












谷歌翻译大家想必都不陌生,但你有没有想过,它究竟是如何将几乎所有的已知语言翻译成我们所选择的语言?本文将解开这个谜团,并且向各位展示如何用长短期记忆网络(LSTM)构建语言翻译程序。
本文分为两部分。第一部分简单介绍神经网络机器翻译(NMT)和编码器-解码器(Encoder-Decoder)结构。第二部分提供了使用Python创建语言翻译程序的详细步骤。
什么是机器翻译?
机器翻译是计算语言学的一个分支,主要研究如何将一种语言的源文本自动转换为另一种语言的文本。在机器翻译领域,输入已经由某种语言的一系列符号组成,而计算机必须将其转换为另一种语言的一系列符号。
神经网络机器翻译是针对机器翻译领域所提出的主张。它使用人工神经网络来预测某个单词序列的概率,通常在单个集成模型中对整个句子进行建模。
凭借神经网络的强大功能,神经网络机器翻译已经成为翻译领域最强大的算法。这种最先进的算法是深度学习的一项应用,其中大量已翻译句子的数据集用于训练能够在任意语言对之间的翻译模型。

谷歌语言翻译程序
理解Seq2Seq架构
顾名思义,Seq2Seq将单词序列(一个或多个句子)作为输入,并生成单词的输出序列。这是通过递归神经网络(RNN)实现的。具体来说,就是让两个将与某个特殊令牌一起运行的递归神经网络尝试根据前一个序列来预测后一个状态序列。
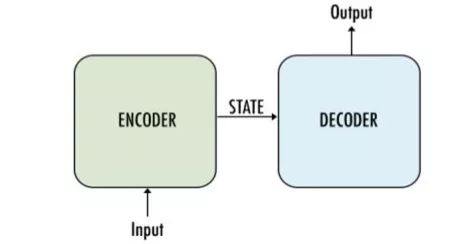
一种简单的编码器-解码器架构
它主要由编码器和解码器两部分构成,因此有时候被称为编码器-解码器网络。
· 编码器:使用多个深度神经网络层,将输入单词转换为相应的隐藏向量。每个向量代表当前单词及其语境。
· 解码器:与编码器类似。它将编码器生成的隐藏向量、自身的隐藏状态和当前单词作为输入,从而生成下一个隐藏向量,最终预测下一个单词。
任何神经网络机器翻译的最终目标都是接收以某种语言输入的句子,然后将该句子翻译为另一种语言作为输出结果。下图是一个汉译英翻译算法的简单展示:
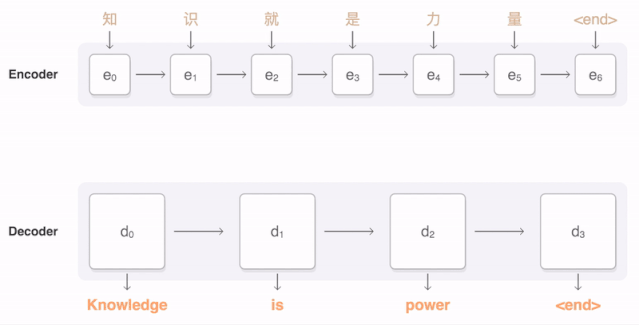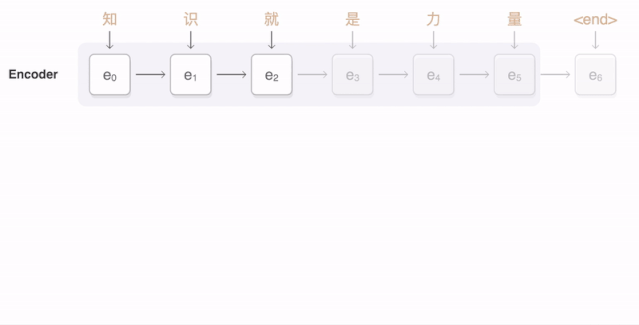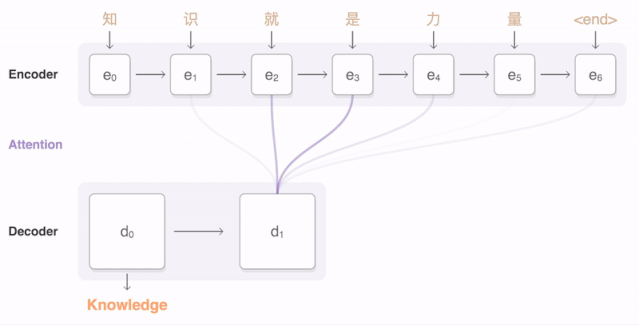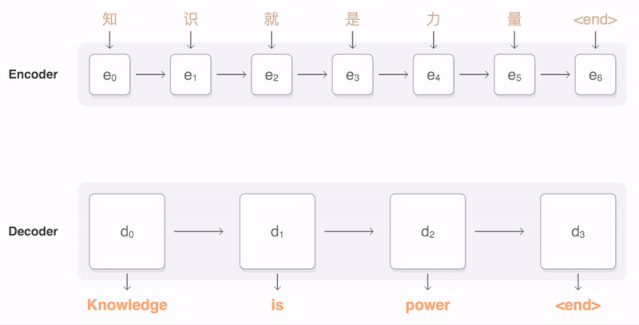
将“Knowledge ispower”翻译成汉语。
它如何运行?
第一步,通过某种方式将文本数据转换为数字形式。为了在机器翻译中实现这一点,需要将每个单词转换为可输入到模型中的独热编码(One Hot Encoding)向量。独热编码向量是在每个索引处都为0(仅在与该特定单词相对应的单个索引处为1)的向量。
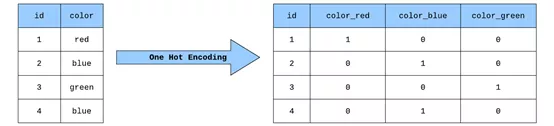
独热编码
为输入语言中的每个唯一单词设置索引来创建这些向量,输出语言也是如此。为每个唯一单词分配唯一索引时,也就创建了针对每种语言的所谓的“词汇表”。理想情况下,每种语言的词汇表将仅包含该语言的每个唯一单词。
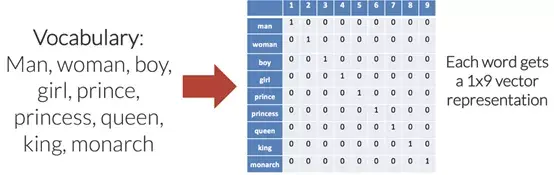
如上图所示,每个单词都变成了一个长度为9(这是词汇表的大小)的向量,索引中除去一个1以外,其余全部都是0。
通过为输入和输出语言创建词汇表,人们可以将该技术应用于任何语言中的任何句子,从而将语料库中所有已翻译的句子彻底转换为适用于机器翻译任务的格式。
现在来一起感受一下编码器-解码器算法背后的魔力。在最基本的层次上,模型的编码器部分选择输入语言中的某个句子,并从该句中创建一个语义向量(thought vector)。该语义向量存储句子的含义,然后将其传递给解码器,解码器将句子译为输出语言。

编码器-解码器结构将英文句子“Iam astudent”译为德语
就编码器来说,输入句子的每个单词会以多个连续的时间步分别输入模型。在每个时间步(t)中,模型都会使用该时间步输入到模型单词中的信息来更新隐藏向量(h)。
该隐藏向量用来存储输入句子的信息。这样,因为在时间步t=0时尚未有任何单词输入编码器,所以编码器在该时间步的隐藏状态从空向量开始。下图以蓝色框表示隐藏状态,其中下标t=0表示时间步,上标E表示它是编码器(Encoder)的隐藏状态[D则用来表示解码器(Decoder)的隐藏状态]。
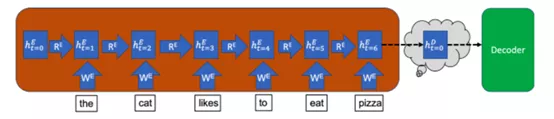
在每个时间步中,该隐藏向量都会从该时间步的输入单词中获取信息,同时保留从先前时间步中存储的信息。因此,在最后一个时间步中,整个输入句子的含义都会储存在隐藏向量中。最后一个时间步中的隐藏向量就是上文中提到的语义向量,它之后会被输入解码器。
