我们之前的机器学习专题已经结束了,我们把机器学习领域当中常用的算法、模型以及它们的原理以及实现都过了一遍。虽然还有一些技术,比如马尔科夫、隐马尔科夫、条件随机场等等没有涉及到。但是这些内容相比来说要弱一些,使用频率并不是非常高,我们就不一一叙述了,感兴趣的同学可以自行研究一下。我想像是GBDT、SVM这些模型都能理解的话,那些模型想必也不在话下。
深度学习简介
深度学习最近几年非常火,很多人会把它和人工智能扯上联系。这里的深入并不是指学习深入,也不是指概念很深入,只是单纯地指多层神经网络组成的“深度”神经网络。
其实无论是神经网络还是深度神经网络或者是深度学习当中的算法,其实至今都已经有好几十年的历史了。比如众所周知的深度学习核心算法反向传播算法最早提出在1989年,距今已经三十多年了。虽然历史并不短,但是这门领域之前起起伏伏,虽然也曾辉煌过,但一直到最近几年才强势崛起,成为了几乎家喻户晓的概念。
其中的原因也很简单,因为训练神经网络的复杂度实在是太大了,以之前的计算资源根本扛不住这么大规模的运算。所以在之前那个年代,深度学习还是一个偏小众的领域。研究的人不多,经费也有限。直到最近几年,由于计算资源飞速发展,再加上通过GPU加速神经网络训练的黑科技被发明出来,使得原本不可能做到的变成了可能。再加上阿尔法狗战胜了李世石这种划时代的事件发生,导致了深度学习一时间吸引了大量的资源与关注,那么这个行业自然也就蒸蒸日上发展起来了。
既然深度学习是有关于神经网络的技术,那么我们这个专题文章讲解的内容自然也不会脱离神经网络的范畴。今天我们就从神经网络最基础的神经元——感知机开始说起。
感知机
感知机的英文是perceptron,我们可以把它理解成神经网络的最小构成单位。我们知道在自然界的生物体当中,神经的最小单位是神经元,一个神经元是一个细胞,它大概长成下面这个样子。我想绝大多数同学都应该曾经在生物课的课本上看到过神经元的图片。
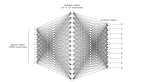
感知机可以理解成神经元的仿生结构,我们都知道一个神经元细胞可以连接多个神经细胞,这些神经元之间彼此连接形成了一张巨大的网络。神经元之间可以互相传递电信号以及化学物质,从而形成了一系列复杂的反应。人类的大脑就可以理解成一张极其巨大且复杂的神经网络,但是关于人类的大脑以及生物的神经元网络究竟是如何起作用的,目前还没有定论。
