












人工智能(AI)往往被视为一种暗箱实践,即人们并不关注技术本身的运作方式,只强调其能够提供看似正确的结果。在某些情况下,这种效果就已经可以满足需求,因为大多数时候我们都更关注结果,而非结果的具体实现方式。
遗憾的是,将AI视为暗箱过程会产生信任与可靠性等问题。从纯技术的角度来看,这也导致我们难以分析或解决AI模型中存在的问题。
在本文中,我们将共同了解其中的部分潜在问题以及几种解决方案思路。
AI是什么?
不少企业已经将人工智能(AI)元素纳入自家产品。虽然有些“AI”表述只是虚假的营销策略,但也确实有不少产品开始使用AI及机器学习(ML)技术实现自我提升。
简而言之,AI是指一切能够表现出智能行为的计算机系统。在本文的语境下,智能代表着计算机在学习、理解或者概念总结等层面的飞跃式进步。
当前,AI技术最常见的实现形式为机器学习,其中由计算机算法学习并识别数据中的模式。机器学习大致分为三类:
- 监督学习:即使用已知数据进行模型训练。这有点像给孩子们看最简单的看图识字教材。这类ML也是大家最常接触到的实现形式,但其有着一个致命缺点:只有具备大量可信且经过正确标记的训练数据,才能建立起相关模型。
- 无监督学习:模型自行在数据中查找模式。手机导航软件使用的就是这种学习方式,特别适合我们对数据一无所知的情况。目前业界往往使用无监督学习从数据中识别出可能具有现实意义的重要聚类。
- 强化学习:模型在每次正确执行时都会得到奖励。因为这是一种典型的“实验试错”学习方法。如果我们初期只有少量数据,那么这种ML方法将表现得尤为强大。它的出现,直接令持续学习模型成为可能,即模型在接触到新数据后会不断适应及发展,从而保证自身永不过时。
但这些方法都面临着同一个问题,我们无法理解学习后生成的最终模型。换言之,人工智能无法实现人性化。
信任问题
暗箱式AI系统大多属于由机器经过自学过程建立起模型。但由于无法理解系统得出结论的过程,我们就很难理解模型给出特定结论的理由,或者对该结论缺乏信心。我们无法询问模型为什么会这么判断,只能拿结果跟自己的期望进行比较。
如果不理解AI模型的起效原理,我们又怎么能相信模型会永远正确?
结果就是,这种不可理解性同无数反乌托邦科幻作品映射起来,让AI成了恐怖神秘的代名词。更糟糕的是,不少AI模型确实表现出严重的偏差,这也令信任危机被进一步激化。
偏差或者说偏见,一直植根于人类的思想意识当中,现在它也开始成为AI技术无法回避的大难题。因为系统只能从过往的情况中学习经验,而这些可能并不足以指导模型做出面向未来的正确选择。
以AI模型在犯罪预测中的应用为例,这些模型会使用以往犯罪统计数据来确定哪些地区的犯罪率比较高。执法部门则调整巡逻路线以向这些地区集中警力资源。但人们普遍质疑,使用这类数据本身就是在加强偏见,或者潜在地将相关性混淆为因果性。
例如,随着新冠疫情的肆虐,美国各大主要城市的暴力犯罪率开始显著下降;但在某些司法管辖区内,汽车盗窃及其他劫掠案件却有所增加。普通人可能会将这些变化与全国范围内的社交隔离合理联系起来,但预测性警务模型却有可能错误地将犯罪数量及逮捕率的降低解释为稳定性与治安水平的提升。
目前,人工智能中存在多种形式的偏见。以人脸识别软件为例,研究表明包含“人口统计学偏见”的算法会根据对象的年龄、性别或种族做出准确率波动极大的判断。
有时,数据科学家在执行特征工程以尝试清洗源数据时,同样会引发偏差/偏见问题,导致其中某些微妙但却极为重要的特征意外丢失。
影响最大的偏见甚至可能引发社会层面的问题。例如,广告算法会根据人口统计数据定期投放广告,从而将对于年龄、性别、种族、宗教或社会经济等因素的偏见永久留存在模型之内。AI技术在招聘应用中也暴露出了类似的缺陷。
当然,这一切都源自人类自己引发的原始偏见。但是,我们该如何在AI模型中发现这些偏见并将其清除出去?
