本文排查一个Linux 机器 CPU 毛刺问题,排查过程中不变更进程状态、也不会影响线上服务,最后还对 CPU 毛刺带来的风险进行了分析和验证。
本文中提到 CPU 统计和产生 core 文件的工具详见 simple-perf-tools 仓库。
问题描述
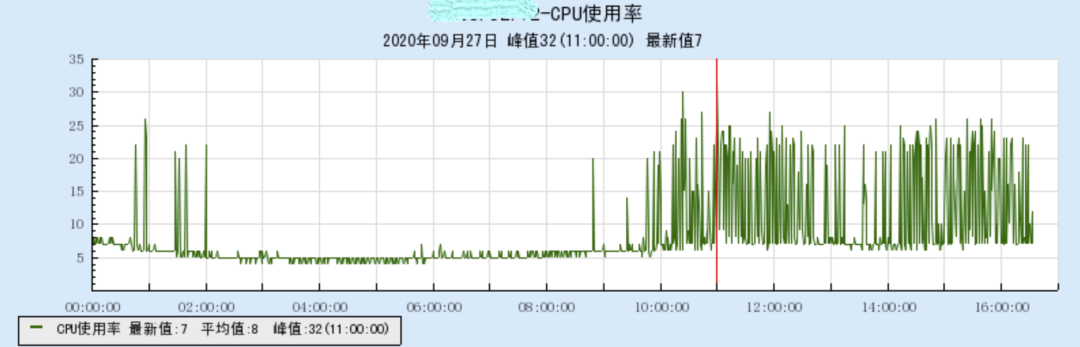
某服务所在机器统计显示,其 CPU 使用率在高峰时段出现毛刺。
暂时未收服务调用方的不良反馈。
初步排查
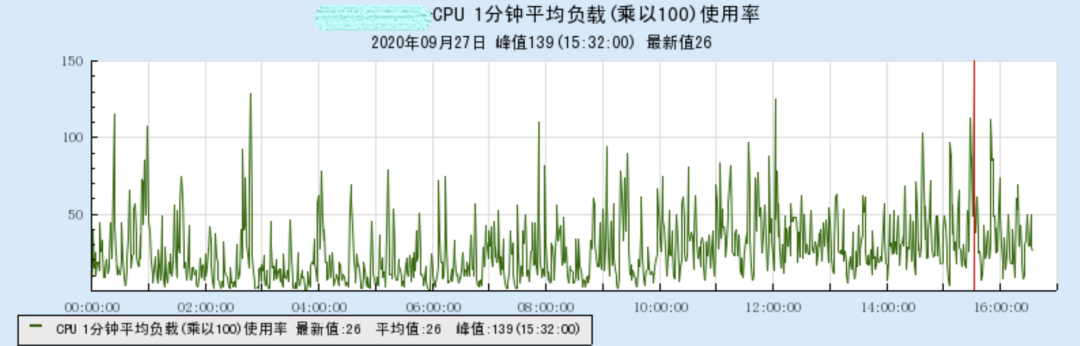
查看 CPU 1 分钟平均负载,发现 1 分钟平均负载有高有低,波动明显。说明机器上有些进程使用 CPU 波动很大。
登录机器排查进程,使用top指令。因为 CPU 会明显上升,重点怀疑使用 CPU 总时间高的进程,在打开 top 后,使用shift +t可以按照 CPU TIME 进行排序。
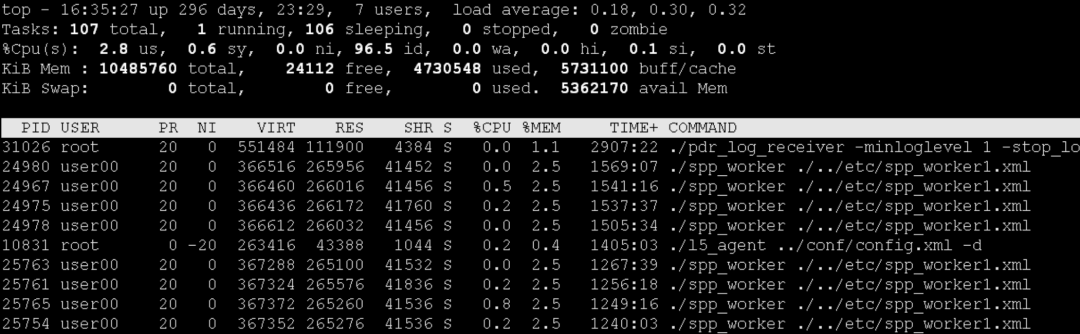
直观的看,有几个 spp_worker 相关的进程使用 CPU TIME 相对较高。
第一个进程因为启动的时间比较长,所以 CPU TIME 也比较大。可以使用下面的脚本,计算各个进程从各自拉起后 CPU 使用率:
- uptime=`awk '{print $1}' /proc/uptime` # why is it too slow indocker?
