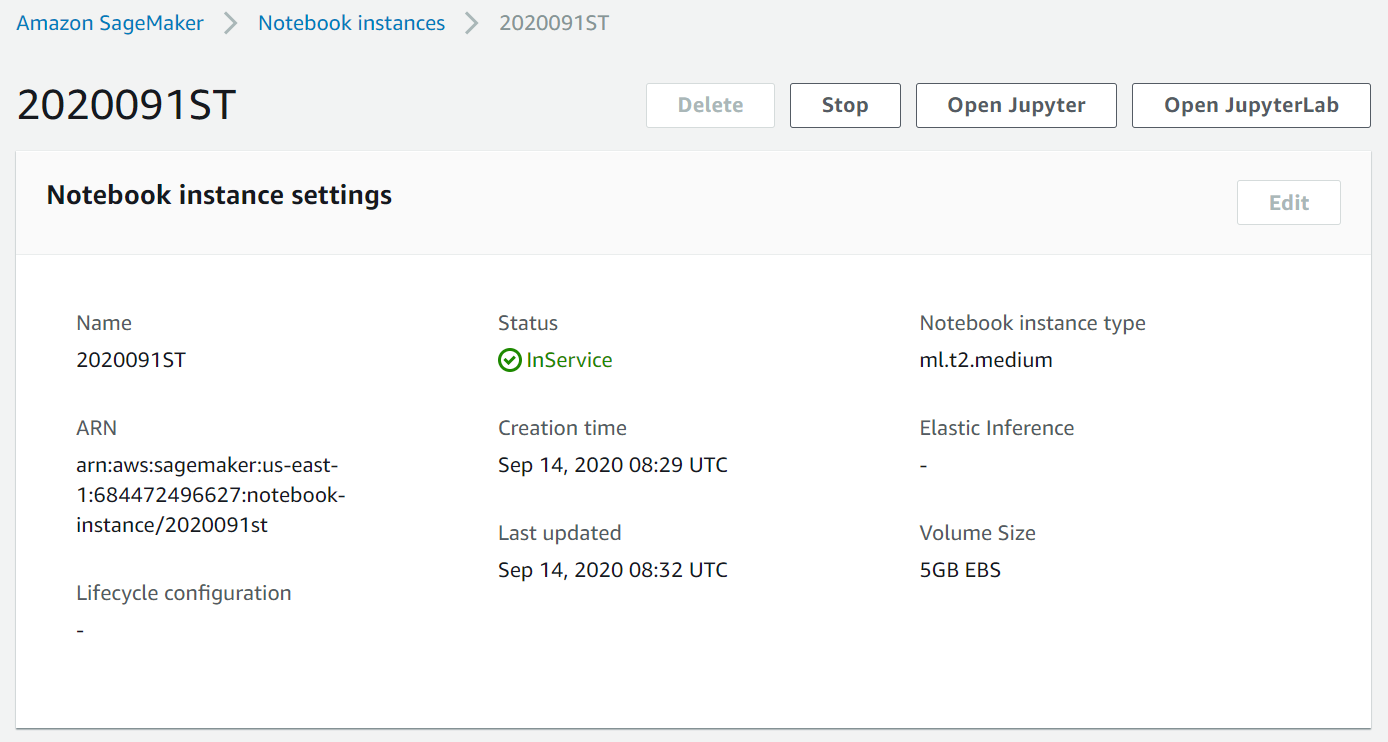
Amazon SageMaker的控制台可以控制实例,停止或者启动,也可以控制各种相关资源。
启动完成后打开Jupyter,可以看到上图。
点击打开JupyterLab,如上图所示。
Amazon SageMaker托管的Jupyter和JupyterLab与本地版本在外观上没太多区别,最大的不同在于,Amazon SageMaker托管的版本多了许多示例代码。
出于演示的目的,我们找一个操作简单,步骤清晰的示例代码,用K-means聚类算法和经典的MNIST数据集训练一个分类模型,识别手写体图片里的数字。
以下是训练过程:
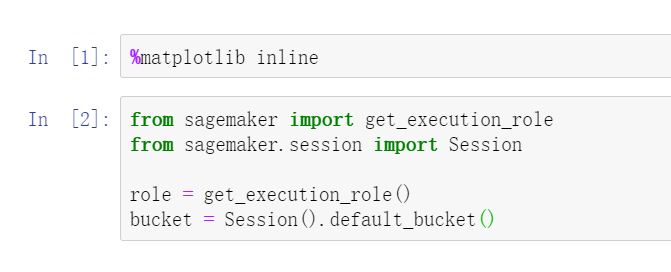
第一步,设置运行环境,赋予必要的权限。值得注意的是,这里引入Amazon SageMaker自己的SDK,简单理解为赋予了notebook使用亚马逊云科技资源的能力,包括各种硬件资源,还有亚马逊云科技内置的一些算法,需要了解这一套SDK才能用的更方便。
第二步骤是导入各种工具包,对用来训练的数据进行初步的探索,这部分与亚马逊云科技资源无关。
图片来源于亚马逊云科技全球网站截图
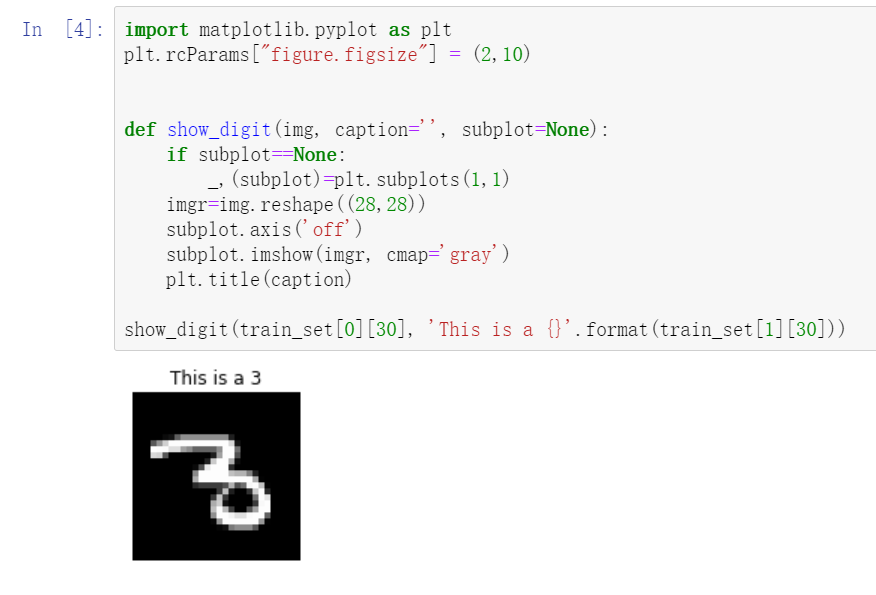
第三步可以查看数据的样子,如上图的MNIST数据集的一张图片,MINIST数据集本身包含70万张28 x 28 像素的手写体图片。
图片来源于亚马逊云科技全球网站截图
第四步,主要是设置训练的参数,包括设置输入数据和输出模型的位置,设置训练所需实例的数量和实例的类型“ml.c4.xlarge”,已知0-9是十个数字,k值就是10,至此,模型构建完毕。
图片来源于亚马逊云科技全球网站截图
第五步,调用.fit函数完成训练,耗时大约4分钟。
图片来源于亚马逊云科技全球网站截图
第六步,将训练好的模型部署在实例上供后续调用模型推理。
