












本文转载自微信公众号「三太子敖丙」,作者三太子敖丙 。转载本文请联系三太子敖丙公众号。
前言
乱码这个东西相信大家都遇到过,今天我的女朋友三歪就火急火燎的上来找我:“亲爱的,我的idea怎么输出乱码了?”
我一顿操作就给他搞好了,但是三歪不愧是我的女朋友,好奇心跟我是一样样的,随我。
那为什么会出现乱码呢?
什么是编码,什么是解码?
什么是字符码,什么是字符集?
为什么要有 Unicode ?UTF-8 和 GBK 又有什么不同呢?
三歪坐在我的腿上对我撒娇似的说出这一连串的问题,我这个人宠粉但是更宠女朋友,所以就有了这篇文章。
为什么会出现乱码我们知道计算机里存储的只会是 0 和 1 组成的字节流,而仅是数字满足不了我们的需求,我们还需要文本的处理等等,但是计算机只认识数字,所以我们需要告诉计算机什么数字代表什么字符。
比如我指定 0000 代表 A,0001 代表 B 这样计算机就知道了,所以我要把 AB 这两个字符存入计算机的话,实际存储的就是0000 0001,其实就等于把每个字符定制一个唯一的编码。
但是这是我的指定,不同的人想法是不同的,比如小明就喜欢 1000 表示 A ,1111 表示 B,那小明的计算机按照他指定的编码方式存储,就是 1000 1111,之后传输给我的计算机,我拿到1000 1111,按照我的编码解出来可能就是 %& 了,这就乱码了。
所以乱码的本质就是编码和解码实现没对应上。
有些同学可能对编码和解码的概念不太熟悉,我来解释一下:
- 编码:其实就是将字符按照一定的格式转换成字节流的过程。
- 解码:就是将字节流解析成字符。
可以看到随意编码的就会产生各自的计算机都无法正确解析的情况,所以需要有一个标准,大家都按那个标准来指定字符和数字的对应关系。
标准字符编码
美国国家标准协会 ANSI 就制定了一个标准,即美国信息交换标准代码(ASCII),规定了常用字符集的集合和对应的数字编号,例如 65 表示 A。
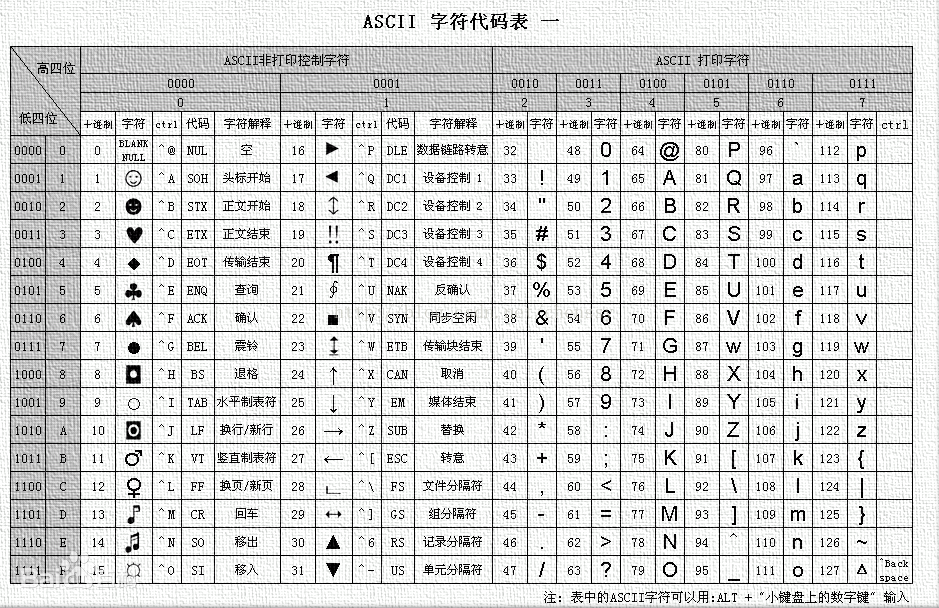
ASCII 实际上是 7 位编码,用二进制代码表示就是 0000000~1111111,不过 1 个字节是 8 位,所以一般都用 8 位来存储。可以看到 ASCII 代表了 128 个字符,这其实是倾美国的编码,你看同样讲英文的英国,ASCII 上都没英镑的标记。
还有人家的韩文,日文等等,更别说咱们中文了。
1 个字节最多只能表示 256 个字符,所以对我们来说不够用,因此需要扩展,像 GB2312 就是我们国家标准总局发布的《信息交换用汉字编码字符集》,后来又发布了 GBK ,这个 K 就是扩展的意思,在 GB2312 的基础上又添加了很多比如繁体字等字符。
所以说等于每个国家都有自己的标准,因为语言都是不同的,各字符集的不同就导致计算机之间文档的交流非常困难,因此大家又开始了一波标准化。
像美国的 ANSI 组织制定了 ANSI 标准字符编码,其实就是制定平台默认的编码,比如中国的操作系统就用 GBK ,如果是美国就用 ASCII,操作系统会预装这些标准字符集。
不过这只能解决一份文档一份字符编码的情况,假设我文档里面有日语、法语、德语、俄语、中文,你说怎么办?
