












9 月 16 日晚上,我们将 FINN 的生产环境从本地数据中心迁移到了谷歌云平台(GCP)。这意味着要迁移一个高流量的网站,该网站由一个复杂的分布式系统支持,由 800 多个应用程序、145 个数据库和 16TB 数据组成。我们在夜间有规划的停机时间窗口,但这一窗口越小越好。我们是怎么做的?请继续阅读本文!
关于将 FINN.no 移出我们的数据中心,并迁移到云平台中的内部讨论始于多年前。此后,我们一直在尝试各种云技术和云提供商。当我们在 2016 年选择 Kubernetes 作为平台时,我们的指导思想就是在云平台中运行 FINN。
从很久前开始,我们在思想上已经准备好将系统迁移到云端了,但一直没有制定真正实现这一目标的策略或计划。我们产品的某些部件早在 1998 年就开始使用了,因此迁移它们是一项艰巨的任务。但是,随着数据中心愈加不堪重负、对更灵活解决方案的需求,以及我们去年成功将 Sybase 从 Solaris 迁移到 Linux 的经验,都给了我们很多动力来认真考虑这一计划。
我们从 2019 年 1 月开始评估各家云提供商。候选名单包括 AWS、Google Cloud、IBM Cloud 和 Azure。我们参加了很多研讨会、会议和电话会议,评估了自行管理服务以及将我们的服务托管于其他云提供商等许多选项,最终我们决定采用“多云”方案,而选择 GCP 作为我们大多数服务的首选项。该方案最终于 2019 年 8 月中旬被 Schibsted 批准。
1. 准备工作
迁移即将进行,我们必须制定一个计划,将我们拥有的一切转移到 GCP,同时保持 FINN 的正常运行。我们决定逐步迁移,使开发人员能够随着时间的推移迁移服务。但是,时间过得真快,我们意识到可用时间越来越少。基础架构的恶化、现有数据中心计划中的网络翻新以及资源的匮乏,使我们很难看到逐步迁移的成功前景。全球疫情大流行也让工作变得更困难了。我们被迫做出一些艰难的决定。
2020 年 6 月,我们了解到,我们需要采取更直接的方法,并确定向 GCP 迅速切换的日期。我们将目标日期定为 9 月 15 日,并获得了 FINN 管理小组批准,准许 FINN.no 停机一晚。7 月,云平台迁移被设置为 FINN 的第一要务;这意味着所有团队必须完成他们负责的所有与云平台迁移相关的工作,然后才能进行其他计划的任务。是时候该去(远程)工作了。
当我们决定放弃逐步迁移,决定快速切换时,摆在我们面前的艰巨任务就开始出现了。我们必须准备一个平台,使我们能够在一夜之间移动 800 多个应用、145 个数据库、超过 16TB 的数据以及 183 个虚拟机。FINN 的基础架构团队已经为云平台迁移做了很长时间的准备,但是这个决定使我们重新集中精力。现在,我们必须坚定地确定优先级,在必要时花时间深入探索技术,且始终保持目标清晰。在某些情况下,这意味着我们需要改变甚至放弃我们曾经投入大量时间的一些解决方案。
从夏天结束的那一刻起,我们就努力使这一计划取得成功。我们必须对我们需要花时间要做的事情和必须等待的事情做出艰难的选择。但是我们尽量不走捷径,坚持我们的原则,例如基础设施即代码。随着迁移日越来越近以及工作量的增加,我们的信心也随之增加。
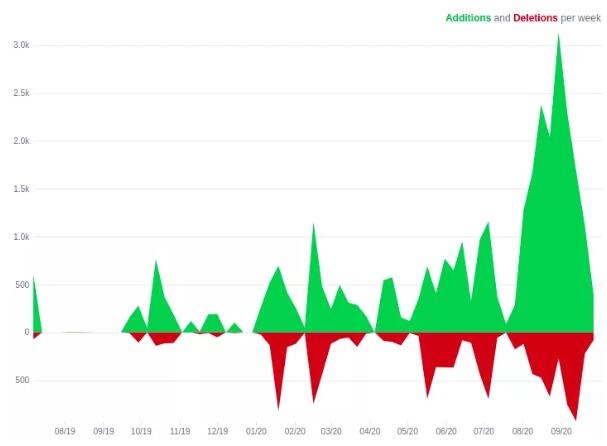
该图显示了随着切换时间的临近,我们用于维护 FINN 基础架构的一个存储库的更改频率不断增长