第七部分,从验证集数据里选出100个数据,用模型将其分到0-9,一共10个类别里去,分类效果如下图所示。

图片来源于亚马逊云科技全球网站截图
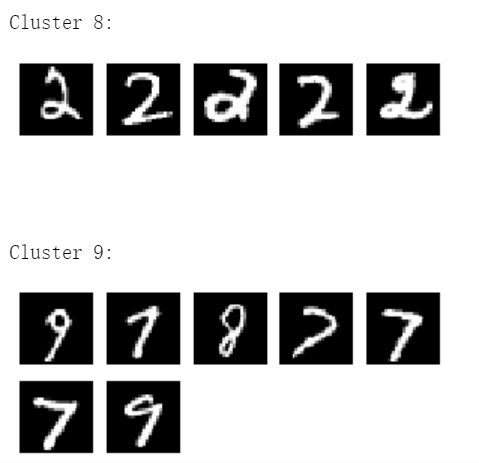
图片来源于亚马逊云科技全球网站截图
可以看到,彼此相似的图片被分到一个类别里。肉眼可见其中是有一定规律的,但许多数字不一样,误差还挺大的。
实际机器学习的训练过程中,需要机器学习专家来不断减小误差,而且,K-means算法在这里其实不是特别合适,作为数据科学家你需要找到合适算法,然后,还需要不断调整超参数,以获取表现最佳的模型。
这个过程其实非常繁琐且复杂,耗时耗力,对于这部分需求,亚马逊云科技的Amazon SageMaker在超参数优化阶段提供了自动化操作,可以以贝叶斯和随机搜索的方式自己调优超参数,这部分内容我们会在下面内容中提到。
其实Amazon SageMaker托管的Jupyter Notebook在本地机器上也完全可以部署,两者的区别在于,亚马逊云科技包装了操作云资源的类库,可以直接调用亚马逊云科技的各种资源。本次实验中,我们直接调用了2个ml.c4.xlarge实例来做训练,训练耗时仅需四分钟,模型部署阶段使用的是ml.m4.xlarge,也完全可以指定规格的实例。
如果是只在本地训练的话,就只能调用本地的资源,无论是多大规模的训练量,都只有有限的资源可以使用,为了应对偶尔的计算量峰值,不得不购买更多资源,于是,在大多数时候忍受较低的资源使用率。浪费就意味着产生了额外成本。

训练完成后的最后一步,记得清理掉部署模型的Endpoint。
这里Amazon SageMaker主要发挥出了云计算本身的优势,计算资源召之即来挥之即去,按照使用量来付费。但这只是简单初步利用了云的特点,云上服务并没有带来太多额外的功能,因为在实际使用中,还有许多麻烦的问题没有解决,比如训练过程反复优化超参数的过程非常费时费力,非常的不人性化,Amazon SageMaker Studio的出现真正就是为了解决此类问题。
