在过去的十年中,强化学习(RL)成为机器学习中最受瞩目的研究领域之一,应用RL能够很好地解决芯片放置和资源管理等复杂的问题,以及Go/Dota 2/hide-and-seek等有挑战性的游戏。简单来说,RL基础架构就是数据采集和训练的循环,Actor根据环境收集样本数据,然后将其传输给Learner来训练和更新模型。当前大多数RL实现都需要对环境中成千上万个样本进行多次迭代,以学习目标任务,如Dota 2每2秒要学习成千上万帧样本。这样,RL架构不仅要有很强的数据处理能力,例如增加Actor实现大量样本的采集,而且还应能够在训练过程中快速迭代这些样本。
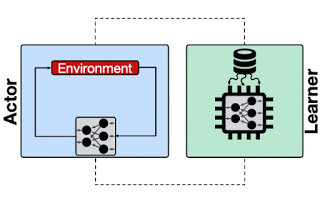
Actor与Learner交互的RL架构。Learner使用采样数据训练模型,并将更新后的模型传递给Actor(例如TF-Agents,IMPALA)。
今天,我们要介绍的是Menger——一种具有本地化推理能力的大规模分布式RL架构,可通过多个处理集群(如Borg单元)扩展数千个Actors,从而减少了芯片放置任务的训练时间。在接下来的章节,我们介绍了如何使用Google TPU配置Menger,从而提高训练速度,进一步我们通过芯片放置任务验证框架的性能和可扩展性。可以发现,与基准模型相比,Menger将培训时间减少了8.6倍。
Menger设计思路
当前有各种各样的分布式RL系统,如Acme和SEED RL,然而,这些系统往往只从一个特定角度对分布式强化学习系统进行优化。例如,Acme从频繁的Learner获取模型,使每个Actor都进行本地推理,而SEED RL则通过分配一部分TPU内核执行批量调用,进行集中推理。对通信成本和推理成本的衡量是不同优化系统的区别,具体包括:(1)向/从集中式推理服务器发送/接收观察和动作的通信成本,或从Larner获取模型的通信成本;(2)相比加速器(TPU/GPU)成本,Actor的推理成本大小。考虑到观察值、动作和模型大小等目标程序要求,Menger使用类似Acme的局部推理,但同时尽可能的增加Actor的可扩展性。要实现良好扩展性和训练速度,主要挑战包括以下两点:
Actor向Learner进行大量读取请求以进行模型检索,这就造成Learner的负担,随着Actor数量的增加模型表现明显受限(如收敛时间的显著增长)。
在将训练数据输送给TPU计算核心时,TPU性能通常受到输入管道效率的限制。随着TPU计算核心数量的增加(如TPU Pod),输入管道的性能对于训练时间的影响更加明显。
高效的模型检索
为应对第一个挑战,在TensorFlow代码中,我们在Learner和Actor之间引入了透明的分布式缓存组件,并通过Reverb进行优化(类似于Dota中使用的方法)。缓存组件的主要职责是对Actor的大量请求和Learner的处理能力进行平衡。通过添加这些缓存组件,不仅显着减轻了过多请求对Learner的压力,而且以少量的通信成本将Actor分配给多个Borg单元。我们的研究表明,对有512个Actors、大小为16MB的模型,引入缓存组件可以将平均读取延迟降低约4.0倍,从而实现更快的训练迭代,在PPO等策略算法中效果更加明显。
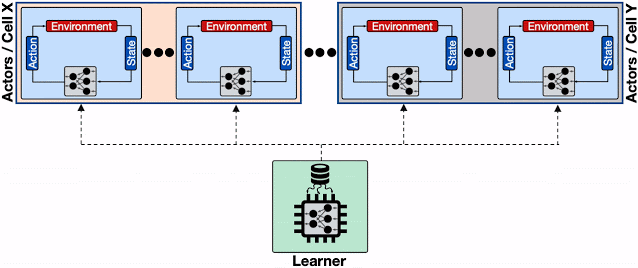
若干Actors放置在不同Borg单元的分布式RL系统。 不同Borg单元大量Actors的频繁的模型更新请求限制了Learner性能以及Learner于Actor之间的通信网络,从而导致总体收敛时间显着增加。虚线表示不同机器之间的gRPC通信。