但计算学家模拟神经元以及神经网络搭建了深度学习的模型,的确在一些问题上取得了非凡的结果。感知机就可以认为是一个神经元细胞的抽象,我们都知道一个神经元细胞会从其他若干个神经元当中获取信号,也会向另一个神经元细胞传递信号。我们把传入的信号当成是输入,传出的信号当做是输出,这样就得到了感知机的结构。
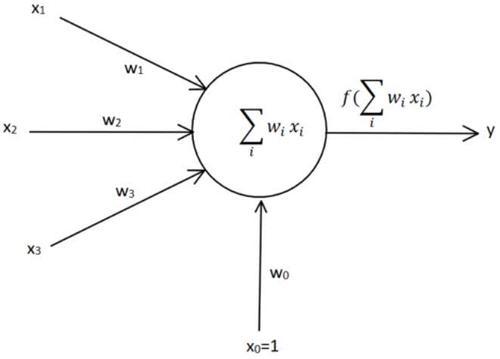
这里我们把结构做到了最简,我们把输入的信号都看成是浮点数,每一个信号都有一个自己的权重,所有的信号会累加在一起,最后通过一个映射函数输出信号。
我们来看最简单的感知机来做个例子:
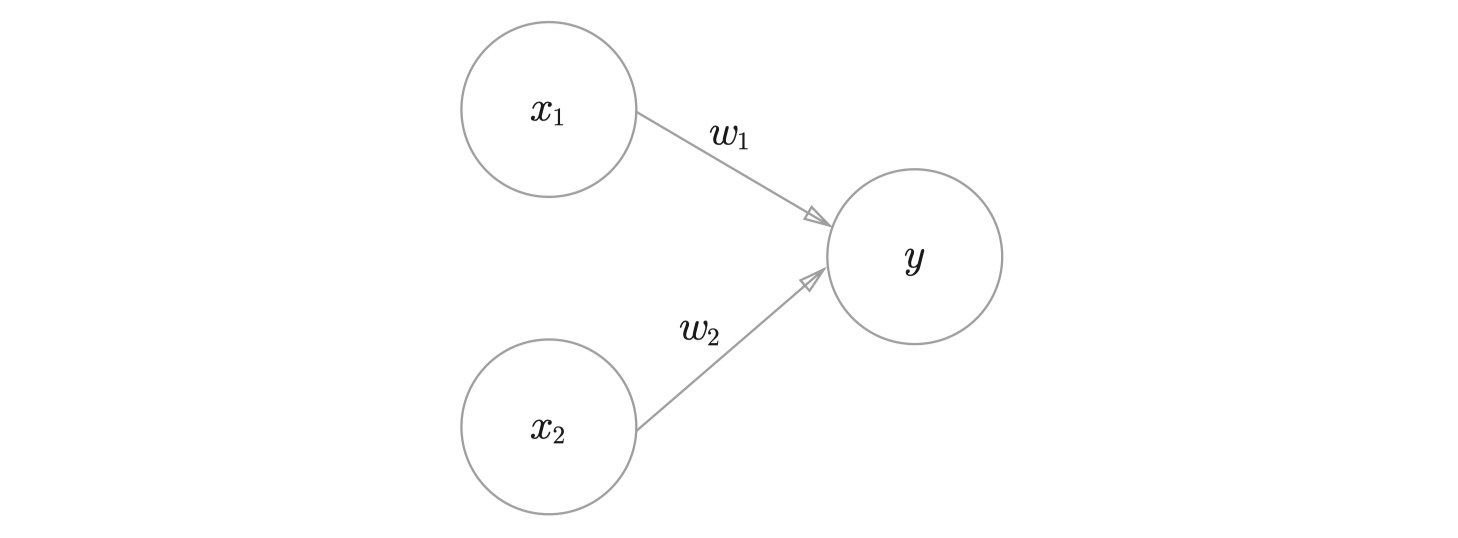
这个感知机只有两个输入,我们很容易得到
这里的y是一个浮点数,我们可以在y上套一个sign函数。所谓的sign函数,即使根据阈值来进行分类。比如我们设置一个阈值
如果
那么
否则的话
说起来又是神经元又是感知机什么的,但它的原理很简单,我们把公式写出来就是:
这里的
叫做激活函数(activate function)。我们上面列举的例子当中的激活函数是sign函数,也就是根据阈值进行分类的函数。在神经网络当中常用的激活函数主要有三种,一种是我们之前就非常熟悉的sigmoid函数,一种是relu函数,另外一种是tanh函数。我们来分别看下他们的图像。
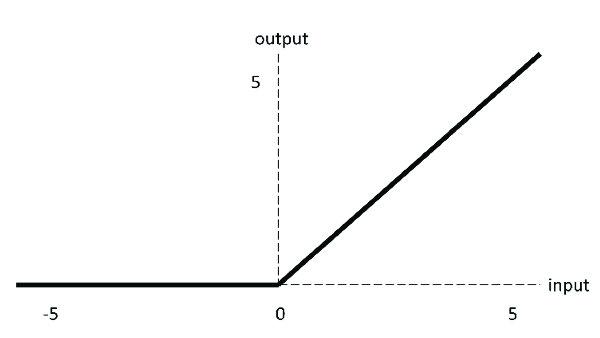
relu函数的方程很简单:
。但是它的效果非常好,也是神经网络当中最常用的激活函数之一。使用它的收敛速度要比sigmoid更快,原因也很简单,因为sigmoid函数图像两边非常非常光滑,导致我们求导得出的结果非常接近0,这样我们梯度下降的时候自然收敛速度就慢了。这一点我们之前在介绍sigmoid函数的时候曾经提到过。
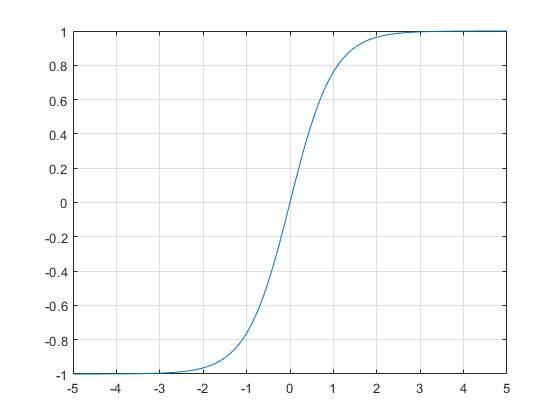
从图像上来看tanh函数和sigmoid函数非常相似,一点细微的差别是他们的值域不同,sigmoid函数的值域是0到1,而tanh是-1到1。虽然看起来只是值域不同,但是区别还是挺大的,一方面是两者的敏感区间不同。tanh的敏感区间相比来说更大,另外一点是,sigmoid输出的值都是正值,在一些场景当中可能会产生问题。
相信大家看出来了,感知机其实就是一个线性方程再套上一个激活函数。某种程度上来说逻辑回归模型也可以看成是一个感知机。有一个问题大家可能感到很疑惑,为什么线性方程后面需要加上一个激活函数呢?如果不加行不行?
