看完本文可以掌握,以下几个方面:
- JavaScript的执行原理;
- 浏览器内核的真实结构;
- 浏览器渲染引擎的工作过程;
- V8引擎的工作原理;
- 浏览器和Node.js架构的区别和练习;
- Node.js架构的应用场景和REPL;
- Node.js架构的REPL使用;
PS:本篇文章为「Node.js系列」的第一篇,为邂逅Node.js。
之后会保持每周1~2篇的Node.js文章,欢迎大家和我一起学习大前端进阶系列。
题目中说到的V8引擎,大家自然会联想到Node.js。
我们先看一下官方对Node.js的定义:
Node.js是一个基于V8 JavaScript引擎的JavaScript运行时环境
但是这句话对于我们很多同学来说,非常笼统,比如先抛出这样几个问题:
- 什么是JavaScript运行环境?
- 为什么JavaScript需要特别的运行环境呢?
- JavaScript引擎又是什么呢?
- V8是什么?
上面这些问题,同学们理解的笼统没关系,这篇文章会依次揭晓答案~
我们先来吧这些概念搞清楚,再去看Node到底是什么?为什么大前端需要它。
JavaScript无处不在
Stack Overflow的创立者之一的 Jeff Atwood 在前些年提出了著名的Atwood定律:
- 任何可以使用JavaScript来实现的应用最终都会使用JavaScript实现。
在发明之处,JavaScript的目的是应用于在浏览器执行简单的脚本任务,对浏览器以及其中的DOM进行各种操作,所以JavaScript的应用场景非常受限。
但是随着Node的出现,Atwood定律已经越来越多的被证实是正确的。
但是为了可以理解Node.js是如何帮助我们做到这一点的,我们必须了解JavaScript是如何被运行的。
现在我们想一下,JavaScript代码在浏览器中是如何被执行的呢?
浏览器内核
不同的浏览器有不同的内核组成:
- Gecko:早期被Netscape和Mozilla Firefox浏览器使用;
- Trident:微软开发,被IE4~IE11浏览器使用,但是Edge浏览器已经转向Blink;
- Webkit:苹果基于KHTML开发、开源的,用于Safari,Google Chrome之前也在使用;
- Blink:是Webkit的一个分支,Google开发,目前应用于Google Chrome、Edge、Opera等;
- 等等...
事实上,我们经常说的浏览器内核指的是浏览器的排版引擎:
排版引擎(layout engine),也称为浏览器引擎(browser engine)、页面渲染引擎(rendering engine)或样板引擎。
介绍完浏览器的排版引擎之后,来介绍下浏览器的渲染引擎的工作过程。
渲染引擎工作的过程

浏览器渲染引擎的工作过程
如上图:
- HTML和CSS经过对应的Parser解析之后,会形成对应的DOM Tree和 CSS Tree;
- 它们经过附加合成之后,会形成一个Render Tree,同时生成一个Layout布局,最终通过浏览器的渲染引擎帮助我们完成绘制,展现出平时看到的Hmtl页面;
- 在HTML解析过程中,如果遇到了<script src='xxx'>,会停止解析HTML,而优先去加载和执行JavaScript代码(此过程由JavaScript引擎完成)
因为JavaScript属于高级语言(Python、C++、Java),所以JavaScript引擎会先把它转换成汇编语言,再把汇编语言转换成机器语言(二进制010101),最后被CPU所执行。
JavaScript引擎
为什么需要JavaScript引擎呢?
- 事实上我们编写的JavaScript无论你交给浏览器或者Node执行,最后都是需要被CPU执行的;
- 但是CPU只认识自己的指令集,实际上是机器语言,才能被CPU所执行;
- 所以我们需要JavaScript引擎帮助我们将JavaScript代码翻译成CPU指令来执行;
比较常见的JavaScript引擎有哪些呢?
- SpiderMonkey:第一款JavaScript引擎,由Brendan Eich开发(也就是JavaScript作者);
- Chakra:微软开发,用于IT浏览器;
- JavaScriptCore:WebKit中的JavaScript引擎,Apple公司开发;
- V8:Google开发的强大JavaScript引擎,也帮助Chrome从众多浏览器中脱颖而出;
上面我们介绍了JavaScript引擎和浏览器内核,但有的同学就该问了它们俩之间有什么联系呢和不同呢?