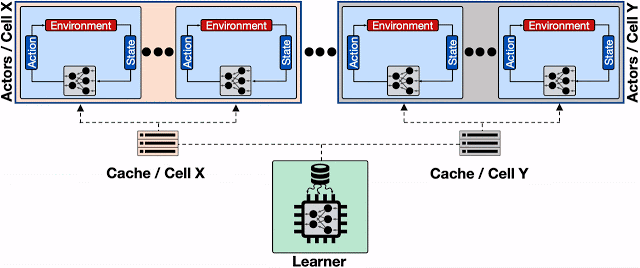
引入透明分布式缓存服务的分布式RL系统。多个Actor放置在不同的Borg单元中,Learner仅将更新的模型发送给分布式缓存组件。每个缓存组件应对邻近Actor和缓存区的模型请求更新。缓存区不仅减轻了Learner对模型更新请求提供服务的负担,而且减少了Actor的平均读取延迟。
高通量输入管道
为提高输入数据管道的吞吐量,Menger使用了Reverb——一种专为机器学习应用设计的、新型开源数据存储系统。在Reverb中,可以以在线或离线算法进行经验回放。但是,单个Reverb当前无法扩展到有成千上万Actors的分布式RL系统,并且Actor的写入吞吐量效率很低。
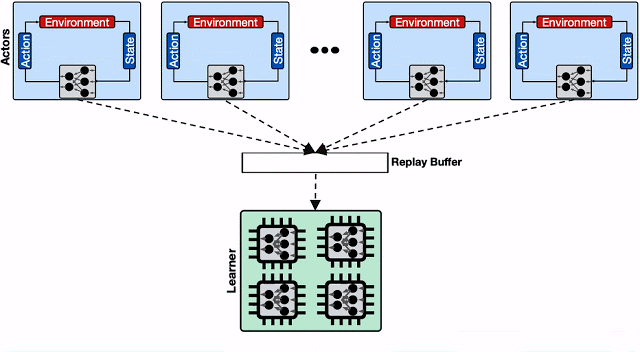
具有单个回放缓冲区的分布式RL系统。在Actor提出大量思维写请求后,回放缓冲区会受到限制并降低总体吞吐量。此外,一旦我们将Learner扩展到具有多个计算引擎(TPU Pod),单个回放缓冲区给这些引擎提供数据的效率就变得很低,严重影响总体收敛时间。
为了更好地了解回放缓冲器在分布式RL系统中的效率,我们评估了在不同负载大小(16 MB-512 MB)和不同Actor(16-2048)情况下的平均写入延迟。我们将回放缓冲区和Actor放置在同一个Borg单元中。,可以发现,随着Actor数量的增加,平均写入延迟显着增加。将Actor的数量从16扩展2048,16MB和512MB大小的有效负载的平均写入延迟分别增加了约6.2倍和约18.9倍。这样的写入等待时间的增加影响了数据收集时间,导致训练效率低下。
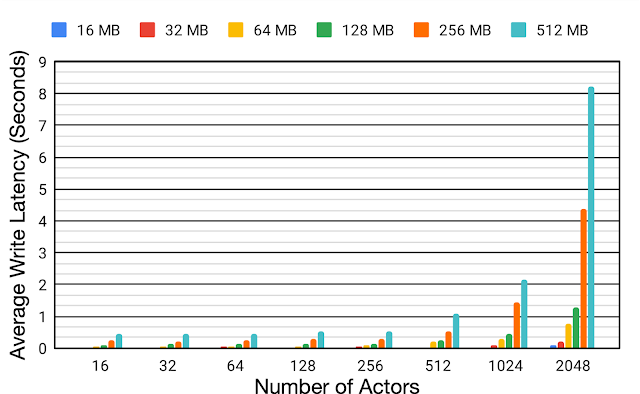
将不同大小的有效负载(16 MB-512 MB)和不同数量的Actor(16至2048)放置在同一个Borg单元上时,单个Reverb重回放缓冲区的平均写入延迟。
为缓解这种情况,我们使用Reverb的分片功能来增加Actor、Learner和和回放缓冲区之间的吞吐量。分片可在多个回放缓冲服务器之间平衡大量Actor的写入负载,而不是仅仅作用于单个回放缓冲服务器,同时由于少数Actor共享同一服务器,可以最小化每个回放缓冲服务器的平均写入延迟。这样Menger就可以在多个Borg单元中扩展数千个Actor。
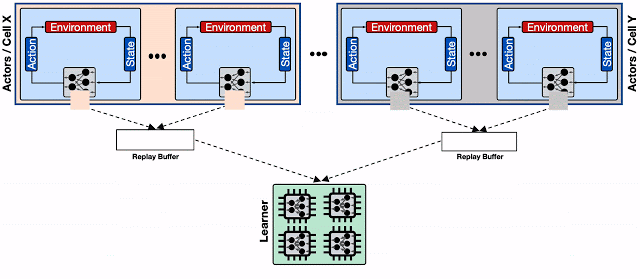
具有分片回放缓冲区的分布式RL系统。每个回放缓冲区用于存储位于同一Borg单元上的特定Actor。此外,分片回放缓冲区为加速器内核提供了具有更高吞吐量的输入管道。
实例验证:芯片放置
我们面向大型网表在芯片放置任务中测试了Menger。与基准相比,Menger使用512个TPU内核,在训练时间上有了显着改善(最高提升约8.6倍,即在最优配置下,可以将训练时间从约8.6小时减少到1小时)。尽管Menger针对TPU进行了优化,但该框架才是性能提升的关键因素,我们预计在GPU上实验也会看到类似的提升。
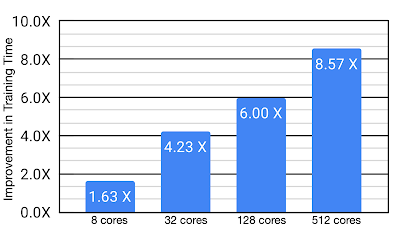
与芯片放置的基准相比,在不同TPU核心数量时使用Menger的训练时间的提升。
我们认为,Menger架构及其在芯片放置任务中优异的表现为进一步缩短芯片设计周期提供了方向。同时,我们还可以应用该架构实现其他具有挑战性的现实问题。
本文转自雷锋网,如需转载请至雷锋网官网申请授权。