2,Amazon SageMaker Studio才真正发挥了云的优势
Amazon SageMaker Studio是一个Web端的IDE工具,跟所有开发工具一样,集成了开发环境,能写代码,能做Debug,能看运行效果。
(1) 便捷的开发环境
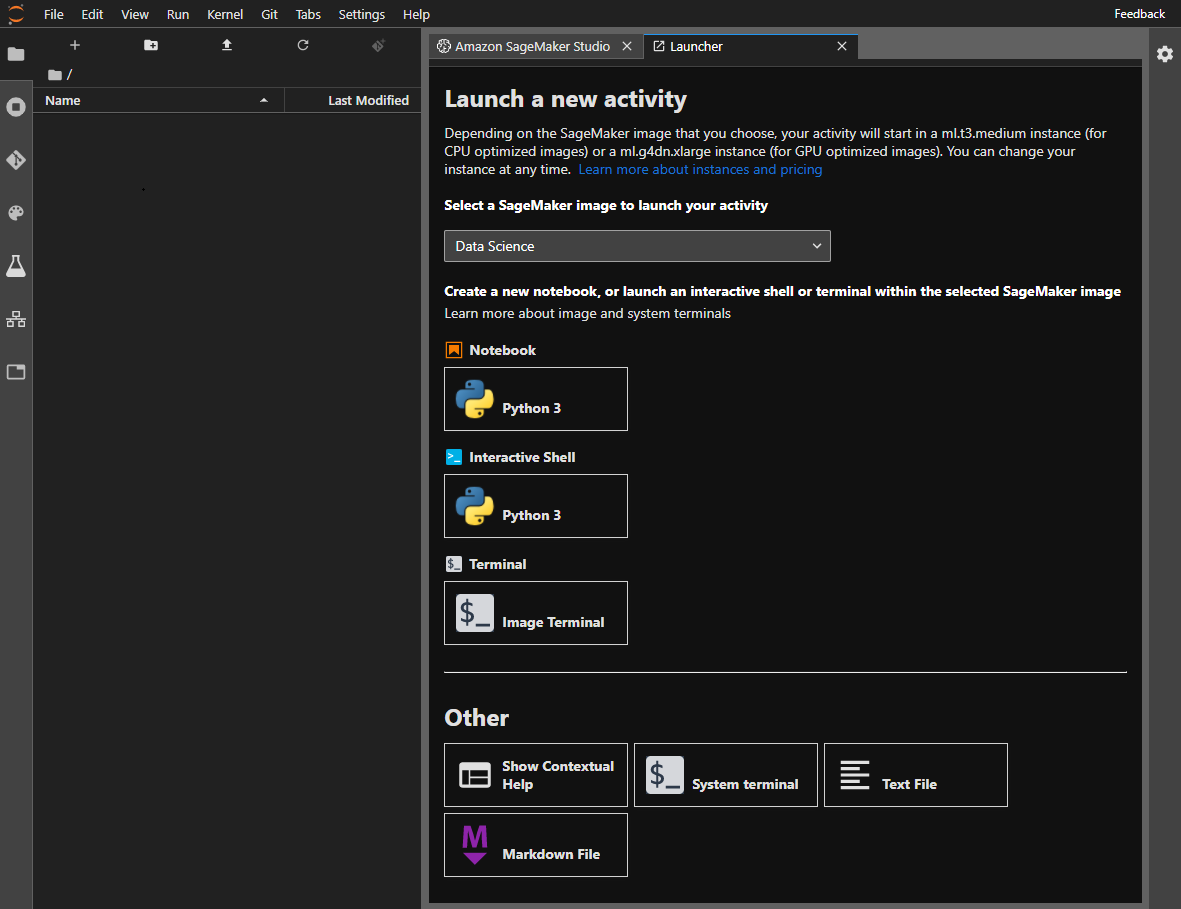
图片来源于亚马逊云科技全球网站截图
创建并运行Amazon SageMaker Studio,上图是Amazon SageMaker Studio的起始界面,与JupyterLab界面相似度很高,不过,亚马逊云科技在这里做了许多改动,加入了亚马逊云科技自有的许多高级操作。
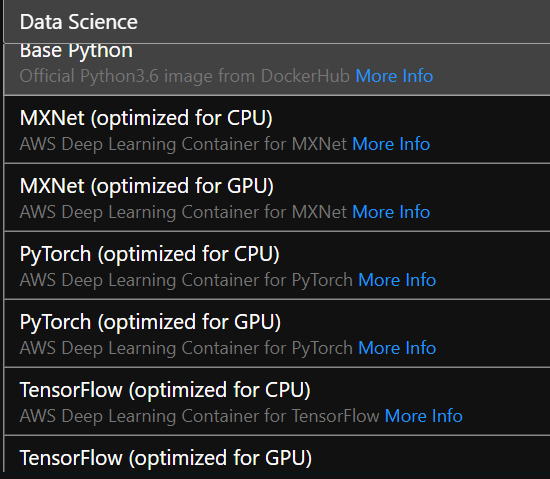
图片来源于亚马逊云科技全球网站截图
比如,在Launcher窗口提供了各种容器镜像可选,有TensorFlow、PyTorch以及MXNet各种常见的机器学习框架可用,这些环境都是配置好的,省去了自己配置的麻烦,除了默认的CPU版本,还有GPU的版本可选。
要知道,在本地自己配置的时候,无论是Windows上还是Linux上,如果想支持GPU的话,都需要一番繁琐的操作,有过亲身经历的人都会有比较深入的印象的,现在TensorFlow GPU版本可以以容器方式部署了,但也只支持在Linux上操作。
图片来源于亚马逊云科技全球网站截图
本地Jupyter Notebook切换Kernel的操作
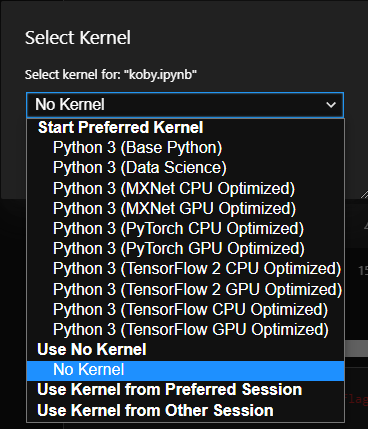
图片来源于亚马逊云科技全球网站截图
这里镜像的概念在Jupyter Notebook的上下文里,其实是一个个单独的Jupyter Kernel,可以随时进行切换,这里的镜像也都是随时可以切换的。跟标准版本Jupyter Notebook里切换Kernel是一个概念。