答案是不行,原因也很简单,因为当我们把多个神经元组织在一起形成了一张网络之后。如果每一个神经元的计算都是这样纯线性的,那么整个神经网络其实也等价于一个线性的运算。这个是可以在数学上得到证明的,所以我们需要在感知机当中增加一点东西,让它的计算结果不是纯线性的。
感知机和逻辑电路
最后我们来看一个实际一点的例子,最简单的例子当然是逻辑电路当中的与或门。与门、或门、非门其实都差不多,都是有两个输入和一个输出。
我们以与门为例:
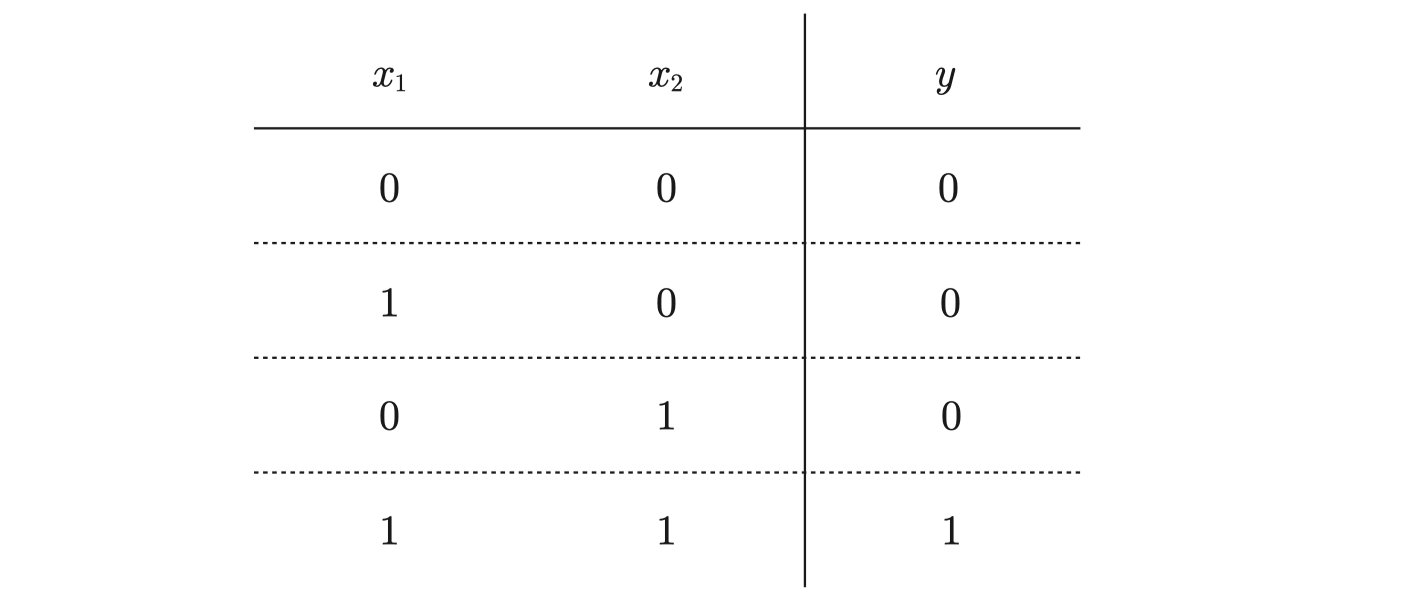
二进制的与操作我们都很熟悉了,只有两个数都为1才能得到1。我们要写出这样一个感知机来也非常简单:
- def AND(x1, x2):
- x = np.array([x1, x2]) w = np.array([0.5, 0.5])
