












为什么需要将服务器在地理位置上靠近用户? 原因之一是获得较低的延迟。 当您发送应尽快传送的短数据突发时,这很有意义。 但是,大文件(例如视频)呢? 接收第一个字节肯定会带来延迟损失,但是在那之后难道不是一帆风顺吗?
通过TCP(例如HTTP)发送数据时,常见的误解是带宽与延迟无关。 但是,对于TCP,带宽是延迟和时间的函数。 让我们看看如何。
握手
在客户端可以开始向服务器发送数据之前,它需要为TCP执行一次握手,为TLS执行一次握手。
TCP使用三向握手来创建新连接。
- 发送方选择一个随机生成的序列号" x",并将SYN数据包发送给接收方。
- 接收器递增" x",选择一个随机生成的序列号" y",然后发回SYN / ACK数据包。
- 发送方增加序列号,并用ACK数据包和应用程序数据的第一个字节进行回复。
TCP使用序列号来确保按顺序传送数据且没有空洞。

握手会引入完整的往返,这取决于基础网络的延迟。 TLS握手也最多需要两次往返。 在TLS连接打开之前,无法发送任何应用程序数据,这意味着在此之前您的带宽出于所有目的和目的均为零。 往返时间越短,建立连接的速度就越快。
流量控制
流控制是一种退避机制,旨在防止发送方压倒接收方。
接收器将等待应用程序处理的传入TCP数据包存储到接收缓冲区中。
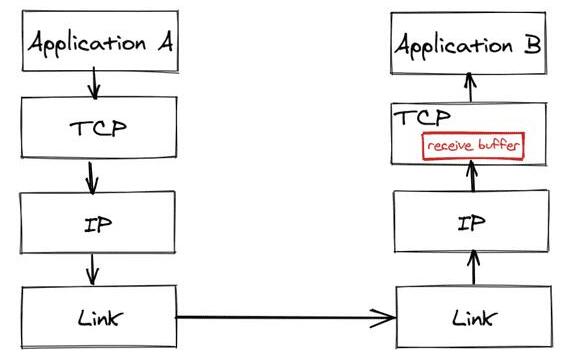
每当接收方确认数据包时,接收方还将其大小发送回发送方。 如果发件人遵守协议,则应避免发送更多可能容纳在收件人缓冲区中的数据。
此机制与应用程序级别的速率限制不太相似。 但是,TCP不是在API密钥或IP地址上进行速率限制,而是在连接级别上进行速率限制。
发送方和接收方之间的往返时间(RTT)越短,发送方将其出站带宽调整到接收方容量的速度就越快。
拥塞控制
TCP不仅可以防止接收器不堪重负,还可以防止淹没底层网络。
发送者如何找出底层网络的可用带宽是多少? 估计它的唯一方法是根据经验进行测量。
这个想法是发送者维护一个所谓的"拥塞窗口"。 该窗口表示无需等待对方的确认就可以发送的未完成数据包的总数。 接收器窗口的大小限制了拥塞窗口的最大大小。 拥塞窗口越小,在任何给定时间可以传输的字节越少,并且占用的带宽越少。
建立新连接后,拥塞窗口的大小将设置为系统默认值。 然后,对于每个确认的数据包,该窗口的大小都会成倍增加。 这意味着建立连接后,我们无法立即使用网络的全部容量。 同样,往返时间越短,发件人就可以越快地开始利用基础网络的带宽。
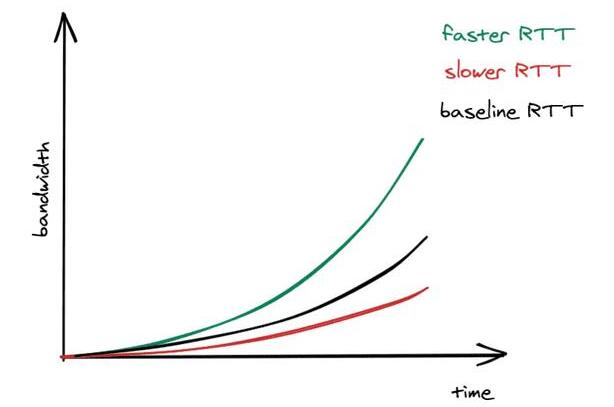
如果丢包怎么办? 当发件人通过超时检测到错过的确认时,就会启动一种称为"避免拥塞"的机制,从而减小拥塞窗口的大小。 从那时起,时间将窗口大小增加了一定数量,而超时又将窗口大小减少了一些。
如前所述,拥塞窗口的大小定义了无需等待确认即可发送的最大位数。 发件人需要等待完整的往返行程才能获得确认。 因此,通过将拥塞窗口的大小除以往返时间,可以得到最大的理论带宽:
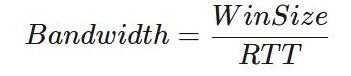
这个简单的方程式表明带宽是等待时间的函数。 TCP会尽力优化窗口大小,因为它无法解决往返时间。 但是,这并不总是能产生最佳配置。
总之,拥塞控制是一种自适应机制,用于推断网络的基础带宽和拥塞。 类似的模式也可以应用于应用程序级别。 想一想当您在Netflix上观看电影时会发生什么。 开始模糊; 然后,它会稳定到合理的水平,直到出现打ic为止,然后质量再次变差。 应用于视频流的这种机制称为自适应比特率流。
记住这一点
如果您使用的是HTTP,那么您将受基础协议的约束。 如果您不知道香肠的制作方法,就无法获得最佳性能。
突发请求受到冷启动惩罚。 可能需要多次往返,才能发送带有TCP和TLS握手的第一个字节。 而且由于拥塞控制的工作方式,往返时间越短,底层网络的带宽利用就越好。
关于此主题的所有书籍都已经写好了,您可以做很多事情来压缩每一盎司的带宽。 但是,如果您必须记住关于TCP的一件事,那就这样:
您发送数据的速度不能超过光速,但是您可以做的是使服务器离客户端更近,并重新使用连接以避免冷启动的代价。



























