ML Ops 是 AI 领域中一个相对较新的概念,可解释为「机器学习操作」。如何更好地管理数据科学家和操作人员,以便有效地开发、部署和监视模型?其中数据质量至关重要。
本文将介绍 ML Ops,并强调数据质量在 ML Ops 工作流中的关键作用。
ML Ops 的发展弥补了机器学习与传统软件工程之间的差距,而数据质量是 ML Ops 工作流的关键,可以加速数据团队,并维护对数据的信任。
什么是 ML Ops
ML Ops 这个术语从 DevOps 演变而来。
DevOps 是一组过程、方法与系统的统称,用于促进开发(应用程序 / 软件工程)、技术运营和质量保障(QA)部门之间的沟通、协作与整合。DevOps 旨在重视软件开发人员(Dev)和 IT 运维技术人员(Ops)之间沟通合作的文化、运动或惯例。透过自动化软件交付和架构变更的流程,来使得构建、测试、发布软件能够更加地快捷、频繁和可靠。
而 MLOps 基于可提高工作流效率的 DevOps 原理和做法,例如持续集成、持续交付和持续部署。ML Ops 将这些原理应用到机器学习过程,其目标是:
- 更快地试验和开发模型
- 更快地将模型部署到生产环境
- 质量保证
DevOps 的常用示例是使用多种工具对代码进行版本控制,如 git、代码审查、持续集成(CI,即频繁地将代码合并到共享主线中)、自动测试和持续部署(CD,即自动将代码合并到生产环境)。
在应用于机器学习时,ML Ops 旨在确保模型输出质量的同时,加快机器学习模型的开发和生产部署。但是,与软件开发不同,ML 需要处理代码和数据:
- 机器学习始于数据,而数据来源不同,需要用代码对不同来源数据进行清洗、转换和存储。
- 然后,将处理好的数据提供给数据科学家,数据科学家进行代码编写,完成特征工程、开发、训练和测试机器学习模型,最终将这些模型部署到生产环境中。
- 在生产中,ML 模型是以代码的形式存在的,输入数据同样可以从各种来源获取,并创建用于输入产品和业务流程的输出数据。
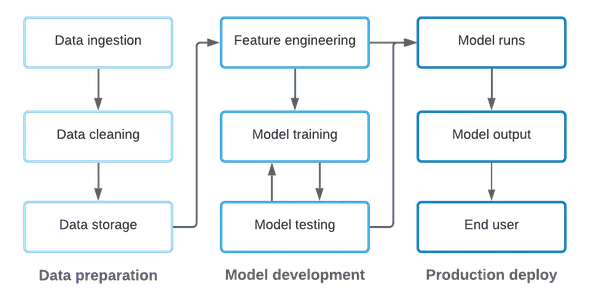
虽然上文的描述对该过程进行了简化,但是仍然可以看出代码和数据在 ML 环境中是紧密耦合的,而 ML Ops 需要兼顾两者。
具体来说,这意味着 ML Ops 包含以下任务:
- 对用于数据转换和模型定义的代码进行版本控制;
- 在投入生产之前,对所获取的数据和模型代码进行自动测试;
- 在稳定且可扩展的环境中将模型部署到生产中;
- 监控模型性能和输出。
数据测试和文档记录如何适配 ML Ops?
ML Ops 旨在加速机器学习模型的开发和生产部署,同时确保模型输出的质量。当然,对于数据质量人员来说,要实现 ML 工作流中各个阶段的加速和质量,数据测试和文档记录是非常重要的:
- 在利益相关者方面,质量差的数据会影响他们对系统的信任,从而对基于该系统做出决策产生负面影响。甚至更糟的是,未引起注意的数据质量问题可能导致错误的结论,并纠正这些问题又会浪费很多时间。
- 在工程方面,急于修复下游消费者注意到的数据质量问题,是消耗团队时间并缓慢侵蚀团队生产力和士气的头号问题之一。
- 此外,数据文档记录对于所有利益相关者进行数据交流、建立数据合同至关重要。
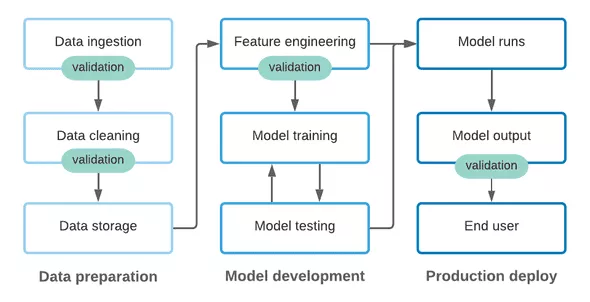
下文将从非常抽象的角度介绍 ML pipeline 中的各个阶段,并讨论数据测试和文档记录如何适应每个阶段。
1. 数据获取阶段
即使是在数据集处理的早期阶段,从长远来看,对数据进行质量检查和文档记录可以极大地加速操作。对于工程师来说,可靠的数据测试非常重要,可以使他们安全地对数据获取 pipeline 进行更改,而不会造成不必要的问题。同时,当从内部和外部上游来源获取数据时,为了确保数据出现未预料的更改,在获取阶段进行数据验证是非常重要的。
2. 模型开发
本文将特征工程、模型训练和模型测试作为核心模型开发流程的一部分。在这个不断迭代的过程中,围绕数据转换代码和支持数据科学家的模型输出提供支持,因此在一个地方进行更改不会破坏其他地方的内容。
在传统的 DevOps 中,通过 CI/CD 工作流进行持续的测试,可以快速地找出因代码修改而引入的任何问题。更进一步,大多数软件工程团队要求开发人员不仅要使用现有的测试来测试代码,还要在创建新功能时添加新的测试。同样,运行测试以及编写新的测试应该是 ML 模型开发过程的一部分。
3. 在生产中运行模型
与所有 ML Ops 一样,在生产环境中运行的模型依赖于代码和输入数据,来产生可靠的结果。与数据获取阶段类似,我们需要保护数据输入,以避免由于代码更改或实际数据更改而引起的不必要问题。同时,我们还应该围绕模型输出进行一些测试,以确保模型继续满足我们的期望。
尤其是在具有黑盒 ML 模型的环境中,建立和维护质量标准对于模型输出至关重要。同样地,在共享区域记录模型的预期输出可以帮助数据团队和利益相关者定义和传达「数据合同」,从而增加 ML pipeline 的透明度和信任度。
原文链接:https://greatexpectations.io/blog/ml-ops-data-quality/
【本文是51CTO专栏机构“机器之心”的原创译文,微信公众号“机器之心( id: almosthuman2014)”】