- theta = 0.7
- return w.dot(x) > theta
同样我们也可以写出或门或者是非门,这也并不困难。但是也会发现有一种情况我们无法解决,就是异或的情况。我们先来看下异或的真值表:

我们是没有办法通过一个感知机来实现异或数据的分割,这个问题我们之前在SVM模型当中曾经介绍过,因为异或的数据不是线性可分的,也就是说我们没办法通过一条分割线将它分割。
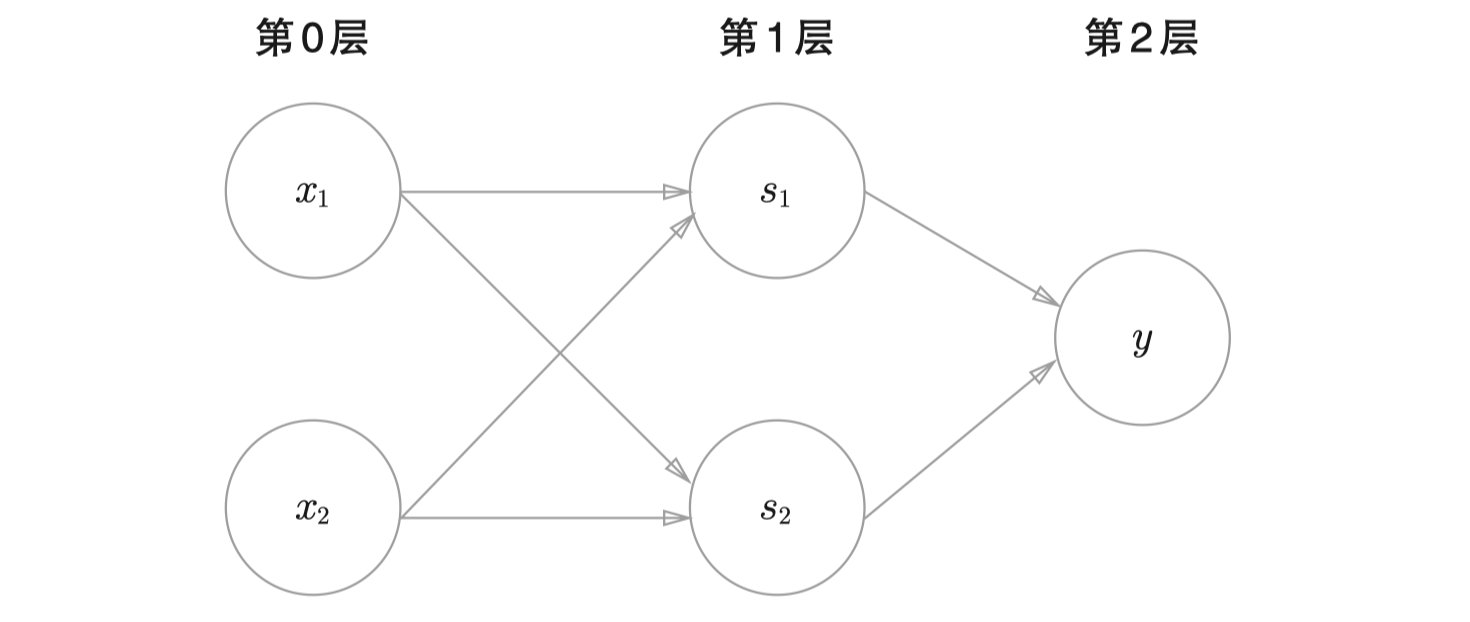
但是异或问题并非是不可解决的,我们用单独的感知机不能够分割,但是我们可以将感知机串联起来,形成一张简单的神经网络,这个问题就变得可解了。假设我们已经把与门、或门、非门都实现了一遍。我们可以这样来实现异或门:
- def XOR(x1, x2):
- # 非门
