













本文转载自微信公众号「Linux开发那些事儿」,作者 LinuxThings 。转载本文请联系Linux开发那些事儿公众号。
在日常工作中,对于MySQL排序规则,很少关注,大部分时候都是直接使用字符集默认的排序规则,常常忽视了排序规则的细节问题,了解排序规则有助于更好的理解MySQL字符比较和排序相关的知识。
简述
说起排序规则就离不开字符集,严格来说,排序规则是依赖于字符集的。
字符集是用来定义MySQL存储不同字符的方式,而排序规则一般指对字符集中字符串之间的比较、排序制定的规则。一种字符集可以对应多种排序规则,但是一种排序规则只能对应指定的一种字符集,两个不同的字符集不能有相同的排序规则。
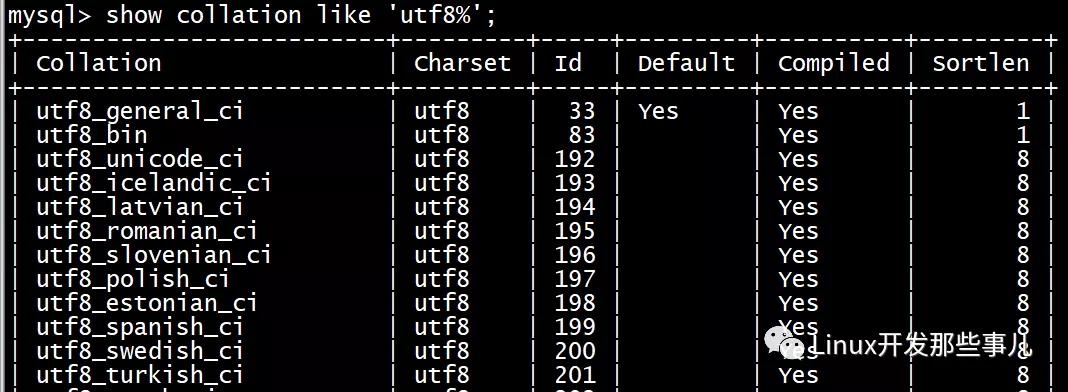
上图中,Collation 列表示排序方式,Charset 列表示字符集,可以看出 utf8 字符集对应着许多的排序方式,排序方式那一列每一项的值都不一样,并且每一项都对应唯一一种字符集,在这里是 utf8 字符集。
默认排序规则
- 字符集的默认排序规则
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
mysql> show character set like 'utf8%';
+---------+---------------+--------------------+--------+
| Charset | Description | Default collation | Maxlen |
+---------+---------------+--------------------+--------+
| utf8 | UTF-8 Unicode | utf8_general_ci | 3 |
| utf8mb4 | UTF-8 Unicode | utf8mb4_general_ci | 4 |
+---------+---------------+--------------------+--------+
2 rows in set (0.00 sec)
每种字符集都有一个默认的排序规则, 可以通过下面的SQL语句查询指定字符集的默认排序规则
上面的例子是查询字符集前缀包含utf8的默认排序方式,从中可以得知:
utf8字符集的默认排序方式是 utf8_general_ci 字符集中字符最大长度占3个字节
utf8mb4 字符集的默认排序方式是 utf8mb4_general_ci 字符集中字符最大长度占4个字节
- 数据库的默认排序规则
MySQL服务器的默认字符集可以在 /etc/my.cnf 配置中的 [mysqld] 下修改
例如:现需要把MySQL服务器的默认字符集设置为 utf8, 默认排序规则设置为 utf8_general_ci, 只需要在 /etc/my.cnf 配置文件的 [mysqld] 下添加以下子项
character-set-server=utf8
collation-server=utf8_general_ci
- 1.
- 2.