另外,请注意编码器中的最终隐藏向量如何成为语义向量并在t=0时用上标D重新标记。这是因为编码器的最终隐藏向量变成了解码器的初始隐藏向量。通过这种方式,句子的编码含义就传递给了解码器,从而将其翻译成输出语言。但是,与编码器不同,解码器需要输出长度可变的译文。因此,解码器将在每个时间步中输出一个预测词,直到输出一个完整的句子。
开始翻译之前,需要输入<SOS>标签作为解码器第一个时间步的输入。与编码器一样,解码器将在时间步t=1处使用<SOS>输入来更新其隐藏状态。但是,解码器不仅会继续进行到下一个时间步,它还将使用附加权重矩阵为输出词汇表中的所有单词创建概率。这样,输出词汇表中概率最高的单词将成为预测输出句子中的第一个单词。
解码器必须输出长度可变的预测语句,它将以该方式继续预测单词,直到其预测语句中的下一个单词为<EOS>标签。一旦该标签预测完成,解码过程就结束了,呈现出的是输入句子的完整预测翻译。
通过Keras和Python实现神经网络机器翻译
了解了编码器-解码器架构之后,创建一个模型,该模型将通过Keras和python把英语句子翻译成法语。第一步,导入需要的库,为将在代码中使用的不同参数配置值。
- #Import Libraries
- import os, sys
- from keras.models importModel
- from keras.layers importInput, LSTM, GRU, Dense, Embedding
- fromkeras.preprocessing.text importTokenizer fromkeras.preprocessing.sequence import pad_sequences
- from keras.utils import to_categorical
- import numpy as np
- import pandas as pd
- import pickle
- importmatplotlib.pyplot as plt
- #Values fordifferent parameters: BATCH_SIZE=64
- EPOCHS=20
- LSTM_NODES=256
- NUM_SENTENCES=20000
- MAX_SENTENCE_LENGTH=50
- MAX_NUM_WORDS=20000
- EMBEDDING_SIZE=200
数据集
我们需要一个包含英语句子及其法语译文的数据集,下载fra-eng.zip文件并将其解压。每一行的文本文件都包含一个英语句子及其法语译文,通过制表符分隔。继续将每一行分为输入文本和目标文本。
- input_sentences = []
- output_sentences = [] output_sentences_inputs = [] count =0
- for line inopen('./drive/MyDrive/fra.txt', encoding="utf-8"):
- count +=1
- if count >NUM_SENTENCES:
- break
- if'\t'notin line:
- continue
- input_sentence = line.rstrip().split('\t')[0]
- output = line.rstrip().split('\t')[1]
- output_sentence = output +' <eos>'
- output_sentence_input ='<sos> '+ output
- input_sentences.append(input_sentence)
- output_sentences.append(output_sentence)
- output_sentences_inputs.append(output_sentence_input)
- print("Number ofsample input:", len(input_sentences))
- print("Number ofsample output:", len(output_sentences))
- print("Number ofsample output input:", len(output_sentences_inputs))
- Output:
- Number of sample input: 20000
- Number of sample output: 20000
- Number of sample output input: 20000
在上面的脚本中创建input_sentences[]、output_sentences[]和output_sentences_inputs[]这三个列表。接下来,在for循环中,逐个读取每行fra.txt文件。每一行都在制表符出现的位置被分为两个子字符串。左边的子字符串(英语句子)插入到input_sentences[]列表中。制表符右边的子字符串是相应的法语译文。