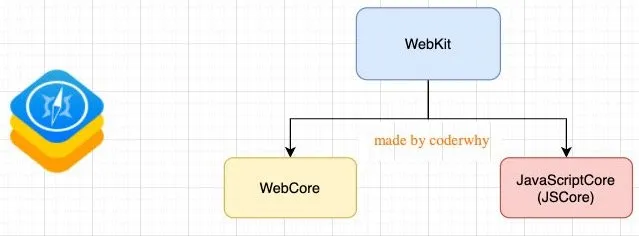
下面,我以WebKit内核为例。
WebKit内核
事实上WebKit内核由两部分组成的:
WebCore:负责HTML解析、布局、渲染等等相关的工作;
JavaScriptCore:解析、执行JavaScript代码(JavaScript引擎的工作)。
另外一个强大的JavaScript引擎就是V8引擎。
V8引擎
我们来看一下官方对V8引擎的定义:
- 支持语言:V8是用C ++编写的Google开源高性能JavaScript和WebAssembly引擎,它用于Chrome和Node.js等;
(译:V8可以运行JavaScript和WebAssembly引擎编译的汇编语言等)
- 跨平台:它实现ECMAScript和WebAssembly,并在Windows 7或更高版本,macOS 10.12+和使用x64,IA-32,
ARM或MIPS处理器的Linux系统上运行;
- 嵌入式:V8可以独立运行,也可以嵌入到任何C ++应用程序中;
V8引擎的工作原理
图解V8引擎的工作原理
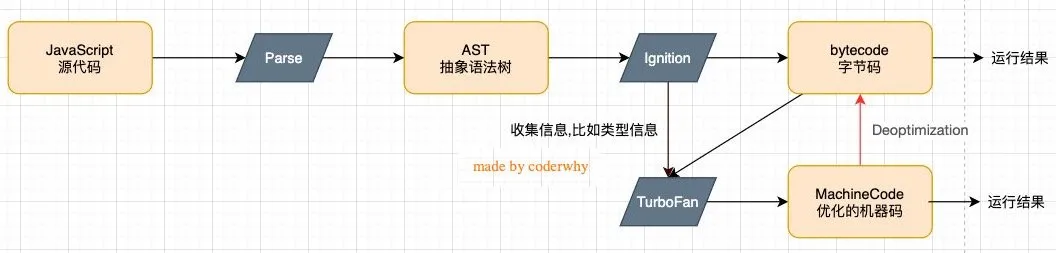
图解V8引擎的工作原理
其中的**Parse(解析器)、lgnition(解释器)、TurboFan(优化编译器)**都是V8引擎的内置模块
假如有这样一段JavaScript源代码:
- console.log("hello world");
- function sum(num1, num2) {
- return num1 + num2;
- }
- Parse模块会将JavaScript代码转换成AST(抽象语法树),这是因为解释器并不直接认识JavaScript代码;
- 如果函数没有被调用,那么是不会被转换成AST的;
- Parse的V8官方文档:https://v8.dev/blog/scanner
- Ignition是一个解释器,会将AST转换成ByteCode(字节码);
- 同时会收集TurboFan优化所需要的信息(比如函数参数的类型信息,有了类型才能进行真实的运算);
- 如果函数只调用一次,Ignition会执行解释执行ByteCode;
- Ignition的V8官方文档:https://v8.dev/blog/ignition-interpreter
- TurboFan是一个编译器,可以将字节码编译为CPU可以直接执行的机器码;
- 如果一个函数被多次调用,那么就会被标记为热点函数,那么就会经过TurboFan转换成优化的机器码,提高代码的执行性能;
- 但是,机器码实际上也会被还原为ByteCode,这是因为如果后续执行函数的过程中,类型发生了变化(比如sum函数原来执行的是number类型,后来执行变成了string类型),之前优化的机器码并不能正确的处理运算,就会逆向的转换成字节码;
- TurboFan的V8官方文档:https://v8.dev/blog/turbofan-jit
- 上面是JavaScript代码的执行过程,事实上V8的内存回收也是其强大的另外一个原因;
- Orinoco模块,负责垃圾回收,将程序中不需要的内存回收;
- Orinoco的V8官方文档:https://v8.dev/blog/trash-talk
- 关于V8引擎的垃圾内存回收机制,可以看下我之前整理的这篇文章「经典升华」V8引擎的垃圾内存回收机制
编程语言会大体分为两大类:
- 解释型语言:运行效率相对较低(比如JavaScript)
- 编译型语言:运行效率相对较高(比如C++)
上述情况对应的是JavaScript解释性语言的大体执行流程,但编译性语言往往不是,比如C++,例如系统内的某些应用程序用C++编写的,它们在执行的时候会直接转化为机器语言(二进制格式010101),并交给CPU统一执行,这样的运行效率自然相对较高了些。
但V8也对解释性的编程语言做了一个优化,就是上文提到的TurboFan优化编译器,如果一个JavaScript函数被多次调用,那么它就会经过TurboFan抓成优化后的机器码,交由CPU执行,提高代码的执行性能。
回顾:Node.js是什么
回顾:官方对Node.js的定义:
Node.js是一个基于V8 JavaScript引擎的JavaScript运行时环境。
也就是说Node.js基于V8引擎来执行JavaScript的代码,但是不仅仅只有V8引擎:
- 前面我们了解到V8可以嵌入到任何C ++应用程序中,无论是Chrome还是Node.js,事实上都是嵌入了V8引擎
来执行JavaScript代码;
- 但是在Chrome浏览器中,还需要解析、渲染HTML、CSS等相关渲染引擎,另外还需要提供支持浏览器操作
的API、浏览器自己的事件循环等,这些都是由浏览器内核帮我们完成的;
- 另外,在Node.js中我们也需要进行一些额外的操作,比如文件系统读/写、网络IO、加密、压缩解压文件等
PS:在后面的文章我们,我会带领大家逐步探索Node.js的世界...