Unicode
所以又搞了个 Unicode,又称统一码、万国码、单一码。
Unicode 字符集涵盖了目前人类使用的所有字符,并为每个字符进行统一编号,分配唯一的字符码,你看这种事情总得有人做,不然就没法统一。
这里有几个术语我解释一下,让大伙更加清晰一些。
- 字符:其实就像英文字母,或者我们的中文都叫字符
- 字符集:那就是字符和编号对应的集合
- 字符码:就是字符集里面字符对应的数字,或者说编号,比如在 ASCII 字符集里面, A 的字符码是 65
- 字符编码:就是按照字符集中字符和数字的映射关系,转化成字节流的实现
对于 Unicode 而言有一点和之前的编码不太一样,它将字符集和编码实现解耦了。
之前的编码比如 ASCII 编码、GBK 编码等等,它们的字符集和编码实现是绑死的,你可以理解成以前的编码其实就是查表,有一个固定的表格里面存储这字符和对应固定的二进制,比如 A 对应的编号是 65,其二进制序列就是 01000001。
而 Unicode 不一样,它将字符集和字符编码实现分开了,比如 A 对应的编号是 65,但是对应的二进制序列就不一定了,得看具体的字符编码,如果是 UTF-8 编码,则是 01000001,如果是 UTF-16 编码(大端),则是 00000000 01000001。
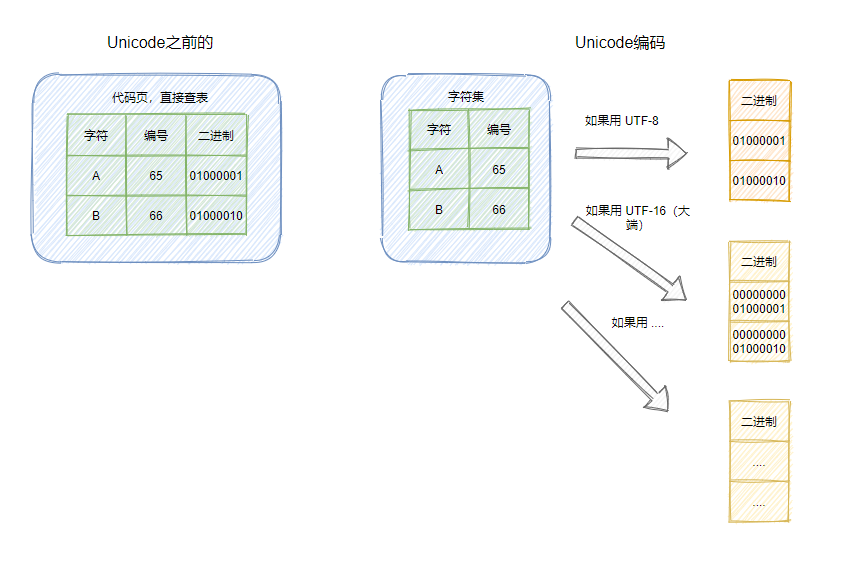
这其实也是为什么我们现在常用 UTF-8 而不是 UTF-16 的原因,可以看到 UTF-16 编码存储效率较低,最少使用两个字节,并且像 C 语言的很多函数都会将 0x00 字节作为字符串的停止符来解析,所以才搞了个 UTF-8,其使用 1~4 字节为每个字符编码,是变长的,具体如何编码的我就不说了,随便查一下就有。
最后
至此我们已经清晰了乱码的根源,也知晓了为什么会有那么多字符编码的出现,毕竟语言多,一开始出了个 ASCII,但是对于其他国家来说不够用,于是都各自进行了扩展。
而编码多了各个国家之间难以做到统一,不易兼容,所以后来国际组织制定搞了个 Unicode 字符集,对所有字符做了统一的编排,并且为了使得编码更加灵活把字符集和编码实现分开来。
对了,为什么英文都不会出现乱码就是因为绝大部分的字符集都是基于 ASCII 扩展的,所以都兼容 ASCII 。
本期就是应该算是一期比较有意思的科普系列,但是还是渴求你的点赞哈哈。