此处表示句子结束的<eos>标记被添加到已翻译句子的前面。同理,表示“句子开始”的<sos>标记和已翻译句子的开头相连接。还是从列表中随机打印一个句子:
- print("English sentence: ",input_sentences[180])
- print("French translation: ",output_sentences[180])
- Output:English sentence: Join us.French translation: Joignez-vous à nous.<eos>
标记和填充
下一步是标记原句和译文,并填充长度大于或小于某一特定长度的句子。对于输入而言,该长度将是输入句子的最大长度。对于输出而言,它也是输出句子的最大长度。在此之前,先设想一下句子的长度。将分别在两个单独的英语和法语列表中获取所有句子的长度。
- eng_len = []
- fren_len = [] # populate thelists with sentence lengths for i ininput_sentences:
- eng_len.append(len(i.split()))
- for i inoutput_sentences:
- fren_len.append(len(i.split()))
- length_df = pd.DataFrame({'english':eng_len, 'french':fren_len})
- length_df.hist(bins =20)
- plt.show()
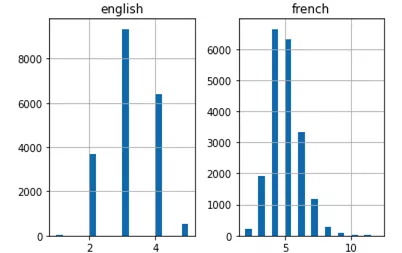
上面的直方图显示,法语句子的最大长度为12,英语句子的最大长度为6。
接下来,用Keras的Tokenizer()类矢量化文本数据。句子将因此变为整数序列。然后,用零填充这些序列,使它们长度相等。
标记器类的word_index属性返回一个单词索引词典,其中键表示单词,值表示对应的整数。最后,上述脚本打印出词典中唯一单词的数量和输入的最长英文句子的长度。
- #tokenize the input sentences(inputlanguage)
- input_tokenizer =Tokenizer(num_words=MAX_NUM_WORDS) input_tokenizer.fit_on_texts(input_sentences) input_integer_seq = input_tokenizer.texts_to_sequences(input_sentences) print(input_integer_seq)
- word2idx_inputs =input_tokenizer.word_index print('Total uniquewords in the input: %s'%len(word2idx_inputs))
- max_input_len =max(len(sen) for sen in input_integer_seq)
- print("Length oflongest sentence in input: %g"% max_input_len)
- Output:
- Total unique words in the input: 3501
- Length of longest sentence in input: 6
同样,输出语句也可以用相同的方式标记:
- #tokenize theoutput sentences(Output language)
- output_tokenizer =Tokenizer(num_words=MAX_NUM_WORDS, filters='')
- output_tokenizer.fit_on_texts(output_sentences+output_sentences_inputs) output_integer_seq =output_tokenizer.texts_to_sequences(output_sentences) output_input_integer_seq =output_tokenizer.texts_to_sequences(output_sentences_inputs) print(output_input_integer_seq)
- word2idx_outputs=output_tokenizer.word_index print('Total uniquewords in the output: %s'%len(word2idx_outputs))