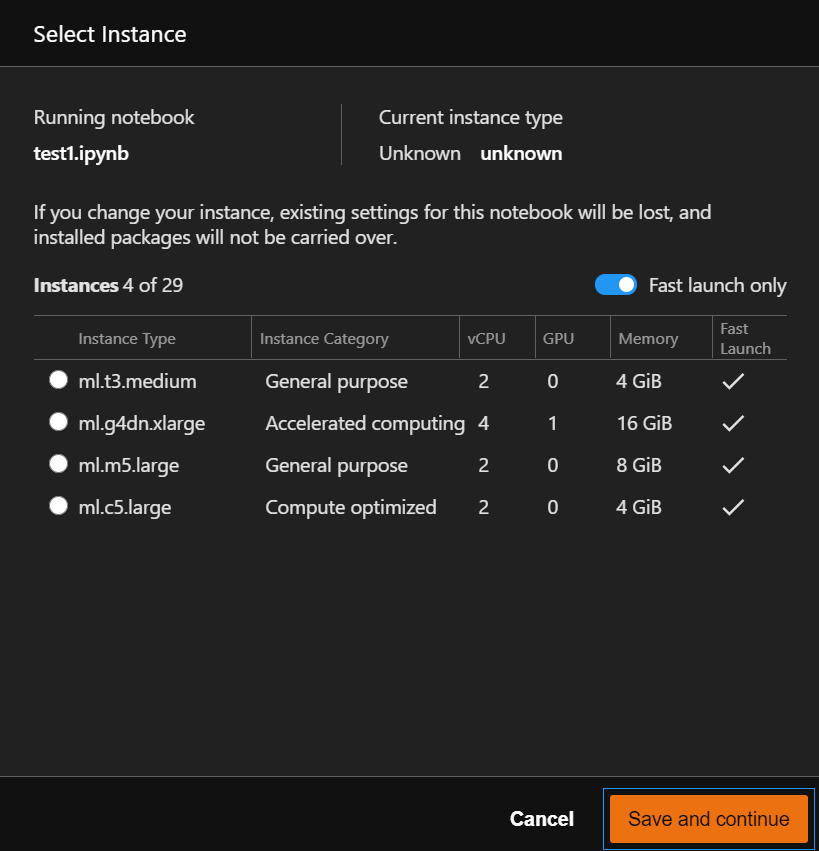
Amazon SageMaker Studio不仅可以随时切换Kernel,还可以随时修改主机配置,如上图所示,列出的四个是支持快速切换的主机,另外还有25个主机配置的启动速度稍慢。本地原生的Jupyter不支持这一操作,这是Amazon SageMaker Studio独有的优势。
每次新打开一个Notebook的时候,都需要单独配置Kernel和主机,当不需要的时候,可以随时shut down,也就不再计费了,也就是我们所说的召之即来挥之即去。
至此,我们的开发环境就准备好了。
(2)训练过程的记录和回溯——Experiments
Amazon SageMaker Studio最突出的能力是能解决机器学习过程中许多繁琐的问题,我们接下来通过一系列操作介绍这些新的功能。
我们通过创建一个AutoML实验来看:
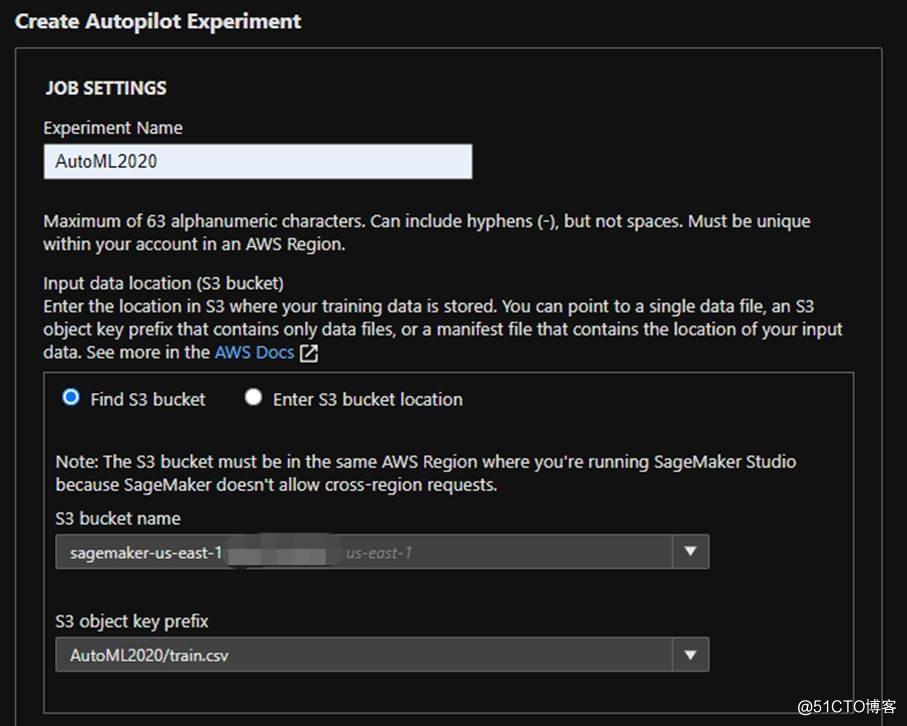
图片来源于亚马逊云科技全球网站截图
将准备好的训练数据传到s3上,选择Bucket的名字,还有文件train.csv。这里使用的训练数据从Kaggle上下载来的,是泰坦尼克乘客救援情况数据。
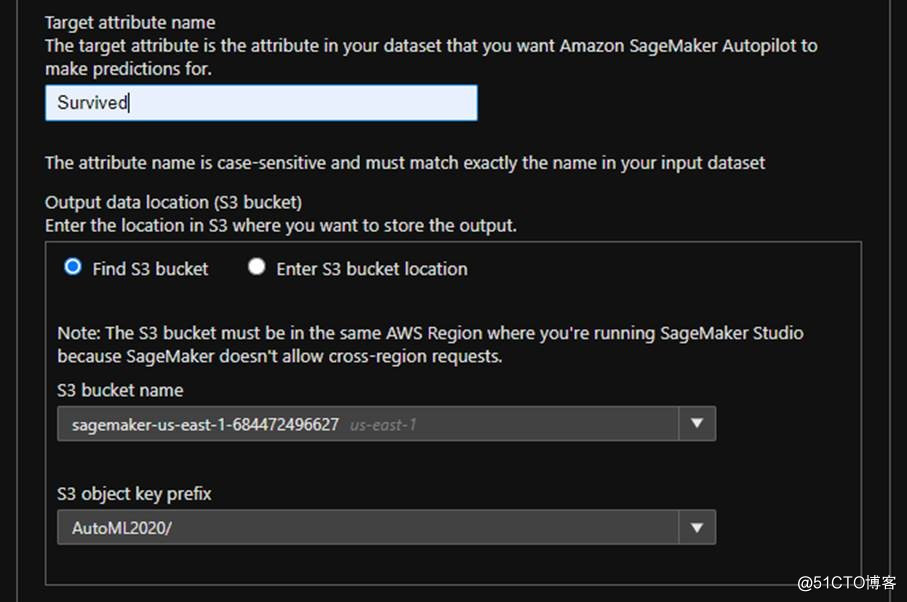
图片来源于亚马逊云科技全球网站截图
然后,选择要预测的参数是哪一列,这里选择的是Survived,就是看一个人是否获救了。
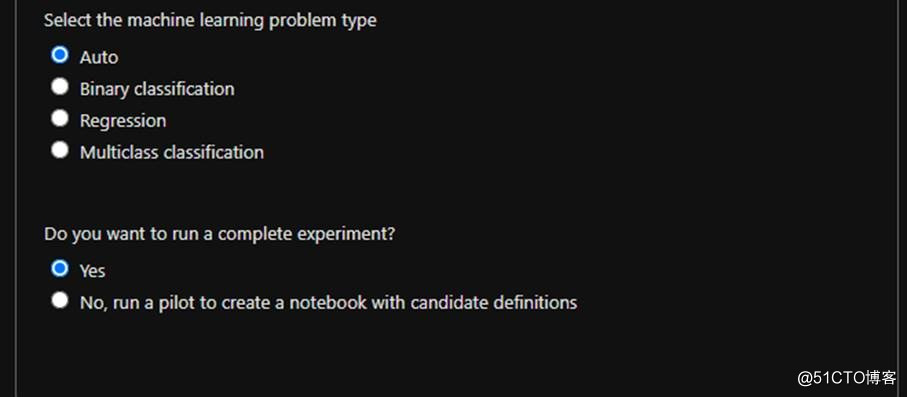
图片来源于亚马逊云科技全球网站截图
然后选择我们要处理的是什么问题,而不用选择具体的算法,可以指出是分类还是回归,是二分类还是多分类任务,是否需要一个完整的实验,默认选项即可,最后点击创建,自动化的机器学习就开始了。
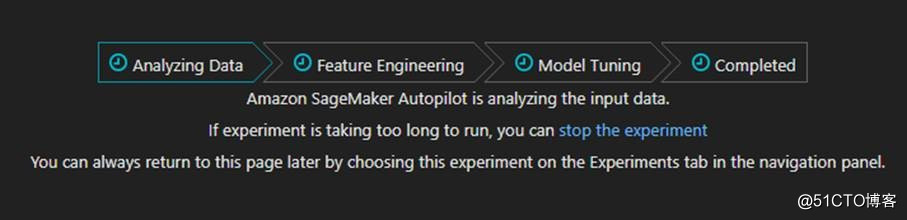
图片来源于亚马逊云科技全球网站截图