浏览器和Node.js架构区别
简单对比一下Node.js和浏览器架构的差异:

浏览器和Node.js架构区别
- 在Chrome浏览器中
- 比如发送网络请求,中间层会调用操作系统中的网卡;
- 读取一些本地文件,中间层会调用操作系统中的硬盘;
- 浏览器页面的渲染工作,中间层会调用操作系统中的显卡;
- 等等...
- V8引擎只是其中的一小部分,用来辅助JavaScript代码的运行;
- 还有一些浏览器的内核用来负责HTML解析、布局、渲染等等相关的工作;
- 中间层和操作系统(网卡/硬盘/显卡...);
- 在Node中
- V8引擎;
- 中间层(libuv)包括EventLoop等;
- 操作系统(网卡/硬盘/显卡...);
Node.js架构
我们来看一个单独的Node.js的架构图:
- 我们编写的JavaScript代码会经过V8引擎,再通过Node.js的Bindings(Node.js API),将任务派发到Libuv的事件循环中;
- Libuv提供了事件循环、文件系统读写、网络IO、线程池等等内容;Libuv是使用C语言编写的库;
具体的内部代码执行流程,我会在后面的文章中专门讲解Node.js中的事件队列机制和异步IO的原理;
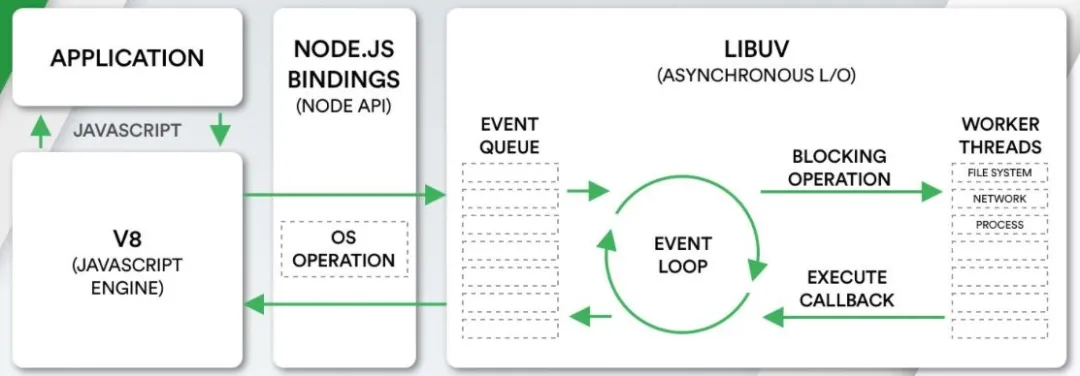
Node.js架构图
Node.js的应用场景
Node.js的快速发展也让企业对Node.js技术越来越重视。
那么它都有哪些实际的应用场景呢?
- 目前前端开发的库都是以node包的形式进行管理;
- npm、yarn工具成为前端开发使用最多的工具;
- 越来越多的公司使用Node.js作为web服务器开发;
- 大量项目需要借助Node.js完成前后端渲染的同构应用;
- 很多企业在使用Electron来开发桌面应用程序;
Node.js的REPL
什么是REPL呢?感觉挺高大上
- REPL是Read-Eval-Print Loop的简称,翻译为 “读取-求值-输出”循环;
- REPL是一个简单的、交互式的编程环境;
事实上,我们浏览器的console就可以看成一个REPL。
Node也给我们提供了一个REPL环境,我们可以在其中演练简单的代码。
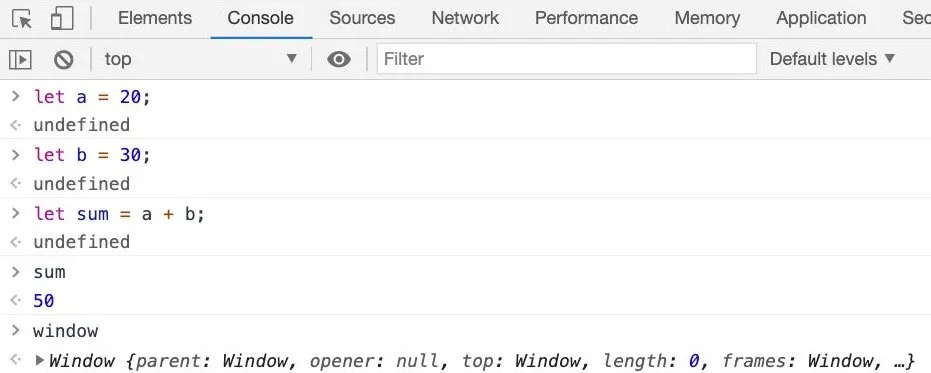
浏览器的REPL
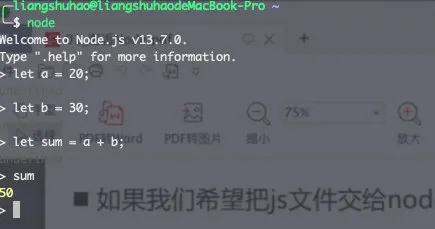
Node的REPL