- num_words_output=len(word2idx_outputs)+1
- max_out_len =max(len(sen) for sen inoutput_integer_seq)
- print("Length oflongest sentence in the output: %g"% max_out_len)
- Output:
- Total unique words in the output: 9511
- Length of longest sentence in the output: 12
现在,可以通过上面的直方图来验证两种语言中最长句子的长度。还可以得出这样的结论:英语句子通常较短,平均单词量比法语译文句子的单词量要少。
接下来需要填充输入。填充输入和输出的原因是文本的句子长度不固定,但长短期记忆网络希望输入的例句长度都相等。因此需要将句子转换为长度固定的向量。为此,一种可行的方法就是填充。
- #Padding theencoder input
- encoder_input_sequences =pad_sequences(input_integer_seq,maxlen=max_input_len) print("encoder_input_sequences.shape:",encoder_input_sequences.shape)
- #Padding thedecoder inputs decoder_input_sequences =pad_sequences(output_input_integer_seq,maxlen=max_out_len, padding='post')
- print("decoder_input_sequences.shape:",decoder_input_sequences.shape)
- #Padding thedecoder outputs decoder_output_sequences =pad_sequences(output_integer_seq,maxlen=max_out_len, padding='post')
- print("decoder_output_sequences.shape:",decoder_output_sequences.shape)
- encoder_input_sequences.shape: (20000, 6)
- decoder_input_sequences.shape: (20000, 12)
- decoder_output_sequences.shape: (20000, 12)
输入中有20000个句子(英语),每个输入句子的长度都为6,所以现在输入的形式为(20000,6)。同理,输出中有20000个句子(法语),每个输出句子的长度都为12,所以现在输出的形式为(20000,12),被翻译的语言也是如此。
大家可能还记得,索引180处的原句为join us。标记生成器将该句拆分为join和us两个单词,将它们转换为整数,然后通过对输入列表中索引180处的句子所对应的整数序列的开头添加四个零来实现前填充(pre-padding)。
- print("encoder_input_sequences[180]:",encoder_input_sequences[180])Output:
- encoder_input_sequences[180]: [ 0 0 0 0 464 59]
要验证join和us的整数值是否分别为464和59,可将单词传递给word2index_inputs词典,如下图所示:
- prnt(word2idx_inputs["join"])
- print(word2idx_inputs["us"])Output:
- 464
- 59
更值得一提的是,解码器则会采取后填充(post-padding)的方法,即在句子末尾添加零。而在编码器中,零被填充在开头位置。该方法背后的原因是编码器输出基于出现在句末的单词,因此原始单词被保留在句末,零则被填充在开头位置。而解码器是从开头处理句子,因此对解码器的输入和输出执行后填充。
词嵌入向量(Word Embeddings)
图源:unsplash
我们要先将单词转换为对应的数字向量表示,再将向量输入给深度学习模型。我们也已经将单词转化成了数字。那么整数/数字表示和词嵌入向量之间有什么区别呢?
单个整数表示和词嵌入向量之间有两个主要区别。在整数表示中,一个单词仅用单个整数表示。而在向量表示中,一个单词可以用50、100、200或任何你喜欢的维数表示。因此词嵌入向量可以获取更多与单词有关的信息。其次,单个整数表示无法获取不同单词之间的关系。而词嵌入向量却能做到这一点。