从分析数据开始,然后进入特征提取工程阶段,模型调优阶段,最后就完成了,过程耗时较长,需要亚马逊云科技自己的机器学习平台来完成的所有操作,比如,训练数据集、验证数据集、还有测试数据及的划分,算法的选择,超参数的优化等等,所有操作交给亚马逊云科技来完成。
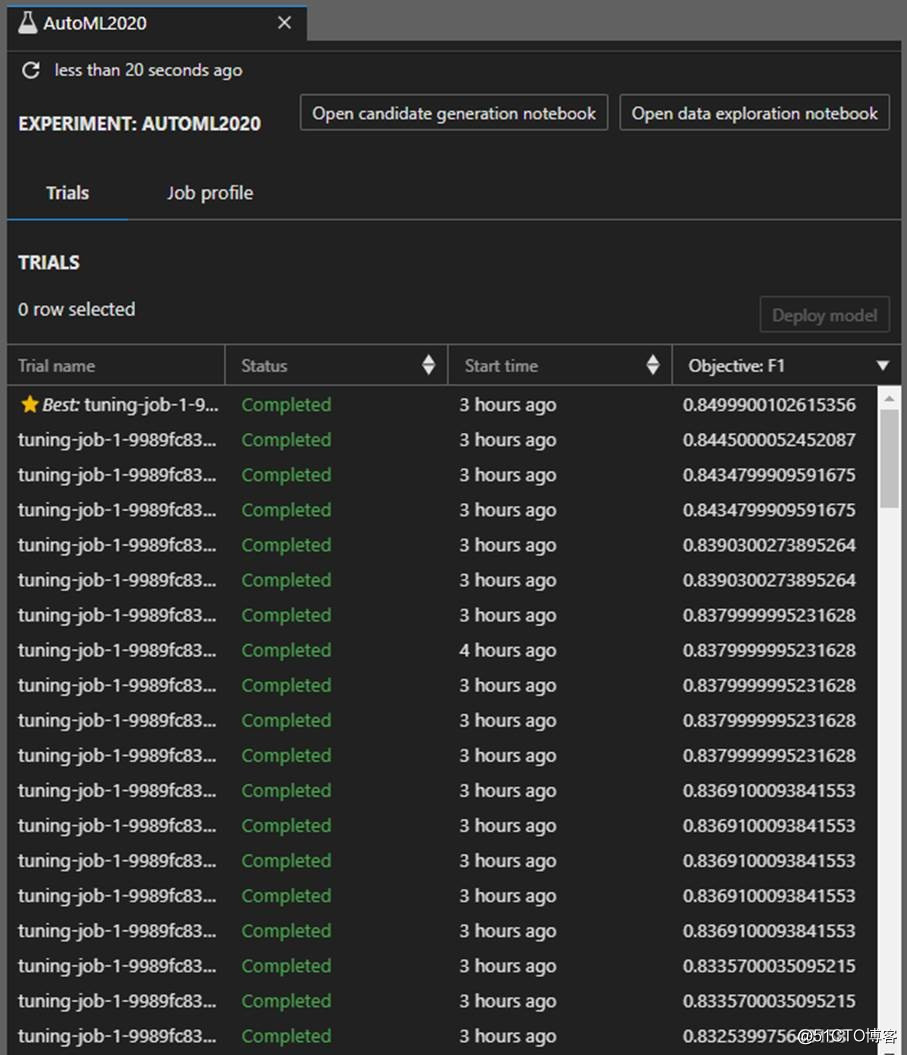
图片来源于亚马逊云科技全球网站截图
经过一个小时,经过数不清多少次的尝试后,系统能找到表现最好的那次尝试(如上图星标所示),上图只展示了二十来个Tuning job(可译作调优负载),每个Tuning job对应一个训练出来的模型。
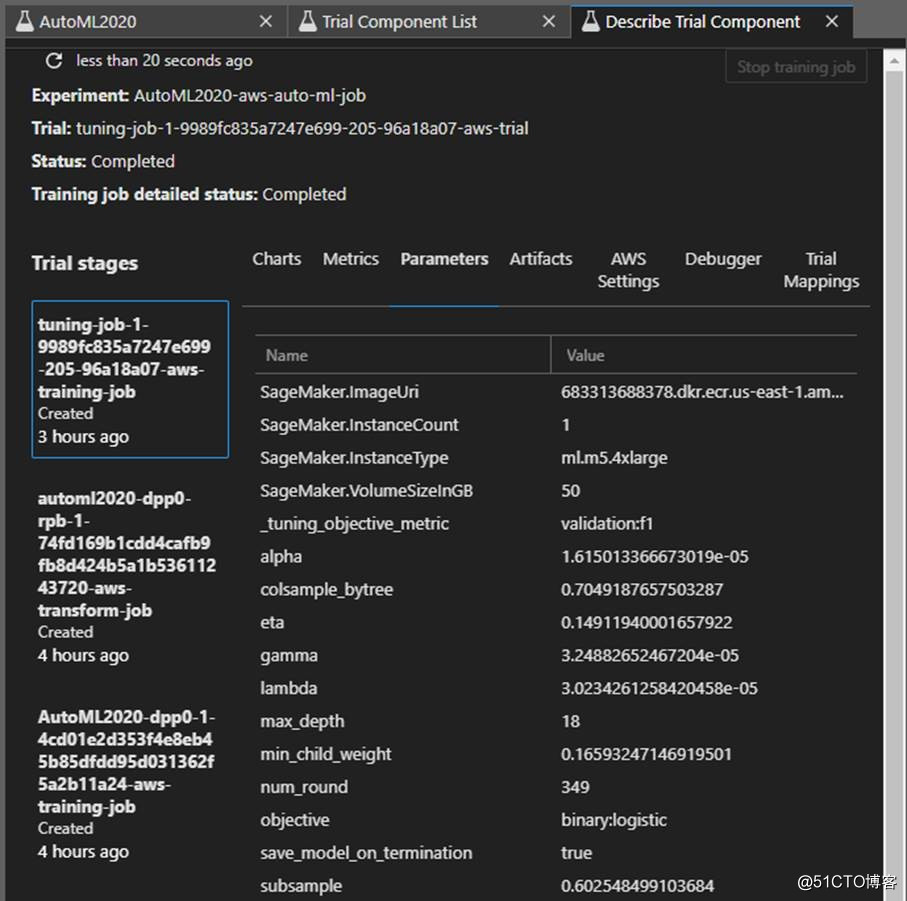
图片来源于亚马逊云科技全球网站截图
整个训练过程都有记录,如上图所示,可以查看某次实验尝试使用的一些参数,看到更多关于训练过程,训练模型相关的更多细节。
这些尝试都是自动进行的,而在实际训练当中,可能会有数不清次数的尝试,手动记录不太现实,而且容易错乱,SageMaker Experiments可以随时记录和查看这些过程。
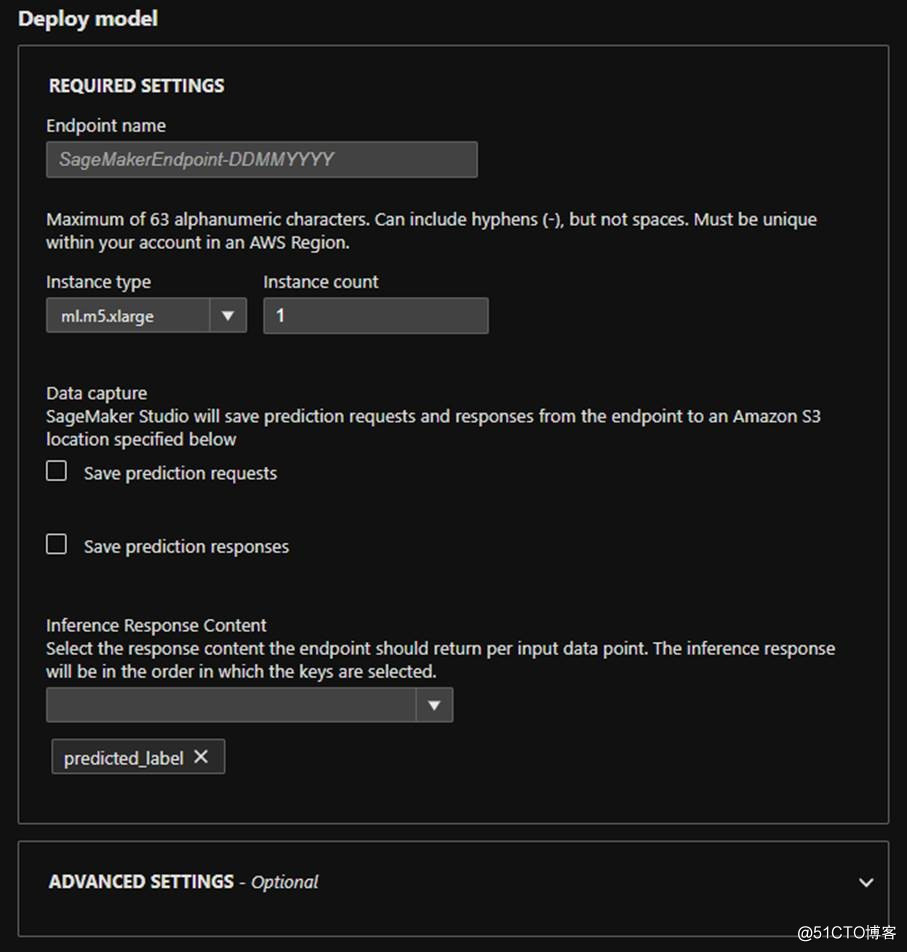
图片来源于亚马逊云科技全球网站截图
找到最满意的那次尝试后,可以通过一些简单的设置完成最后的部署。
(3)自动化的超参数调优Hyperparameter Tuning与自动化的机器学习 Autopilot
图片来源于亚马逊云科技全球网站截图
上文提到了超参数优化(hyperparameter tuning job)的操作,其实在Amazon SageMaker的控制台窗口也可以自己创建自动化的超参数优化负载,如上图,我们刚才自动化的机器学习过程中也会创建这样的任务。
可见,自动化机器学习的部分工作任务也是靠自动化的超参数优化。不过,自动化机器学习更高级一些,还会自动挑选算法,会自行设定超参数优化的一些参数。当手动创建超参数优化负载的时候,这些都需要机器学习专家自己手动设置。