- hertz=`zcat /proc/config.gz | grep CONFIG_HZ= |awk -F"=" '{print $2}'`
- awk -v uptime=$uptime -v hertz=$hertz -- '{printf("%d\t%s\t%11.3f\n", $1, $2, (100 *($14 + $15) / (hertz * uptime - $22)));}' /proc/*/stat 2> /dev/null | sort -gr -k +3 | head -n 20
看到的也是这些 spp_worker 使用 CPU 相对要高一些:
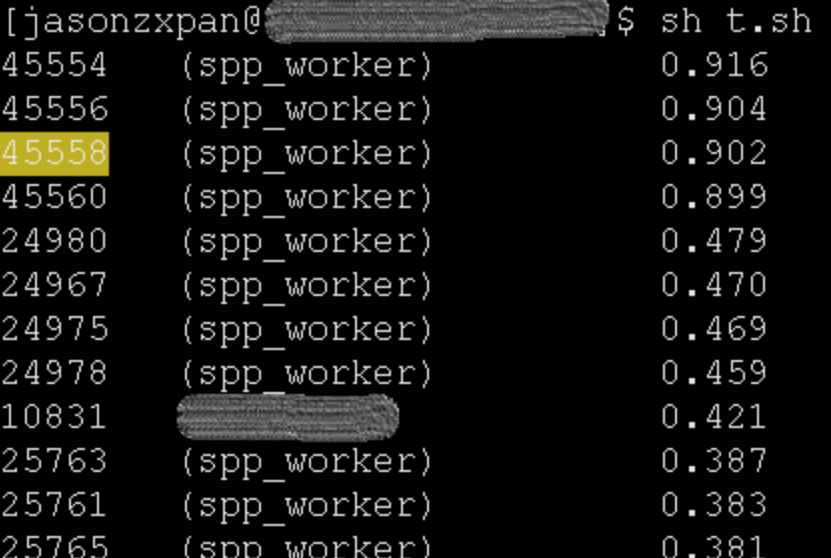
选其中的一个 PID 为 45558 的 Worker 进程监控器 CPU 使用率:
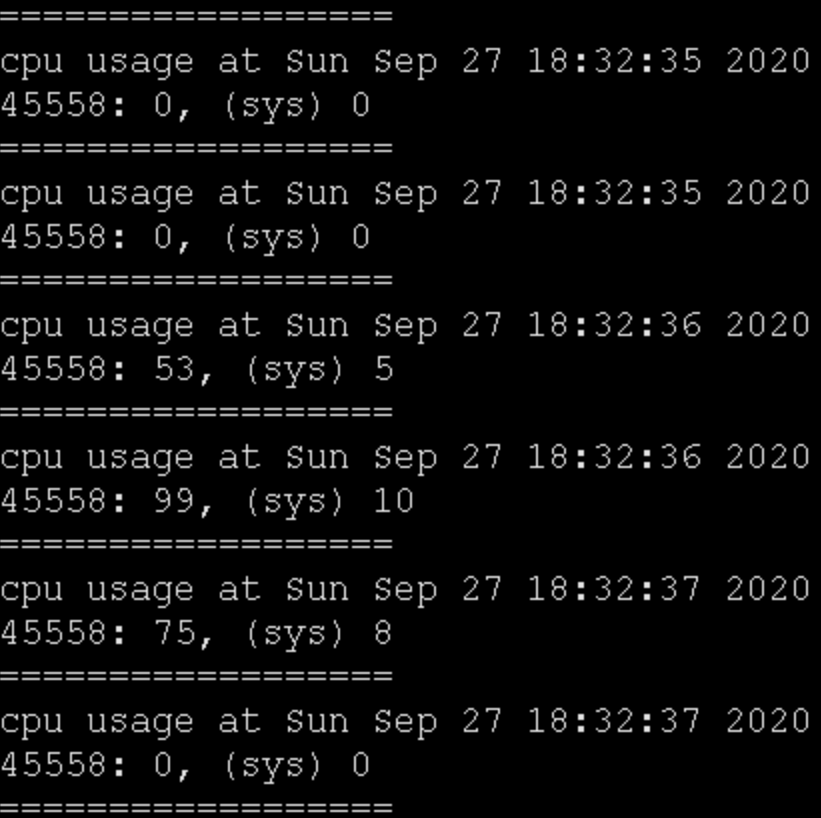
可以发现其 CPU 大部分情况很低,但是在某一个时间点会升高,持续 1 秒左右。而且大部分时间是耗费在用户态,而非系统调用。
