本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
工欲善其事,必先利其器。
一项便捷且高效的语言对于数据工作者来说是至关重要的。
目前,数据科学绝大多数使用的是R、Python、Java、MatLab和SAS。
其中,尤为Python、R的使用最为广泛。

不过,Julia自2009年出现以来,凭借其速度、性能、易用性及语言的互操性等优势,已然掀起一股全新的浪潮。
最近,便有人使用Julia、Python和R对于CSV读取速度进行了基准测试。
其选用来3个不同的CSV解析器:
R的fread、Pandas的read_csv、Julia的CSV.jl
这三者分别在R,Python和Julia中被认为是同类CSV解析器中“最佳” 。
之后使用他们分别读取了8个不同真实数据集。
那么,测试的结果又是如何呢?让我们来一起看下。
同构数据集的性能
首先从同构数据集开始进行性能测试。
性能指标是随着线程数从1增加到20而加载数据集所花费的时间。
由于Pandas不支持多线程,因此报告中的所有数据均为单线程的速度。
浮点型数据集
第一个数据集包含以1000k行和20列排列的浮点值。
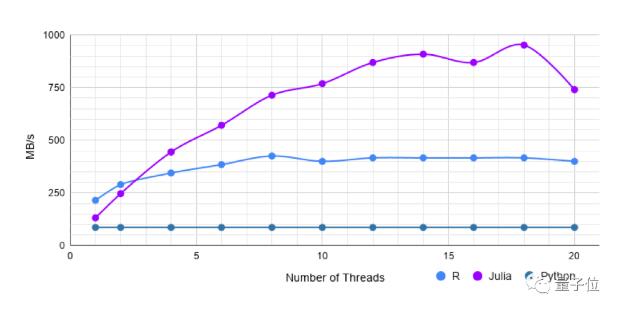
Pandas需要232毫秒来加载此文件。
首先在单线程下,data.table(fread)比CSV.jl快1.6倍。
而在使用多线程处理时,CSV.jl则表现得更好,是data.table速度的2倍以上。
单线程CSV.jl是没有多线程的Pandas(Python)的1.5倍,而多线程的CSV.jl可以达到11倍。
字符串数据集 I
此数据集在且具有1000k行和20列,并且所有列中不存在缺失值。
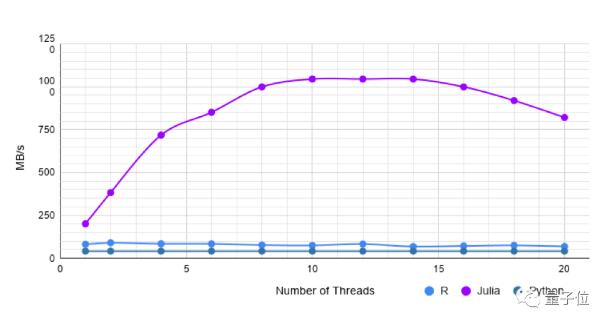
Pandas需要546毫秒来加载文件。
使用R,添加线程似乎不会导致任何性能提升。
单线程CSV.jl比data.table快2.5倍,而在10个线程中,CSV.jl则大约比data.table快14倍。
字符串数据集 II
该数据集的大小与字符串数据集 I 中相同。区别在于,其每一列是存在缺失值的。
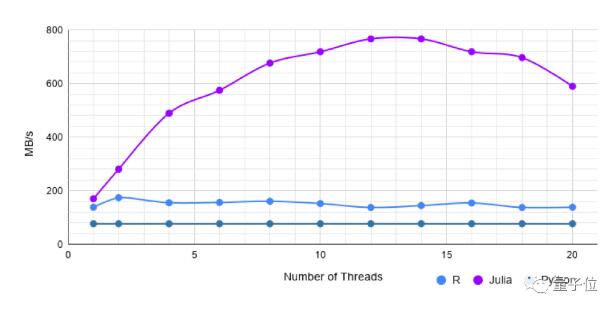
Pandas需要300毫秒。
单线程中,CSV.jl比R快1.2倍,而多线程相比,CSV.jl则快约5倍。
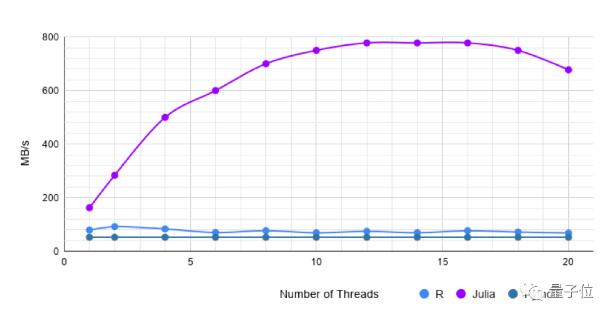
苹果股价数据集
该数据集包含50000k行和5列,大小为2.5GB。这些是AAPL股票的开盘价、最高价、最低价和收盘价。价格的四个列是浮点值,并且有一个列是日期。
单线程CSV.jl比从data.table中读取的R速度快约1.5倍。
而多线程,CSV.jl的速度提高了约22倍!