图片来源于亚马逊云科技全球网站截图
创建超参数优化负载的关键是选择算法,可以用Amazon SageMaker自带的算法,也可以用自己创建的算法。
图片来源于亚马逊云科技全球网站截图
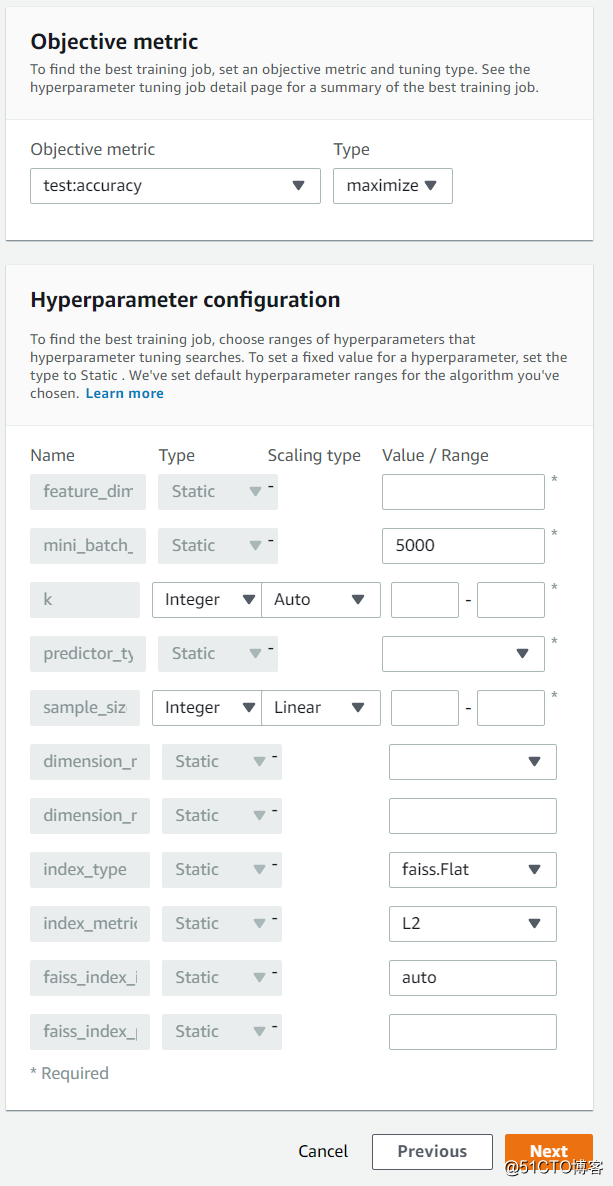
配置算法对应的超参数,设定待优化的目标值,这里设置的是准确度。
Amazon SageMaker的超参数优化功能自动调参,省去人力手工操作的麻烦,而且能同时启用多个训练任务来节省时间,还能设置使用Spot实例来节省费用。
图片来源于亚马逊云科技全球网站截图
任务完成后,可以得到配置好的一组超参数组合,用于后续的训练。
(4)训练阶段的Debugger
自动化的机器学习虽然很方便,但由于支持场景相对有限,而且,训练过程相对不那么透明,因此虽然SageMaker Experiments能记录训练的过程固然有帮助,但大多数时候还是需要手写代码来完成训练过程的。
Amazon SageMaker Studio可以Debug模型训练过程,一直以来,机器学习的训练过程可见度都很低,基本处于黑盒状态,常见的只能看见loss和accuracy值,其他部分的能见度比较低。
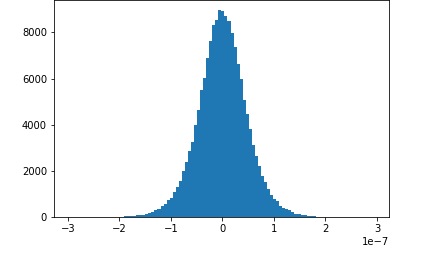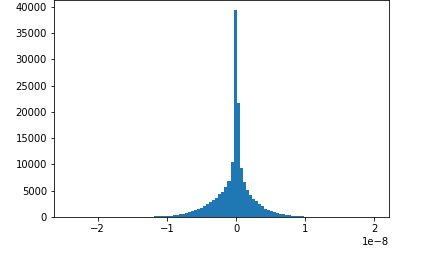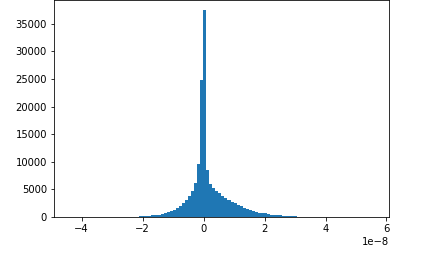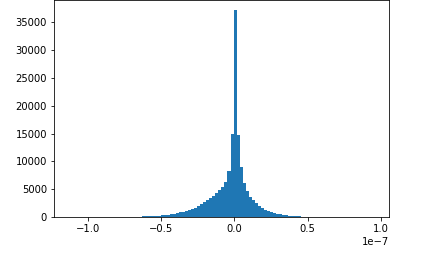
图片来源于亚马逊云科技全球网站截图
在训练阶段,使用Amazon SageMaker SDK还可以监控模型的训练过程,比如上图中显示的是在训练过程中卷积层的梯度分布,开始是高斯分布,但后来梯度的范围越来越小,这时候就需要修改超参数了,如果能在训练的时候就发现这一问题,就不用等到训练完成后再修改了。