创建数据库的时候如果没有指定字符集,会使用MySQL服务器默认字符集和默认排序规则
假如: 在下面例子中,MySQL服务器的默认字符集和默认排序规则分别是 utf8 和 utf8_general_ci
mysql> create database at;
Query OK, 1 row affected (0.00 sec)
mysql> select SCHEMA_NAME,DEFAULT_CHARACTER_SET_NAME,DEFAULT_COLLATION_NAME from INFORMATION_SCHEMA.SCHEMATA where SCHEMA_NAME='at';
+-------------+----------------------------+------------------------+
| SCHEMA_NAME | DEFAULT_CHARACTER_SET_NAME | DEFAULT_COLLATION_NAME |
+-------------+----------------------------+------------------------+
| at | utf8 | utf8_general_ci |
+-------------+----------------------------+------------------------+
1 row in set (0.00 sec)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
在上面的例子中,创建了 at 数据库,创建数据库的时候没有为数据库指定字符集和排序规则,此时会使用 MySQL服务器的默认字符集和排序规则
通过SQL语句查询 at 数据库的默认字符集和默认排序规则,结果和MySQL服务器的默认字符集和默认排序规则是一样的
排序规则命名以及名字后缀
- 命名
排序规则的命名是以和它自身关联的字符集名字开头的,后面再接一个或多个后缀来表示指定字符集的一种排序规则
例如:utf8_general_ci 和 utf8_bin 就是 utf8字符集的两种排序规则, latin1_swedish_ci 是 latin1字符集的排序规则
注意: binary 字符集只有一种排序规则,并且它的排序规则名字和字符集名字一样, 也是 binary
- 后缀
排序规则名字的后缀是有特殊意义的,根据后缀可以知道排序规则是否区分大小写,是否区分重音,是否是二进制等等,下面列出了部分后缀的说明
_ci : 不区分大小写, Case-insensitive的缩写
_cs : 区分大小写,Case-sensitive的缩写
_ai : 不区分重音,Accent-insensitive的缩写
_as : 区分重音,Accent-sensitive的缩写
_bin : 二进制
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
1: 不区分大小写
mysql> SET NAMES 'utf8' COLLATE 'utf8_unicode_ci';
Query OK, 0 rows affected (0.02 sec)
mysql> select 'a' = 'A';
+-----------+
| 'a' = 'A' |
+-----------+
| 1 |
+-----------+
1 row in set (0.00 sec)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
例子中排序规则为 utf8_unicode_ci 是不区分大小写的,所以字符 a 和字符 A 会被当做相同字符处理
2: 区分大小写
mysql> SET NAMES 'latin1' COLLATE 'latin1_general_cs';
Query OK, 0 rows affected (0.00 sec)
mysql> select 'a' = 'A';
+-----------+
| 'a' = 'A' |
+-----------+
| 0 |
+-----------+
1 row in set (0.00 sec)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
例子中排序规则为 latin1_general_cs 是会区分大小写的,所以字符 a 和字符 A 会被认为是两个不同的字符
3: 二进制
mysql> SET NAMES 'utf8' COLLATE 'utf8_bin';
Query OK, 0 rows affected (0.00 sec)
mysql> select 'a' = 'A';
+-----------+
| 'a' = 'A' |
+-----------+
| 0 |
+-----------+
1 row in set (0.00 sec)
mysql> select 'à' = 'a';
+------------+
| 'à' = 'a' |
+------------+
| 0 |
+------------+
1 row in set (0.00 sec)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
上面例子使用的排序规则是 utf8_bin 从结果可以得知:utf8_bin 排序规则区分大小写,也区分重音字符
4: 是否区分重音
重音字符是类似 à、ě、ň 的字符,不区分重音是指字符 a和 à、e和ě 以及 n和ň 被认为是同一个字符
对于非二进制(后缀为 _bin)的排序规则, 如果排序规则名字后缀不包含 _ai 和 _as, 则排序规则名称中的 _ci 默认隐含了_ai, _cs默认隐含了_as
例如: utf8_unicode_ci排序规则是不区分大小写并且隐含不区分重音的
latin1_general_cs 排序规则是区分大小写并且隐含区分重音的
具体的请查看下面的例子
mysql> SET NAMES 'utf8' COLLATE 'utf8_unicode_ci';
Query OK, 0 rows affected (0.02 sec)
mysql> select 'à' = 'a';
+------------+
| 'à' = 'a' |
+------------+
| 1 |
+------------+
1 row in set (0.00 sec)
mysql> SET NAMES 'latin1' COLLATE 'latin1_general_cs';
Query OK, 0 rows affected (0.00 sec)
mysql> select 'à' = 'a';
+------------+
| 'à' = 'a' |
+------------+
| 0 |
+------------+
1 row in set (0.01 sec)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
查看排序规则
- 查看数据库数据库的排序规则
mysql> select SCHEMA_NAME,DEFAULT_CHARACTER_SET_NAME,DEFAULT_COLLATION_NAME from INFORMATION_SCHEMA.SCHEMATA where SCHEMA_NAME='at';
+-------------+----------------------------+------------------------+
| SCHEMA_NAME | DEFAULT_CHARACTER_SET_NAME | DEFAULT_COLLATION_NAME |
+-------------+----------------------------+------------------------+
| at | latin1 | latin1_swedish_ci |
