












Facebook已经建立并正在共享Dynabench,这是第一个用于人工智能领域的动态数据收集和基准测试平台。它使用人类测试和模型一起循环迭代,目的是为了创造具有挑战性的新数据并且更优化的人工智能模型。
人工智能在过去十年左右的巨大成功通常归功于大量的数据和计算能力,但是「基准测试」在推动进步方面也发挥着至关重要的作用。
为了提高SOTA结果,研究人员需要一种方法来比较他们的模型与同行开发的模型的效果差异。准确的比较是验证新模型确实优于该领域现有模型的先决条件这个过程被称为「基准测试」,即Benchmark。
研究人员可以利用人工智能进行对比测试,看看它到底有多先进。例如,ImageNet,一个由1400万张图像组成的公共数据集,为图像识别设定了目标。MNIST 在自然语言处理方面对手写数字识别和 GLUE (通用语言理解评估)做了同样的工作,导致了诸如 GPT-3这样的突破性语言模型的出现。
基准测试已经越来越快地达到饱和,尤其是在自然语言处理(NLP)领域。虽然研究团队花了大约18年时间才在 MNIST 上取得了人类水平的表现,并在 ImageNet 上花了大约6年时间才超过人类,但在 GLUE 语言理解基准上只花了大约一年时间就超过了人类。
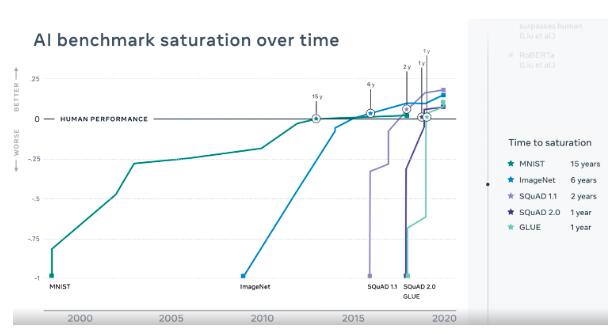
固定的目标很快就会被超越。ImageNet 在更新中,GLUE 也已经被 SuperGLUE 取代,后者是一系列更困难的语言任务。
尽管如此,研究人员迟早会报告说,他们的人工智能已经达到了超越人类的水平,在这个或那个挑战中胜过人类。如果我们希望「基准」继续推动算法和模型进步,这就是一个亟待解决的问题。
Dynabench:新的动态对抗性benchmark
Facebook 正在发布一种新的测试方法,让人工智能与竭尽全力干扰它们的人类进行比较,希望辅助研究人员开发出更强大的NLP模型。这项测试基准名为「 Dynabench」,它将根据人们的选择来进行变化,解决目前基准测试方法的不足,并促进更健壮的人工智能软件的开发。
Dynabench的解决方案是通过将人工测试带入这个流程来部分地实现基准测试过程。这个想法就是基于人类可以更准确地评估一个模型的准确性,而不是一组预先包装好的测试问题,可以为神经网络提出更难,更有创造性的挑战。
这是一个比当前静态基准更好的模型测量指标,将更好地反映人工智能模型在最重要的情况下的表现: 当与人交流时,他们的行为和反应都是复杂的,不断变化的方式,而这些方式无法在一组固定的数据点中反映出来。
「现有的Benchmarks可能非常具有误导性」,Facebook 人工智能研究所的 Douwe Kiela 说,他领导了这个工具的开发团队,「过分关注基准可能意味着忽视更广泛的目标」,从而导致「the test become the task」
静态基准测试-忽略了与人交互的体验
静态的基准测试迫使模型过多地关注一个特定的东西,而我们最终关心的不是某个特定的度量或任务,而是人工智能系统在与人交互时能做到多好。
人工智能的真正衡量标准不应该是准确度或困惑度,而应该是直接或者间接建立与人交流时的模型误差率。
Kiela认为这是NLP目前面临的一个特殊问题。GPT-3这样的语言模型之所以具有智能性,是因为它非常擅长模仿语言,但是很难说这些系统到底能理解多少。
就像做智力测试一样,可以给人们做智商测试,但是这并不能告诉你他们是否真的掌握了一个主题。为了做到这一点,你需要和他们进行交谈,问问题。
就像一个学生只记住了一大堆事实,这种策略也许在笔试中可以取得优异的成绩,但是在面试中提出的创造性和意料之外的问题,这种策略就不那么有效了。
Dynabench 做了类似的事情,「用人来审问人工智能」。
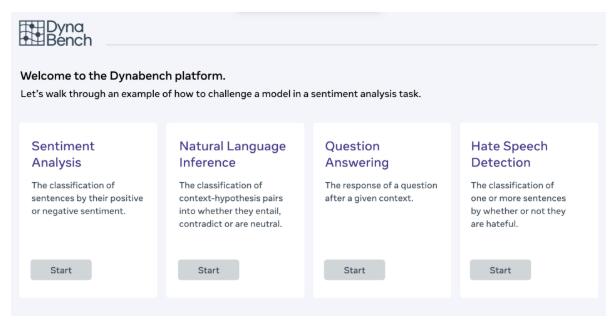
Facebook也已经发布了一个网页,邀请感兴趣的人去网站来测试背后它的模型。例如,你可以给语言模型一个 Wikipedia 页面,然后问它问题,给它的答案打分。
在某些方面,这个想法类似于人们已经在使用GPT-3的方式,来测试它的极限。或者是聊天机器人评估 Loebner Prize的方式,又或者是类似图灵测试的方式。
当人工智能完成一轮测试后,Dynabench 识别出那些愚弄模型的问题,并将它们编译成一个新的测试集。
研究人员可以利用这个测试集来帮助他们建立更新、更复杂的模型。然后,一旦开发出一个模型,就可以回答第一个人工智能无法回答的问题,Dynabench不断重复这个过程,并编译另一个测试数据集与更难的问题。
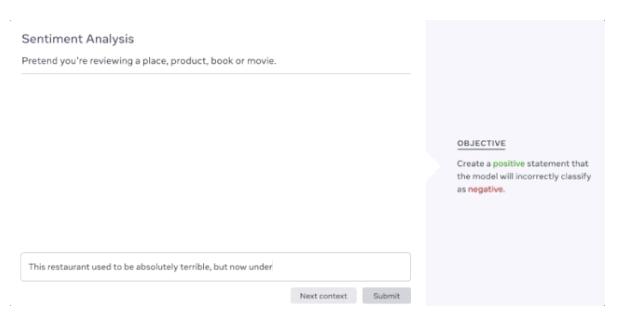
目前 Dynabench 将专注于语言模型,因为它是人类最容易理解的AI模型之一。「每个人都会说一种语言」,Kiela说,「你不需要任何关于如何妨碍这些模型的真正知识。」
该方法也适用于其他类型的神经网络,如语音或图像识别系统。Kiela 说,你只需要找到一种方法,让人们上传自己的图片,或者让他们画些东西来测试它。Facebook的长期的愿景是开放Dynabench,这样任何人都可以开发自己的模型,收集自己的数据。
Facebook希望让AI界相信,会有一种更好的方法来测试NLP模型,这会使得模型和算法能够更快的进步,并且真正的提升与人类交互时的体验和真正的理解交互内容。




