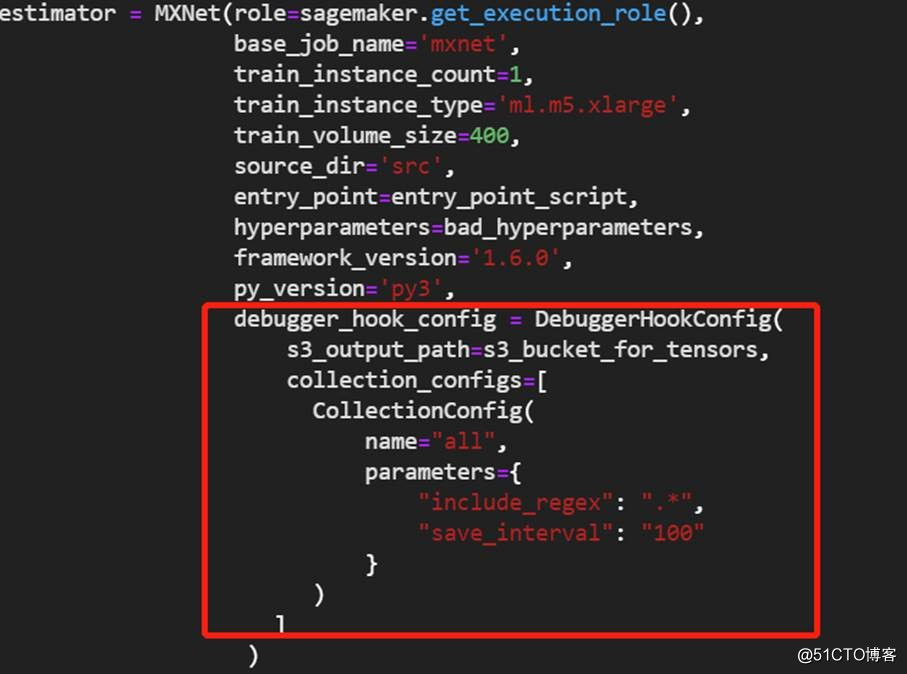
图片来源于亚马逊云科技全球网站截图
SageMaker Debugger工具使用起来其实也比较简单,如上图所示,在实际代码中,设置estimator的时候,需要多添加几个配置参数即可获取到训练时候的一些Tensor数据,获取数据后就可以进行一些展示。
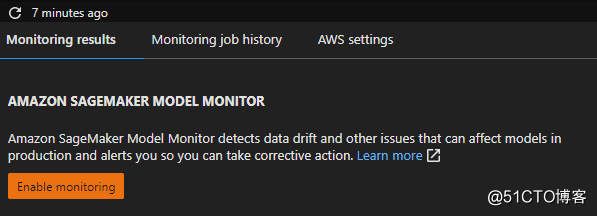
(5)监控模型运行效果
图片来源于亚马逊云科技全球网站截图
在实际生产过程中,部署并不是最后一个环节,而只是许多工作的开始,Amazon SageMaker可以提供线上模型监控能力,监控模型运行的状况,如果数据发生变化,导致模型适用性有偏差,则需要重新训练,这在亚马逊云科技上可以通过构建Pipeline来实现。
(6)分享协作
图片来源于亚马逊云科技全球网站截图
机器学习的过程难免会有些问题,把账号分享给别人也不太现实,为了便于分享协作,Amazon SageMaker Studio在每个Notebook的右上角都添加了分享按钮。
图片来源于亚马逊云科技全球网站截图
在创建Amazon SageMaker Studio的时候需要设置domain,在同一个domain下的用户可以共享协作,比如在公司内部跟同事做分享,接受分享的用户看到的所有内容与分享者看到的是完全一样的,便于协作共享,无需额外配置,这点是本地机器学习环境中绝对做不到的。
(7)资源控制
Amazon SageMaker所有的资源都可以在控制台看到并进行管理,如果只是实验阶段的话,建议在尝试之后关掉相关资源来管理成本,在生产环境中,可以清楚看到各种资源的用量并进行管理,使得整体成本更容易控制。
四、总结评估
Amazon SageMaker上可以完成全流程的训练,我们也可以将原有的模型部署到Amazon SageMaker的endpoint服务器上,如果也不想自己训练模型,可以直接用亚马逊云科技以SaaS方式提供的AI能力,还可以在Marketplace上拿别人模型来用。