+-------------+----------------------------+------------------------+
1 row in set (0.00 sec)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
上面的例子是查看 at 数据库的字符集和排序规则,从结果可以得知:at数据库的排序规则是latin1_swedish_ci
方法2:直接查询 collation_database 变量值
mysql> use at;
Database changed
mysql> show variables like 'collation_database';
+--------------------+-------------------+
| Variable_name | Value |
+--------------------+-------------------+
| collation_database | latin1_swedish_ci |
+--------------------+-------------------+
1 row in set (0.00 sec)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
实例中 use at SQL语句切换到 at 数据库,然后使用 show variables like 'collation_database'; 语句查询 at 数据库的排序规则
- 查看表的排序规则
方法1:根据数据库名和表名查看 INFORMATION_SCHEMA.TABLES 表中的 TABLE_COLLATION 字段,可以得到指定数据库中指定表的排序规则,具体的实例如下所示:
mysql> SELECT TABLE_SCHEMA, TABLE_NAME,TABLE_COLLATION FROM INFORMATION_SCHEMA.TABLES where TABLE_SCHEMA='test' and TABLE_NAME = 'tc';
+--------------+------------+-----------------+
| TABLE_SCHEMA | TABLE_NAME | TABLE_COLLATION |
+--------------+------------+-----------------+
| test | tc | utf8_general_ci |
+--------------+------------+-----------------+
1 row in set (0.00 sec)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
方法2:执行 show create table 表名 语句查看
mysql> show create table tc\G
*************************** 1. row ***************************
Table: tc
Create Table: CREATE TABLE `tc` (
`id` int(11) NOT NULL,
`a` char(32) NOT NULL,
`b` char(32) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL,
`c` char(32) CHARACTER SET latin1 COLLATE latin1_general_cs NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
上面的例子中, show create table tc\G 是查看 tc 表的创建语句,一般创建表的时候会指定排序规则,例子中没有显示指定表的排序规则,这是因为使用的是字符集的默认排序规则,tc 表的字符集是 utf8 , 默认的排序规则是 utf8_general_ci
- 查看字段的排序规则
上面 查看表的排序规则 小节的 方法2 是查看表的创建语句,字段的排序规则也可以从表创建语句中查看到,如果没有显示指定字段的排序规则,创建表的语句中是看不到排序规则的,这表示该字段使用字符集的默认排序方式
mysql> show create table tc\G
*************************** 1. row ***************************
Table: tc
Create Table: CREATE TABLE `tc` (
`id` int(11) NOT NULL,
`a` char(32) NOT NULL,
`b` char(32) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL,
`c` char(32) CHARACTER SET latin1 COLLATE latin1_general_cs NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
上面例子中,表 tc的字符集是utf8
字段 a 没有显示指定排序规则,则它使用的是utf8字符集的默认排序规则utf8_general_ci
字段 b 的排序规则是 utf8_bin
字段 c 的排序规则是 latin1_general_cs
修改排序规则
修改数据库的排序规则
数据库的默认排序规则可以通过 alter database 数据库名 collate 新的排序规则名字 SQL语句进行修改
mysql> select SCHEMA_NAME,DEFAULT_CHARACTER_SET_NAME,DEFAULT_COLLATION_NAME from INFORMATION_SCHEMA.SCHEMATA where SCHEMA_NAME='at';
+-------------+----------------------------+------------------------+
| SCHEMA_NAME | DEFAULT_CHARACTER_SET_NAME | DEFAULT_COLLATION_NAME |
+-------------+----------------------------+------------------------+
| at | utf8 | utf8_general_ci |
+-------------+----------------------------+------------------------+
1 row in set (0.00 sec)
mysql> alter database at collate utf8_bin;
Query OK, 1 row affected (0.00 sec)
mysql> select SCHEMA_NAME,DEFAULT_CHARACTER_SET_NAME,DEFAULT_COLLATION_NAME from INFORMATION_SCHEMA.SCHEMATA where SCHEMA_NAME='at';
+-------------+----------------------------+------------------------+
| SCHEMA_NAME | DEFAULT_CHARACTER_SET_NAME | DEFAULT_COLLATION_NAME |
+-------------+----------------------------+------------------------+
| at | utf8 | utf8_bin |
+-------------+----------------------------+------------------------+