对于英语句子(即输入),我们将使用GloVe词嵌入模型。对于输出的法语译文,我们将使用自定义词嵌入模型。点击此处可下载GloVe词嵌入模型。
首先,为输入内容创建词嵌入向量。在此之前需要将GloVe词向量加载到内存中。然后创建一个词典,其中单词为键,其对应的向量为值:
- from numpy import array
- from numpy import asarray
- from numpy import zeros
- embeddings_dictionary=dict() glove_file =open(r'./drive/My Drive/glove.twitter.27B.200d.txt', encoding="utf8")
- for line in glove_file:
- rec = line.split() word= rec[0]
- vector_dimensions =asarray(rec[1:], dtype='float32')
- embeddings_dictionary[word] = vector_dimensions glove_file.close()
回想一下,输入中包含3501个唯一单词。我们将创建一个矩阵,其中行数代表单词的整数值,而列数将对应单词的维数。该矩阵将包含输入句子中单词的词嵌入向量。
- num_words =min(MAX_NUM_WORDS, len(word2idx_inputs)+1)
- embedding_matrix =zeros((num_words, EMBEDDING_SIZE)) for word, index inword2idx_inputs.items(): embedding_vector = embeddings_dictionary.get(word) if embedding_vector isnotNone: embedding_matrix[index] =embedding_vector
创建模型
第一步,为神经网络创建一个嵌入层。嵌入层被认为是网络的第一隐藏层。它必须指定3个参数:
· input_dim:表示文本数据中词汇表的容量。比如,如果数据被整数编码为0-10之间的值,那么词汇表的容量为11个单词。
· output_dim:表示将嵌入单词的向量空间大小。它决定该层每个单词的输出向量大小。比如,它可以是32或100,甚至还可以更大。如果大家对此有疑问,可以用不同的值测试。
· input_length:表示输入序列的长度,正如大家为Keras模型的输入层所定义的那样。比如,如果所有的输入文档都由1000个单词组成,那么该值也为1000。
- embedding_layer = Embedding(num_words, EMBEDDING_SIZE,weights=[embedding_matrix], input_length=max_input_len)
接下来需要做的是定义输出,大家都知道输出将是一个单词序列。回想一下,输出中唯一单词的总数为9511。因此,输出中的每个单词都可以是这9511个单词中的一个。输出句子的长度为12。每个输入句子都需要一个对应的输出句子。因此,输出的最终形式将是:(输入量、输出句子的长度、输出的单词数)
- #shape of the output
- decoder_targets_one_hot = np.zeros((len(input_sentences), max_out_len,num_words_output),
- dtype='float32'
- )decoder_targets_one_hot.shapeShape: (20000, 12, 9512)
为了进行预测,该模型的最后一层将是一个稠密层(dense layer),因此需要以独热编码向量的形式输出,因为我们将在稠密层使用softmax激活函数。为创建独热编码输出,下一步是将1分配给与该单词整数表示对应的列数。
- for i, d in enumerate(decoder_output_sequences):
- for t, word in enumerate(d):
- decoder_targets_one_hot[i, t,word] = 1
下一步是定义编码器和解码器网络。编码器将输入英语句子,并输出长短期记忆网络的隐藏状态和单元状态。
- encoder_inputs =Input(shape=(max_input_len,))
- x =embedding_layer(encoder_inputs) encoder =LSTM(LSTM_NODES, return_state=True)
- encoder_outputs,h, c =encoder(x) encoder_states = [h, c]