- s1 = NAND(x1, x2)
- s2 = OR(x1, x2)
- return AND(s1, s2)
整个感知机的结构是这样的:
TensorFlow官网提供了一个叫做playground的网页应用,可以让我们自己直观地感受神经网络的组成以及它的训练过程。比如刚才的异或问题,我们就可以自己来设置神经网络的层数以及每一层包含的神经元的数量。并且还可以设置神经元的激活函数,可以非常直观地体会神经网络的训练过程以及各种参数的作用。
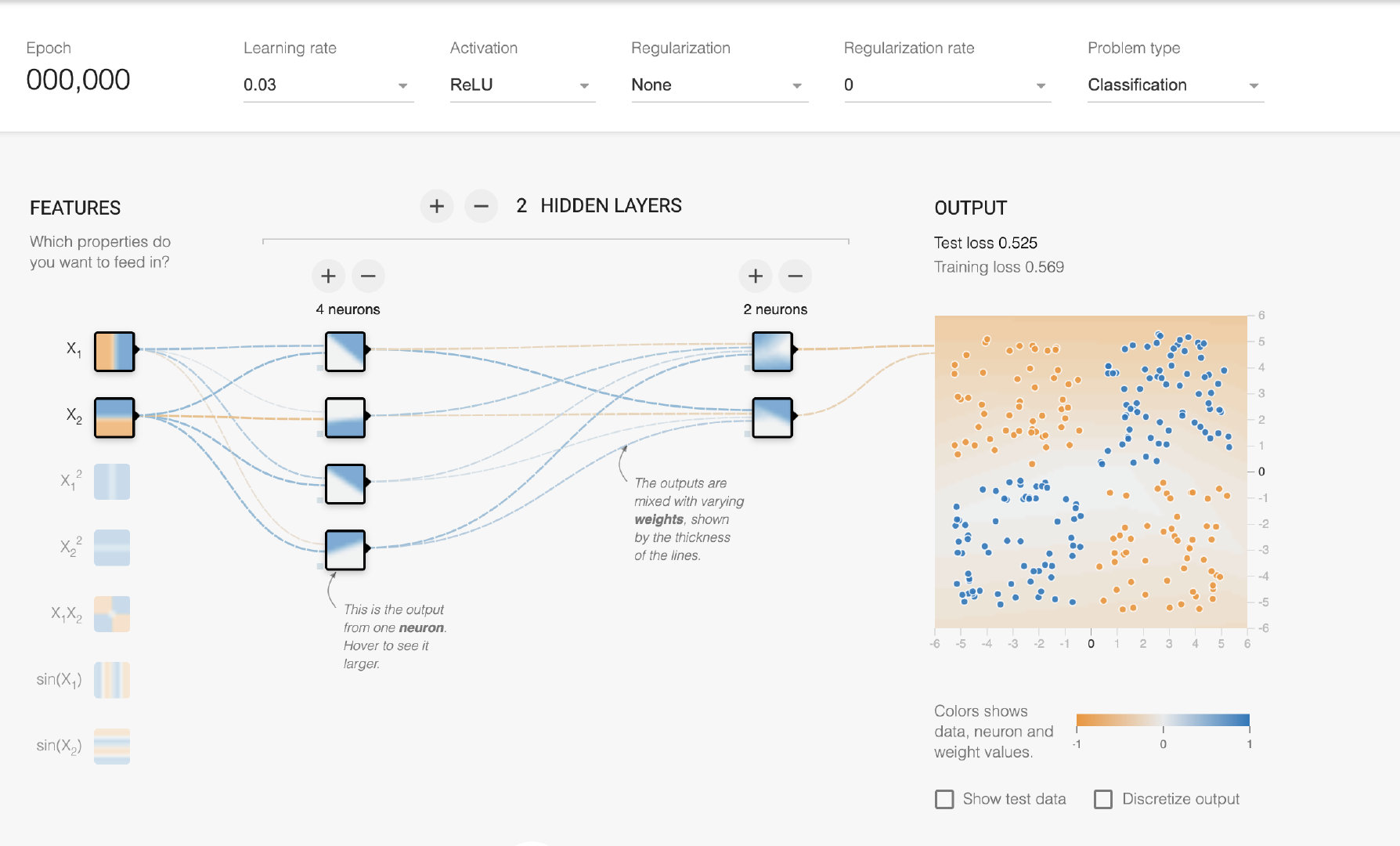
到这里,关于感知机的介绍就差不多结束了。感知机是神经网络的基础,其实也没有太多的内容,无论是结构上还是形式上都和之前机器学习介绍过的逻辑回归很近似,也没有太多技术难点和要点,大家只需要直观地感受就可以了。