Amazon SageMaker侧重的是训练、调优和部署阶段的能力,可以降本增效。一方面,Amazon SageMaker可以使用Spot Instance来降低成本;另一方面,如果只想在云上部署模型,也可以直接使用Elastic Inference降低模型部署后的推理成本。而在效率提升方面,Amazon SageMaker Experiments、自动化的机器学习能力、还有各种规格的云上资源等,都能提升效率。
最后需要说明的是,亚马逊云科技的云上人工智能/机器学习栈是一个完整的系列,上中下一共由三个层次构成。本次评估中谈到的Amazon SageMaker只是中间一层的“机器学习服务层”。在其之下的底层,提供的是对各类框架的支持、对CPU/GPU的弹性支持等基础算力方面的服务。

图片来源于亚马逊云科技全球网站截图
比如用户单纯想将本地的训练搬到云上,也可以不使用完全托管的Amazon SageMaker而可以用EC2以及一个支持TensorFlow、PyTorch,MXNET的Linux镜像(虽然这可能给后续机器学习的开发带来更多额外工作)。
在中间层SageMaker之上的,是“AI服务层”,提供了许多易用的AI服务,比如用于图像及视频分析的Amazon Rekognition, 用于文档内容识别的OCR工具Amazon Traxtract, 用于翻译的Amazon Translate, 用于文字转语音的Amazon Polly, 用于金融反欺诈的Amazon Fraud Detection, 用于码农优化代码的Amazon CodeGuru……, 等等。
这些应用导向的AI服务的提供,极大方便了AI在各类企业应用中的推广。(具体可参考https://amazonaws-china.com/cn/machine-learning/ai-services/ )