下一步是定义解码器。解码器将有两个输入:编码器的隐藏状态和单元状态,它们实际上是开头添加了令牌后的输出语句。
- decoder_inputs =Input(shape=(max_out_len,))
- decoder_embedding =Embedding(num_words_output,LSTM_NODES) decoder_inputs_x =decoder_embedding(decoder_inputs) decoder_lstm =LSTM(LSTM_NODES,return_sequences=True, return_state=True)
- decoder_outputs, _, _ =decoder_lstm(decoder_inputs_x,initial_state=encoder_states) #Finally, theoutput from the decoder LSTM is passed through a dense layer to predict decoderoutputs.
- decoder_dense =Dense(num_words_output,activation='softmax')
- decoder_outputs =decoder_dense(decoder_outputs)
训练模型
编译定义了优化器和交叉熵损失的模型。
- #Compile
- model =Model([encoder_inputs,decoder_inputs],decoder_outputs)
- model.compile(
- optimizer='rmsprop',
- loss='categorical_crossentropy',
- metrics=['accuracy']
- )
- model.summary()
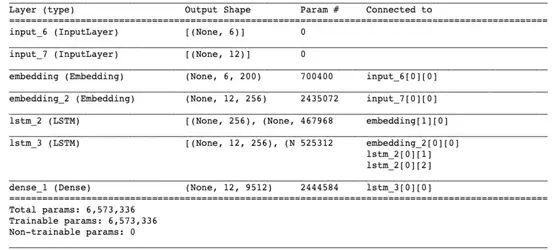
结果在意料之中。编码器lstm_2接受来自嵌入层的输入,而解码器lstm_3使用编码器的内部状态及嵌入层。该模型总共有大约650万个参数!训练模型时,笔者建议指定EarlyStopping()的参数,以避免出现计算资源的浪费和过拟合。
- es =EarlyStopping(monitor='val_loss', mode='min', verbose=1)
- history = model.fit([encoder_input_sequences,decoder_input_sequences], decoder_targets_one_hot, batch_size=BATCH_SIZE, epochs=20,
- callbacks=[es], validation_split=0.1,
- )
保存模型权重。
- model.save('seq2seq_eng-fra.h5')
绘制训练和测试数据的精度曲线。
- #Accuracy
- plt.title('model accuracy')
- plt.plot(history.history['accuracy'])
- plt.plot(history.history['val_accuracy'])
- plt.ylabel('accuracy')
- plt.xlabel('epoch')
- plt.legend(['train', 'test'], loc='upper left')
- plt.show()
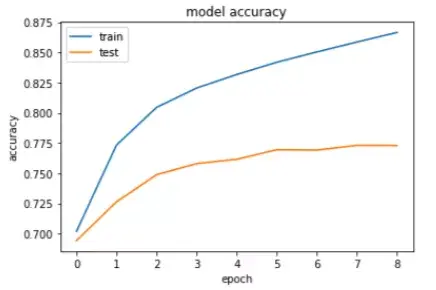
如大家所见,该模型达到了约87%的训练精度和约77%的测试精度,这表示该模型出现了过拟合。我们只用20000条记录进行了训练,所以大家可以添加更多记录,还可以添加一个dropout层来减少过拟合。
测试机器翻译模型
加载模型权重并测试模型。
- encoder_model = Model(encoder_inputs, encoder_states)
- model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
- model.load_weights('seq2seq_eng-fra.h5')
设置好权重之后,是时候通过翻译几个句子来测试机器翻译模型了。推理模式的工作原理与训练过程略有不同,其过程可分为以下4步:
· 编码输入序列,返回其内部状态。
· 仅使用start-of-sequence字符作为输入,并使用编码器内部状态作为解码器的初始状态来运行解码器。
· 将解码器预测的字符(在查找令牌之后)添加到解码序列中。
· 将先前预测的字符令牌作为输入,重复该过程,更新内部状态。
由于只需要编码器来编码输入序列,因此我们将编码器和解码器分成两个独立的模型。