而《Linux Agent 采集项说明 - CPU 使用率》中描述的 CPU 使用率的采样策略为:
Linux Agent 每分钟会采集 4 次 15 秒内的 CPU 平均使用率。为了避免漏采集 CPU 峰值,网管 Agent 取这一分钟内四次采集的最大值上报。
因为采样可能采到高点或者低点,当 1 分钟内出现 CPU 飙升,则会表现为尖峰;如果四次都没有出现飙升,则表现为低谷。
至此,已经能确认是这批 Worker 进程引起了这种毛刺,但具体是哪部分代码有问题还需要进一步排查。
进一步排查
前边确认了没有太多的系统调用,所以不必使用strace工具。
使用perf工具
使用perf工具进行查看。具体的命令是perf top -p 45558,在低 CPU 使用率的时候:
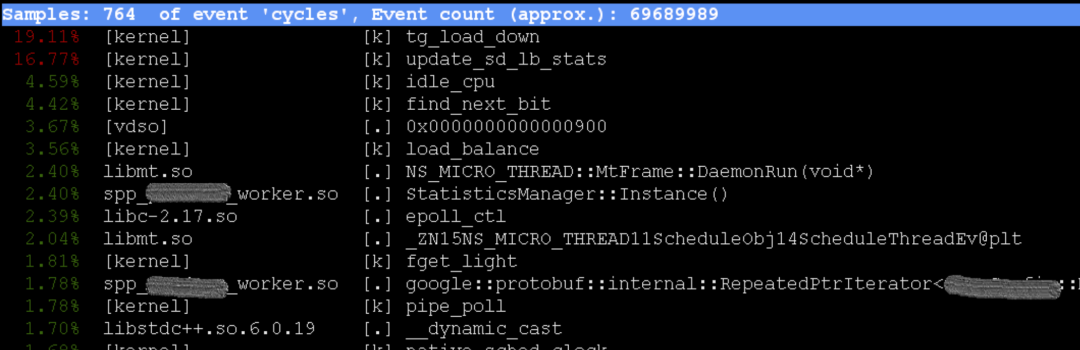
但是当 CPU 飚上去的时候,perf采样的位置变成如下这样:
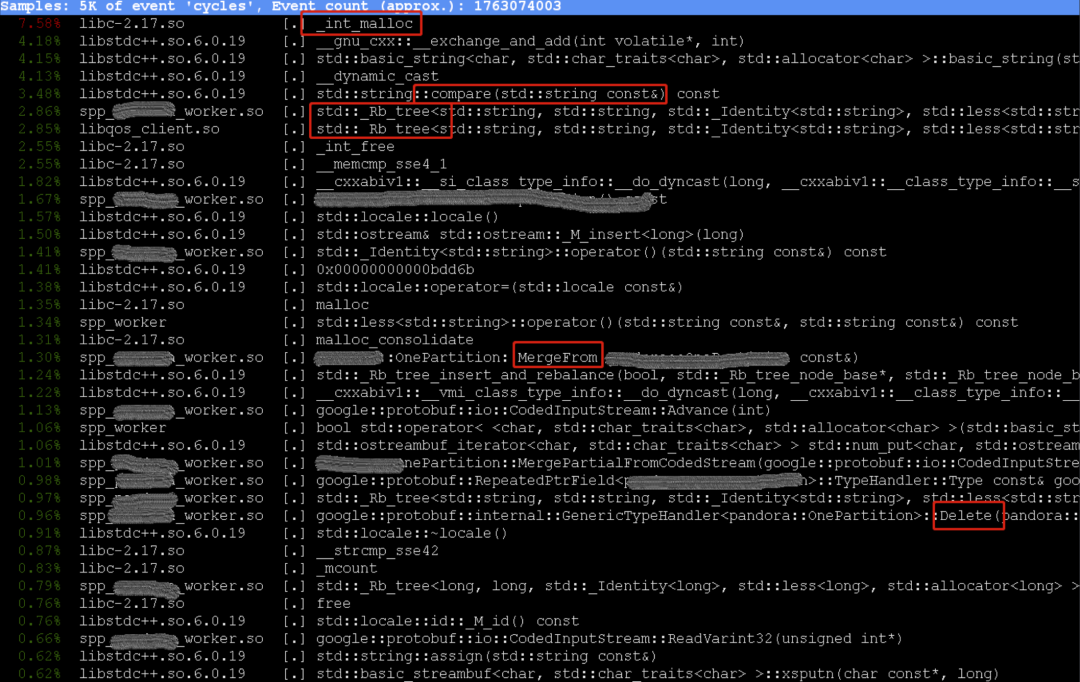
看一下红框的位置,可以发现可能是配置更新部分有问题,因为:
- 这个地方 Protobuf 特别多的地方,在做更新的操作(有MergeFrom,有Delete)
- 有大量的用到了std::map(有std::_Rb_tree,有字符串比较)
通过观察perf结果的方法,虽然能够猜测大计算量的位置,但是有两个不便之处:
- 如果 CPU 高的情况发生概率很低,人为观察比较耗时
- 不能明确的知道,具体在哪个文件的哪个函数
使用gcore
最初统计的时候,发现 CPU 高的情况会出现 1 秒多的时间,如果发现 CPU 高负载时,直接调用gcore {pid}的命令,可以保留堆栈信息,明确具体高负载的位置。
将使用 gcore 的指令,添加到统计工具中取,设置 CPU 上门先触发。
通过gdb看了几个 coredump 文件,发现堆栈和函数调用基本一致。可以明确的看到,大量的耗时发生在了AddActInfoV3这一函数中:
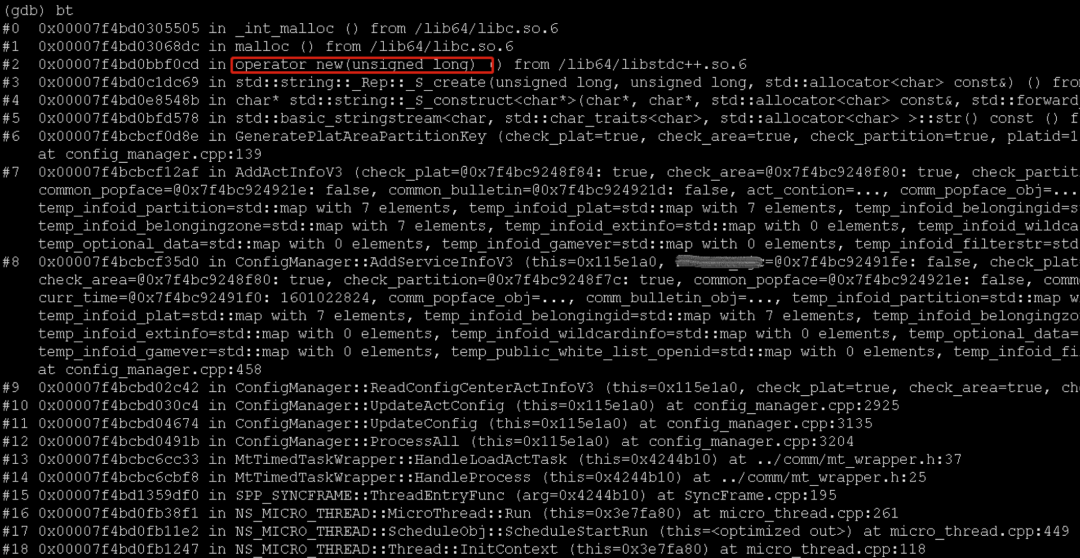
到此位置,我们明确了高计算量发生的具体位置。
风险点
CPU 突然飙升是否存在风险呢?是不是计算资源充足的时候,就不会有问题呢?
