许多开发人员在编程过程中碰到问题,首选都是打开浏览器,搜索问题,并尝试找出答案,现在,有一个神器可以让你不用这么麻烦了。
这个名为codequestion的神器,是一个基于archive.org上的Stack Exchange Dump构建的。使用来自Stack Exchange的数据,codequestion针对预先训练的模型在本地运行。
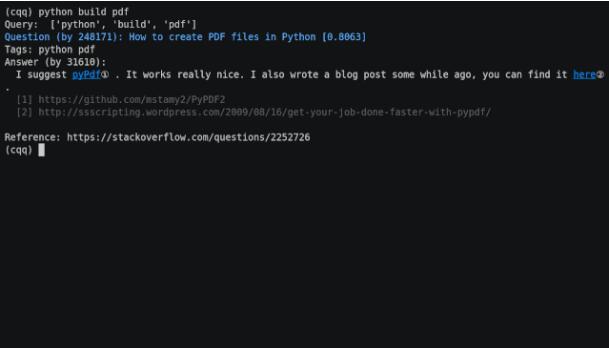
安装后你无需网络连接,你只需要在终端输入问题,就可以得到答案,搜索出来的结果和你在浏览器上搜索的没有什么两样。
目前,codequestion知道的人并不是很多,只获得 117 个Star,累计分支 11 个(Github地址:https://github.com/neuml/codequestion),下面一起来看看具体使用方法:
安装方式
最简单的安装方式是通过pip和PyPI:
- pip install codequestion
你也可以直接从GitHub安装codequestion。建议使用Python虚拟环境,支持Python 3.6+:
- pip install git+https://github.com/neuml/codequestion
下载模型
一旦安装了Codequestion,就需要下载模型。
- python -m codequestion.download
该模型将存储在〜/ .codequestion /中,预训练的模型可以从Github详情页面获取
- $ git reset --hard
可以自定义代码问题以针对自定义的问题解答存储库运行,目前,仅支持Stack Exchange模型。
运行查询
运行查询最快的方法是启动一个codequestion shell
- $ git reset --hard
技术原理
原始数据转储处理:codequestion的运行原理是怎样的呢?首先是原始数据转储处理,来自Stack Exchange库的原始7z XML转储通过一系列步骤进行处理。仅检索得分高且得分高的问题存储,问题和答案被合并到一个名为questions.db的SQLite文件中。questions.db的模式如下:
- $ git reset --hard
索引编制:codequestion工具为questions.db建立了一个句子嵌入索引。单词嵌入模型是基于questions.db构建的自定义fastText模型。一旦将每个标记转换为单词嵌入,就会创建加权句子嵌入。词嵌入使用BM25索引对资源库中的所有token进行加权。但有一个重要的修改:标签被用来提升标签标记的权重。将questions.db转换为句子嵌入的集合后,会将它们标准化并存储在Faiss中,从而可以进行快速相似性搜索。
查询方式:codequestion使用与索引相同的方法对每个查询进行标记。这些标记用于构建句子嵌入。针对Faiss索引查询该嵌入,以找到最相似的问题。
除此之外,创建者还在Github项目详情页介绍了如何使用Stack Exchange构建代码问题模型。感兴趣的伙伴们赶紧收藏。