- decoder_state_input_h =Input(shape=(LSTM_NODES,))
- decoder_state_input_c=Input(shape=(LSTM_NODES,)) decoder_states_inputs=[decoder_state_input_h, decoder_state_input_c] decoder_inputs_single=Input(shape=(1,))
- decoder_inputs_single_x=decoder_embedding(decoder_inputs_single) decoder_outputs,h, c =decoder_lstm(decoder_inputs_single_x, initial_state=decoder_states_inputs) decoder_states = [h, c] decoder_outputs =decoder_dense(decoder_outputs) decoder_model =Model( [decoder_inputs_single] +decoder_states_inputs, [decoder_outputs] + decoder_states
我们想让输出内容为法语的单词序列。因此需要将整数转换回单词。我们将为输入和输出创建新词典,其中键为整数,对应的值为单词。
- idx2word_input = {v:k for k, v inword2idx_inputs.items()}
- idx2word_target = {v:k for k, v inword2idx_outputs.items()}
该方法将接受带有输入填充序列的英语句子(整数形式),并返回法语译文。
- deftranslate_sentence(input_seq):
- states_value = encoder_model.predict(input_seq) target_seq = np.zeros((1, 1))
- target_seq[0, 0] =word2idx_outputs['<sos>']
- eos = word2idx_outputs['<eos>']
- output_sentence = [] for _ inrange(max_out_len):
- output_tokens, h, c = decoder_model.predict([target_seq] + states_value) idx = np.argmax(output_tokens[0, 0, :])
- if eos == idx:
- break
- word =''
- if idx >0:
- word =idx2word_target[idx] output_sentence.append(word) target_seq[0, 0] = idx
- states_value = [h, c] return' '.join(output_sentence)
预测
为测试该模型性能,从input_sentences列表中随机选取一个句子,检索该句子的对应填充序列,并将其传递给translate_sentence()方法。该方法将返回翻译后的句子。
- i = np.random.choice(len(input_sentences))
- input_seq=encoder_input_sequences[i:i+1]
- translation=translate_sentence(input_seq) print('Input Language: ', input_sentences[i])
- print('Actualtranslation : ', output_sentences[i])
- print('Frenchtranslation : ', translation)
结果:

很成功!该神经网络翻译模型成功地将这么多句子译为了法语。大家也可以通过谷歌翻译进行验证。当然,并非所有句子都能被正确翻译。为进一步提高准确率,大家可以搜索“注意力”机制(Attention mechanism),将其嵌入编码器-解码器结构。
图源:unsplash
大家可以从manythings.org上面下载德语、印地语、西班牙语、俄语、意大利语等多种语言的数据集,并构建用于语言翻译的神经网络翻译模型。
神经机器翻译(NMT)是自然语言处理领域中的一个相当高级的应用,涉及非常复杂的架构。本文阐释了结合长短期记忆层进行Seq2Seq学习的编码器-解码器模型的功能。编码器是一种长短期记忆,用于编码输入语句,而解码器则用于解码输入内容并生成对应的输出内容。




