这个例子中,使用的是 SPP 微线程功能,每个 Worker 进程只启用一个线程。

如果仅仅是因为高计算量卡住 CPU,正常处理请求的逻辑将很难被调度到。这样势必会造成处理请求的延迟增大,甚至有超时返回的风险。
使用 spp 的cost_stat_tool工具
利用 spp 自带的统计工具印证这一风险点,查看 worker 处理前端请求时延统计信息,执行命令./cost_stat_tool -r 1:
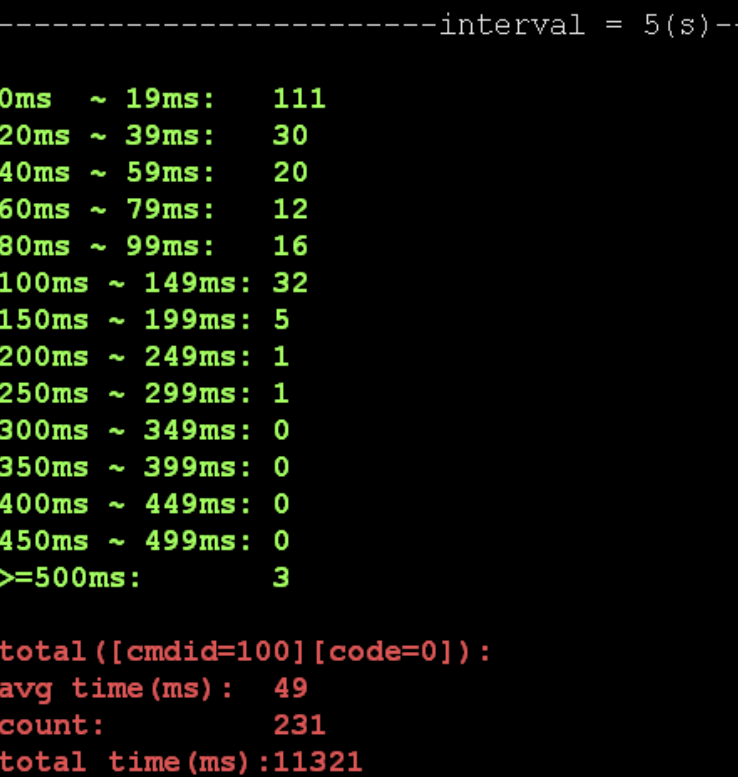
上边的例子中,统计发生配置更新前后的 5 秒钟内,worker 处理的 231 个请求中,有 3 个请求的处理时间超过 500ms,远高于普通请求。
使用tcpdump抓包确认
因该服务没有打开详细的日志,想要进一步验证超过 500ms 的这些请求也是正常处理的请求,而非异常请求,可以通过抓包来分析。
- tcpdump -i any tcp port 20391 -Xs0 -c 5000 -w service_spp.pcap
通过 wireshark 打开,需要过滤出返回时间 - 请求时间 > 500ms的相关请求。翻译成 wireshark 过滤器的表达式则是:
- tcp.time_delta > 0.5 && tcp.dstport != 20391
过滤出一条符合条件的请求:

在该条记录上右键 -> Follow -> TCP Stream,可以查看该请求前后的 IP 包:

上边 4 个包分别是:
- +0ms 客户端发送请求至服务端
- +38ms 服务端回复 ACK,无数据
- +661ms 服务端发送返回至客户端
- +662ms 客户端回复 ACK
详细看了包中的内容为一条普通请求,逻辑简单,应该在 20ms 内返回。而此时的该进程使用 CPU 也确实为高负载的情况:
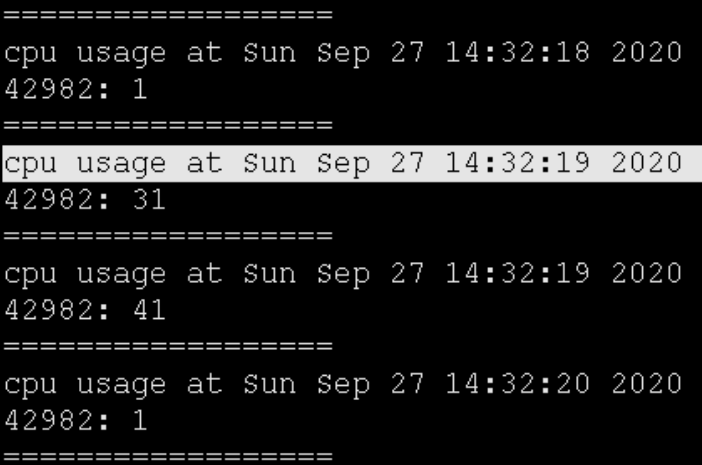
上述统计相互印证:
- CPU 高时,正常的网络请求也会被阻塞住(回复 ACK 需要 38ms,低于 40ms,与TCP 延迟确认无关)
- 平时只需要 20ms 能返回的请求,耗时了 660ms
CPU 突然飚高有风险,需要认真对待。