可解释AI
为了增加对AI系统的信任度,AI研究人员正在探索构建可解释AI(XAI)的可能性,希望借此实现AI方案的人性化。
XAI能够避免我们在暗箱模型中难以识别的种种问题。例如,2017年研究人员的报告称发现了一项AI作弊问题。该AI模型在训练之后能够成功识别出马匹的图像,相当于对经典狗/猫识别能力的变体。但事实证明,AI学会的实际上是识别与马匹图片相关的特定版权标注。
为了实现XAI,我们需要观察并理解模型内部的整个运作过程。这项探索本身已经构成了理论计算机科学中的一大分支,其困难程度可能也远超大家的想象。
比较简单的机器学习算法当然相对易于解释,但神经网络则复杂得多。即使是包括分层相关性传播(LRP)在内的各类最新技术,也只能显示哪些输入对于决策制定更为重要。因此,研究人员的注意力开始转向本地可解释性目标,希望借此对模型做出的某些特定预测做出解释。
AI模型为什么难以理解?
目前,大多数ML模型基于人工神经元。人工神经元(或称感知器)使用传递函数对一个或多个加权输入进行组合。以此为基础,激活函数将使用阈值以决定是否触发。这种方法,实际上限制了神经元在人脑中的工作方式。
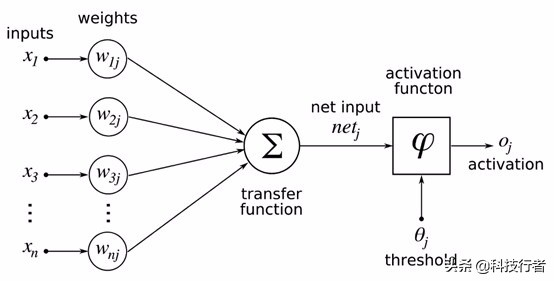
作为一种常见的ML模型,神经网络由多层人工神经元组成。输入层与重要特征拥有相同的输入数量,同时辅以大量隐藏层。最后,输出层也将拥有与重要特征相同的输出数量。
我们以最简单的应用场景为例,考虑ML模型如果根据今天是星期几及是否属于假期来预测您的起床时间。
在随机分配权重的情况下,模型会生成错误的结果,即我们周三需要在上午9点起床。
我们当然不可能以手动方式为每个人工神经元设置确切的权重。相反,我们需要使用所谓反向传播过程,算法将在模型中反向运作,借此调整网络的权重与偏差,力求将预测输出与预期输出间的差异控制在最小范围。在调整之后,结果是周三早上应该7点起床。
信任与道德
技术信任问题正变得愈发重要,毕竟我们已经在尝试使用AI诊断癌症、识别人群中的通缉犯并做出雇用/解雇决策。如果无法实现AI人性化,又怎么能要求人们向其给予信任呢?如果没有这种信任,以符合道德的方式加以使用更是痴人说梦。
对于这个重要问题,欧盟已经通过一套关于可信AI的道德准则,针对AI是否符合道德及具备可信度设置了七项测试:
- 人类代理与监督:AI系统不可在人类不具备最终决定权的情况下做出决策。
- 技术的健壮性与安全性:在使用AI技术之前,必须明确其是否可靠,包括具备故障保护能力且不会被黑客入侵。
- 隐私与数据治理:AI模型往往需要处理个人数据,例如通过医学造影图像诊断疾病。这意味着数据隐私将非常重要。
- 透明度:AI模型应该具备人类可解释的基本属性。
- 多样性、非歧视性与公平性:主要涉及我们前文讨论过的偏见问题。
- 环境与社会福祉:在这里,准则制定者们希望消除人们对于AI技术发展造成反乌托邦式未来的担忧。
- 问责制度:必须建立起独立的监督或监控制度。
当然,指南也强调,必须以合法方式使用AI技术。
AI的人性化之路
本文关注的重点只有一个:人工智能该如何实现人性化,从而切实建立起自身可信度。
人类很难相信自己无法理解的机器,并最终阻碍了我们从这一创新技术中切实受益。
这个问题在软件测试自动化领域表现得尤其明显,因为此类系统的意义就是在应用方案发布之前找到其中存在的潜在问题。如果不了解具体流程,我们要如何确定测试结果的正确性?如果做出了错误决定,该怎么办?如果AI系统遗漏了某些问题,我们该如何发现或者做出响应?
为了解决这个难题,必须将ML算法与测试体系结合起来,实现决策制定与相应数据间关联关系的可视化。只有这样,我们才能彻底告别暗箱式AI。这是一项踏踏实实的工作,没有奇迹、没有魔法,可以依赖的只有不懈努力与对机器学习美好未来的憧憬。