Pandas的read_csv需要34秒才能读取,这比R和Julia都要慢。
异构数据集的性能
接下来是关于异构数据集的性能测试。
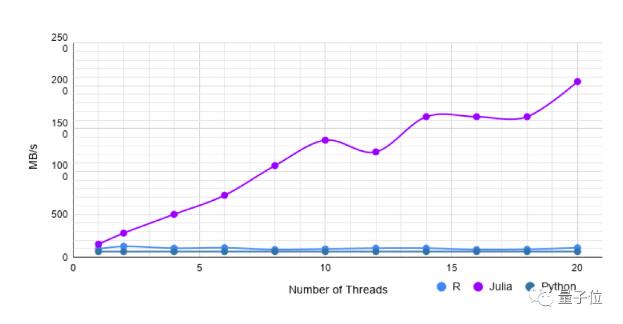
混合型数据集
此数据集具有10k行和200列。这些列包含的数据值类型有:String,Float,DateTime、Missing。
Pandas大约需要400毫秒来加载此数据集。
单线程中,CSV.jl比R快2倍,而使用10个线程则快了10倍。
按揭贷款风险数据集
从Kaggle取得的按揭贷款风险数据集是一种混合型的数据集,具有356k行和2190列。这些列是异构的,其数据值类型有:String、Int、Float、Missing。
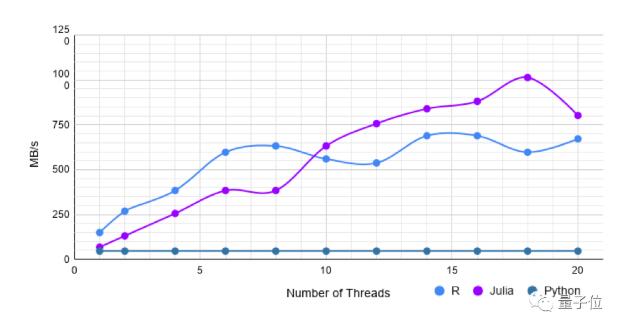
Pandas需要119秒才能读取此数据集。
单线程data.table读取大约比CSV.jl快两倍。
但是,使用更多线程,Julia的速度与R一样快或稍快。
宽数据集
这是一个相当宽的数据集,具有1000行和20k列。数据集包含的数据值类型有:String、Int。
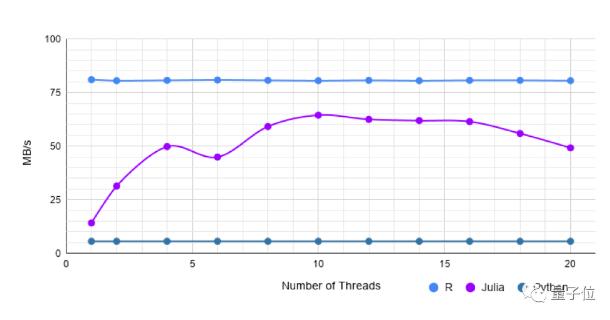
Pandas需要7.3秒才能读取数据集。
在这种情况下,单线程的data.table大约比CSV.jl快5倍。线程的增加,CSV.jl稍慢于R。
房利美收购数据集
从房利美网站上下载的数据集,有4000k行和25列,数据类型为:Int、String、Float,Missing。
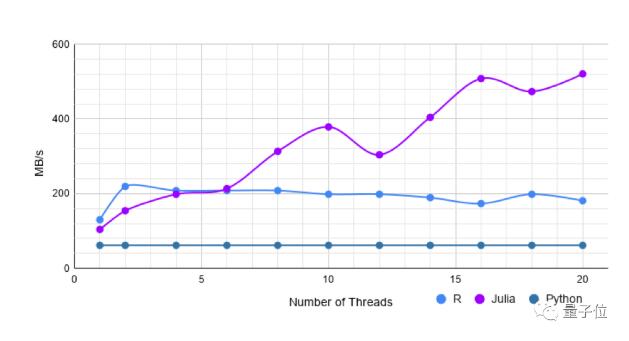
单线程data.table比CSV.jl快1.25倍。
但是,随着线程的增加,CSV.jl的性能不断提高。CSV.jl的多线程处理速度提高了约4倍。
总结
