在日常使用 Python 时,我们经常需要创建一个列表,相信大家都很熟练了吧?
- 方法一:使用成对的方括号语法
- list_a = []
- listlist_b = list()
上面的两种写法,你经常使用哪一个呢?是否思考过它们的区别呢?
让我们开门见山,直接抛出本文的问题吧:两种创建列表的 [] 与 list() 写法,哪一个更快呢,为什么它会更快呢?
注:为了简化问题,我们以创建空列表为例进行分析。关于列表的更多介绍与用法说明,可以查看这篇文章
1. [] 是 list() 的三倍快
对于第一个问题,使用timeit模块的 timeit() 函数就能简单地测算出来:
- >>> import timeit
- >>> timeit.timeit('[]', number=10**7)
- >>> timeit.timeit('list()', number=10**7)
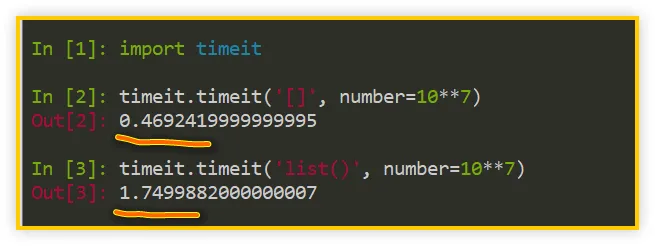
如上图所示,在各自调用一千万次的情况下,[] 创建方式只花费了 0.47 秒,而 list() 创建方式要花费 1.75 秒,所以,后者的耗时是前者的 3.7 倍!
这就回答了刚才的问题:创建空列表时,[] 要比 list() 快不少。
注:timeit() 函数的效率跟运行环境相关,每次执行结果会有微小差异。我在 Python3.8 版本实验了几次,总体上 [] 速度是 list() 的 3 倍多一点。
2. list() 比 [] 执行步骤多
那么,我们继续来分析一下第二个问题:为什么 [] 会更快呢?
这一次我们可以使用dis模块的 dis() 函数,看看两者执行的字节码有何差别:
- >>> from dis import dis
- >>> dis("[]")
- >>> dis("list()")
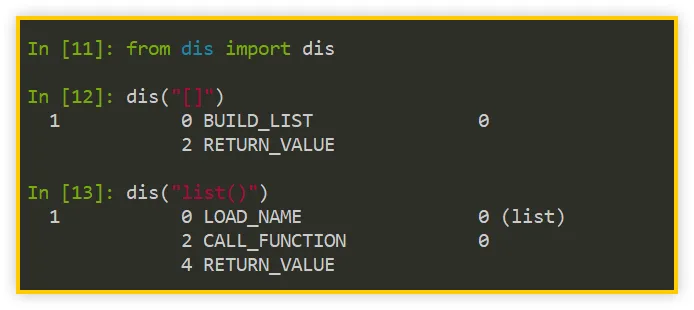
如上图所示,[] 的字节码有两条指令(BUILD_LIST 与 RETURN_VALUE),而 list() 的字节码有三条指令(LOAD_NAME、CALL_FUNCTION 与 RETURN_VALUE)。
这些指令意味着什么呢?该如何理解呢?
首先,对于 [],它是 Python 中的一组字面量(literal),像数字之类的字面量一样,表示确切的固定值。
也就是说,Python 在解析到它时,就知道它要表示一个列表,因此会直接调用解释器中构建列表的方法(对应BUILD_LIST),来创建列表,所以是一步到位。
而对于 list(),“list”只是一个普通的名称,并不是字面量,也就是说解释器一开始并不认识它。
因此,解释器的第一步是要找到这个名称(对应LOAD_NAME)。它会按照一定的顺序,在各个作用域中逐一查找(局部作用域--全局作用域--内置作用域),直到找到为止,找不到则抛出NameError。
解释器看到“list”之后是一对圆括号,因此第二步是把这个名称当作可调用对象来调用,即把它当成一个函数进行调用(对应 CALL_FUNCTION)。
因此,list() 在创建列表时,需要经过名称查找与函数调用两个步骤,才能真正开始创建列表(注:CALL_FUNCTION 在底层还会有一些函数调用过程,才能走到跟 BUILD_LIST 相通的逻辑,此处我们忽略不计)。
至此,我们就可以回答前面的问题了:因为 list() 涉及的执行步骤更多,因此它比 [] 要慢一些。
3. list() 的速度提升
看完前两个问题的解答过程,你也许觉得还不够过瘾,而且可能觉得就算知道了这个冷知识,也不会有多大的帮助,似乎那微弱的提升显得微不足道。
由于有发散性思考的习惯,我还想到了另外一个挺有意思的问题:list() 的速度能否提升呢?
在刚刚发布的 Python 3.9.0 版本中,它给 list() 实现了更快的 vectorcall 协议,因此执行速度会有一定的提升。
感兴趣的同学可以去 Python 官网下载 3.9 版本。
根据我多轮的测试结果,在新版本中运行 list() 一千万次,耗时大概在 1 秒左右,也就是 [] 运行耗时的 2 倍,相比于前面接近 4 倍的数据,当前版本总体上是提升了不少。