mysql> alter database at collate latin1_swedish_ci ;
Query OK, 1 row affected (0.00 sec)
mysql> select SCHEMA_NAME,DEFAULT_CHARACTER_SET_NAME,DEFAULT_COLLATION_NAME from INFORMATION_SCHEMA.SCHEMATA where SCHEMA_NAME='at';
+-------------+----------------------------+------------------------+
| SCHEMA_NAME | DEFAULT_CHARACTER_SET_NAME | DEFAULT_COLLATION_NAME |
+-------------+----------------------------+------------------------+
| at | latin1 | latin1_swedish_ci |
+-------------+----------------------------+------------------------+
1 row in set (0.00 sec)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
上面的例子中,at 数据库初始的字符集和排序规则分别是 utf8 和 utf8_general_ci
SQL语句: alter database at collate utf8_bin; 把字符集和排序规则修改为 utf8 和 utf8_bin
SQL语句: alter database at collate latin1_swedish_ci; 把字符集和排序规则修改为 latin1 和 latin1_swedish_ci
由于latin1_swedish_ci排序规则 是属于latin1字符集,所以 at 数据库排序规则修改成 latin1_swedish_ci 之后,字符集相应的也会由 utf8 变成 latin1
- 修改表的排序规则
通过 alter table 表名 collate 新的排序规则名字; 语句可以修改表的排序规则
注意:上面的语句修改表排序规则,对现有字段的排序规则没影响,只影响后续新添加字段的默认排序规则
mysql> show create table tc\G
*************************** 1. row ***************************
Table: tc
Create Table: CREATE TABLE `tc` (
`id` int(11) NOT NULL,
`a` char(32) NOT NULL,
`b` char(32) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL,
`c` char(32) CHARACTER SET latin1 COLLATE latin1_general_cs NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
mysql> alter table tc collate latin1_swedish_ci;
Query OK, 0 rows affected (0.00 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show create table tc\G
*************************** 1. row ***************************
Table: tc
Create Table: CREATE TABLE `tc` (
`id` int(11) NOT NULL,
`a` char(32) CHARACTER SET utf8 NOT NULL,
`b` char(32) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL,
`c` char(32) CHARACTER SET latin1 COLLATE latin1_general_cs NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
上面例子中,tc表初始的字符集是utf8,默认排序规则是utf8_general_ci 执行 alter table tc collate latin1_swedish_ci;SQL语句把表的排序规则修改成latin1_swedish_ci
由于latin1_swedish_ci排序规则是属于latin1字符集的,所以此时表的字符集也会修改成latin1
修改表排序规则之前,字段a的排序规则是默认的utf8_general_ci,在创建表的语句中没有显示出来
修改排序规则之后,由于表默认的排序规则发生的变化,所以字段a会显示出它原本的字符集
- 修改字段的排序规则
mysql> show create table tc\G
*************************** 1. row ***************************
Table: tc
Create Table: CREATE TABLE `tc` (
`id` int(11) NOT NULL,
`a` char(32) CHARACTER SET utf8 NOT NULL,
`b` char(32) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL,
`c` char(32) CHARACTER SET latin1 COLLATE latin1_general_cs NOT NULL,
`d` char(32) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
mysql> alter table tc modify b char(32) not null collate latin1_general_cs;
Query OK, 0 rows affected (0.05 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show create table tc\G
*************************** 1. row ***************************
Table: tc
Create Table: CREATE TABLE `tc` (
`id` int(11) NOT NULL,
`a` char(32) CHARACTER SET utf8 NOT NULL,
`b` char(32) CHARACTER SET latin1 COLLATE latin1_general_cs NOT NULL,
`c` char(32) CHARACTER SET latin1 COLLATE latin1_general_cs NOT NULL,
`d` char(32) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
上面例子中,字段 b 原始的字符集和排序规则分别是 utf8、utf8_bin
语句 alter table tc modify b char(32) not null collate latin1_general_cs;把字段 b 的排序规则修改成 latin1_general_cs, 由于latin1_general_cs 排序规则是属于latin1字符集, 所以修改之后字段 b 的字符集和排序规则都发生了变化
小结
本文介绍了MySQL字符集的排序规则,由于篇幅原因,有些点没有涉及到,更多排序规则有关的细节可以自行查阅MySQL官方文档





