纵览8个测试:
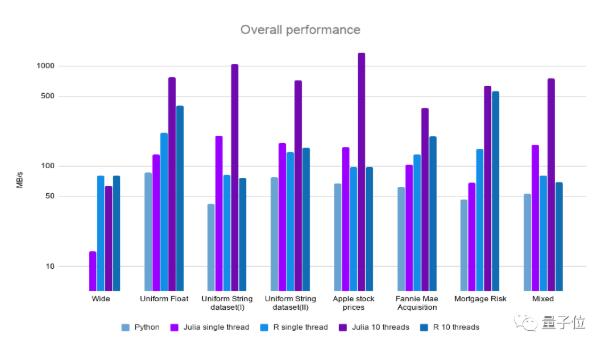
可以看出,在所有八个数据集中,Julia的CSV.jl总是比Pandas快,并且在多线程的情况下,它与R的data.table互有竞争。
可见,在CSV读取方面,Julia完全有能力与Python或和R竞争甚至做得更好。
此外,Julia的CSV.jl是独特的。
因为它是唯一直接以其高级语言完全实现功能的,这有别于先用C实现然后由R或Python工具进行封装。
因此,Julia代码的后续性能将有着更多的可能。
该项测试原文地址:
https://towardsdatascience.com/the-great-csv-showdown-julia-vs-python-vs-r-aa77376fb96
技术更新的讨论
在Julia,Python和R的测试中,引发了网友们更多关于“技术更新”的热烈讨论。
有些网友对于Julia给予了极大的期待:
在过去的十年中,大多数生态系统在Python上都具有巨大的价值,尤其是将MATLAB抛在脑后。
我认为从旧技术过渡到新技术的十年之久并不是一个糟糕的时标,甚至没有接近网络技术的翻版。
Julia对Python进行了足够的改进,可以保证在接下来的5-10年内进行转换,并以相同的方式将Python抛在后面。
不过,也有网友表达了对“更新重置成本”的担忧:
我认为Python的生态系统已经成熟,并且在过去的1-2年中已成为标准,这具有巨大的价值。
从头开始使用一种新语言(即使该语言可能稍好一些)会浪费很多精力。从Python2过渡到3已经是一场噩梦。
我知道Julia和Python之间存在一些互操作性,但是很多东西是无法互操作的,并且数组索引等方面存在令人讨厌的差异。
人们为什么不能仅仅依靠某种技术,使其成熟并享受越来越高的功能?为什么我们总是要撕毁一切并从头开始?