对 FINN.no 的更改通常每天实行约 350 次。在切换前的最后 24 小时,我们决定建议使用“发行冻结”,这意味着那些既不能解决实时生产问题,又不能解决与云平台迁移有关的更改应等到第二天。切换的前一天,更改频率降低到一半左右,并且在云平台切换开始前几分钟,最后一个产品部署到了我们的原有内部基础架构中。
2. 云平台切换
9 月 15 日 23:00 时,基础架构团队聚在一起(在线),准备就绪并检查切换前检查清单。由于每个人都在不同的地理位置,因此我们依靠详细的运行手册和视频会议进行协作。对 FINN.no 的更改通常在不停机的情况下进行部署,站点停机是 1 级严重事件。不过,这不是一个正常的星期二晚上。午夜时分,我们将用户重定向到静态后备页面后关闭了 FINN.no。半小时后,我们关闭了本地 Kubernetes 集群中的所有应用程序。

转换期间在 FINN.no 上显示的静态后备页面
然后我们准备迁移数据。Kafka 是我们微服务架构的基础之一。每天大约有 20 亿条消息(平均每秒 30,000 条)通过我们的 Kafka 集群,其稳定性对于 FINN 的正常运转至关重要。Kafka 小组迁移了我们的 Kafka 群集,该团队暂时以“延伸集群”配置运行该集群,将我们的本地数据中心和云平台作为单个集群。我们提前几周仔细计划和实施了延伸集群配置。Kafka 中的主题在切换前一周已复制到 GCP 的 broker 中,而 GCP 的 broker 在转换过程中成为主 broker。
需要持久存储的服务通常使用我们的 25 个 PostgreSQL 集群之一或我们的 Sybase 集群。我们通过预先在 GCP 中设置数据库副本,并在切换过程中所有应用程序停止后切换主数据库来迁移这些数据库集群。在切换当天的 01:35,Kafka 以及我们所有的 PostgreSQL 和 Sybase 数据库都运行在了 GCP 中。
移动持久数据后,我们触发了所有应用程序到新的 Google Container Engine(GKE)集群的部署。到 02:30,所有 800 个应用程序(超过 1500 个 Kubernetes 的 pod)都已部署到 GKE。至此,我们当晚只遇到了一些小的问题和延误,并已经准备好进行内部测试。
在切换之夜前,我们在所有领域的迁移准备和测试计划方面都做得非常出色,当午夜测试开始,看到绿灯亮起,我们的基础架构团队感到非常欣慰。对平台所有不同部分的自组织测试的效果甚至超出了我们的想象!
经过所有团队的良好团队合作,修复了一些应用部署、损坏的数据库表和其他一些小问题之后,云平台中的 FINN 于 04:43 启用,没有发生重大事故。
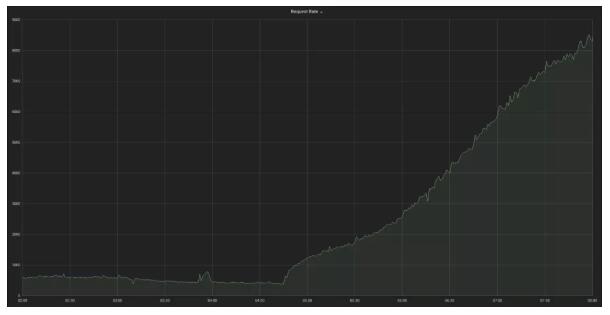
在 FINN.no 在云平台中于 04:43 启用后,通过某个负载均衡器的请求的速率增长曲线
我们为能够成功进行云平台切换而感到自豪!
没有 FINN Technology 的优秀人才,迁移不可能成功。我们在组织的各个部门都得到支持,当行动号召到来时,每个人都加入进来并做了应做的部分工作。在准备阶段,开发团队一直在努力处理防火墙、网络路由和负载平衡器,发现我们新的 GCP 基础架构中的问题,并与基础架构团队合作解决这些问题。在切换之夜的前几个星期,我们在工作时间还针对开发环境进行了转换演习。这次“排演”使我们充满信心,相信我们可以在指定的停机时间窗口内执行转换,帮助我们发现和纠正工具方面的问题,并且对于完善生产切换的运行手册非常有帮助。这两件事都有助于将风险降低到可接受的水平。
由于我们的迁移工作有一个硬期限,因此许多系统必须采用直接迁移方式进行移动。当我们稍微适应云环境时,我们期待将基础架构的这些部分也变得更加云原生化。












