












本文转载自微信公众号「Java极客技术」,作者鸭血粉丝 。转载本文请联系Java极客技术公众号。
网络爬虫技术,早在万维网诞生的时候,就已经出现了,今天我们就一起来揭开它神秘的面纱!
一、摘要
说起网络爬虫,相信大家都不陌生,又俗称网络机器人,指的是程序按照一定的规则,从互联网上抓取网页,然后从中获取有价值的数据,随便在网上搜索一下,排在前面基本都是 pyhton 教程介绍。
的确,pyhton 在处理网页方面,有着开发简单、便捷、性能高效的优势!
但是我们 java 也不赖,在处理复杂的网页方面,需要解析网页内容生成结构化数据或者对网页内容精细的解析时,java 可以说更胜一筹!
下面我们以爬取国家省市区信息为例,使用 java 技术来实现,过程主要分三部:
- 第一步:目标网页分析
- 第二步:编写爬虫程序,对关键数据进行抓取
- 第三步:将抓取的数据写入数据库
废话不多说,直接开撸!
二、网页分析
网络爬虫,其实不是一个很难的技术,只是需要掌握的技术内容比较多,只会 java 技术是远远不够,还需要熟悉 html 页面属性!
以爬取国家省市区信息为例,我们可以直接在百度上搜索国家省市区,点击进入全国行政区划信息查询平台。
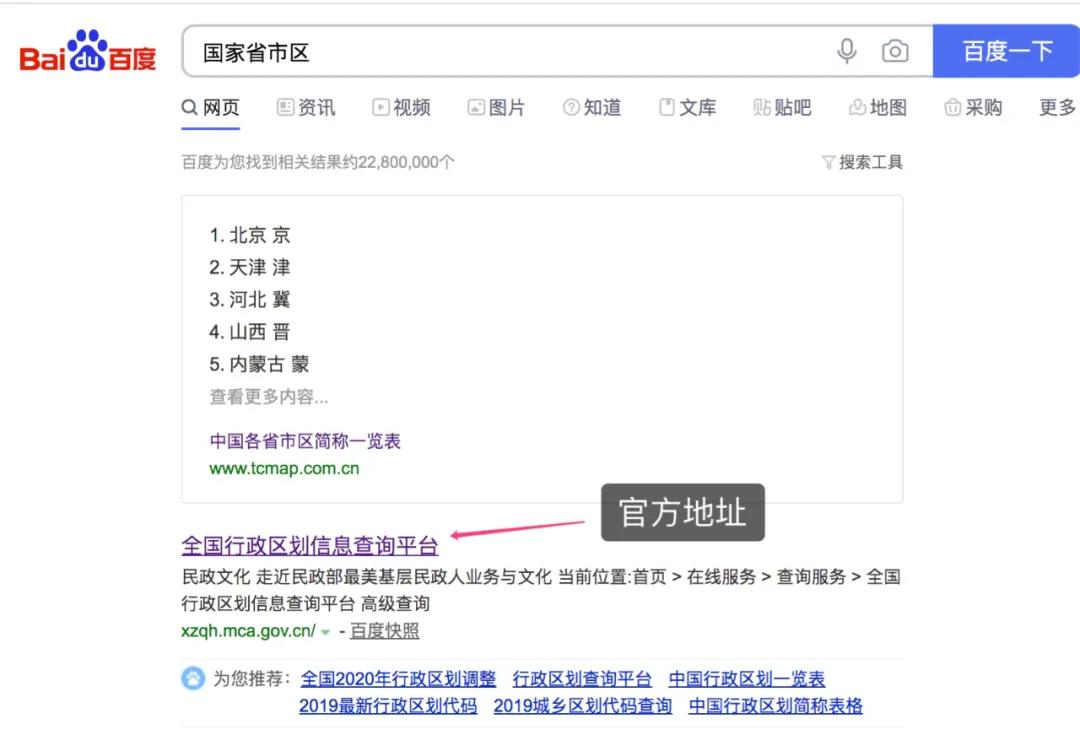
在民政数据菜单栏下,找到最新的行政区域代码公示栏。
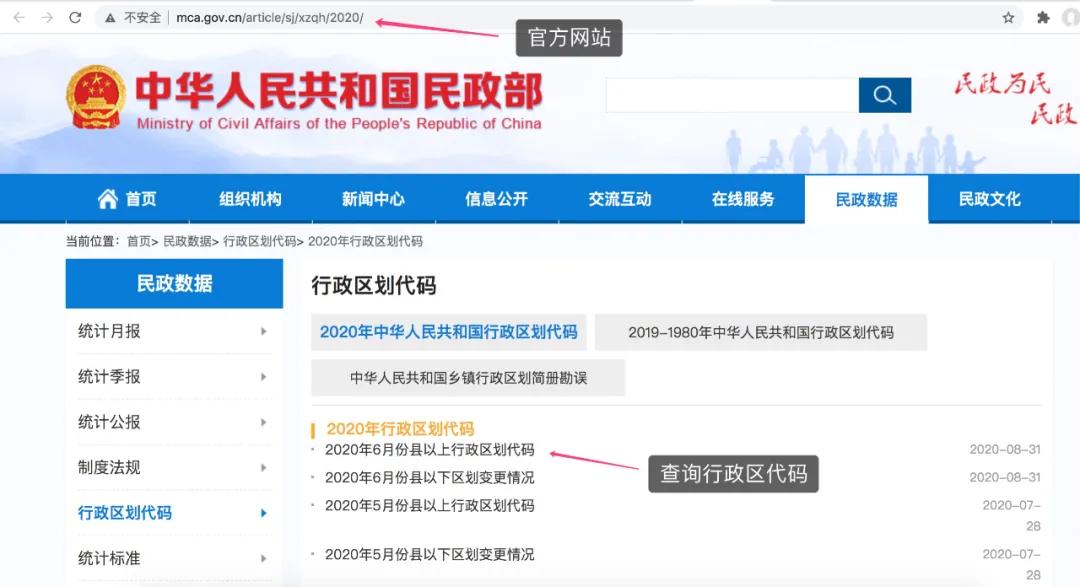
点击进去,展示结果如下!
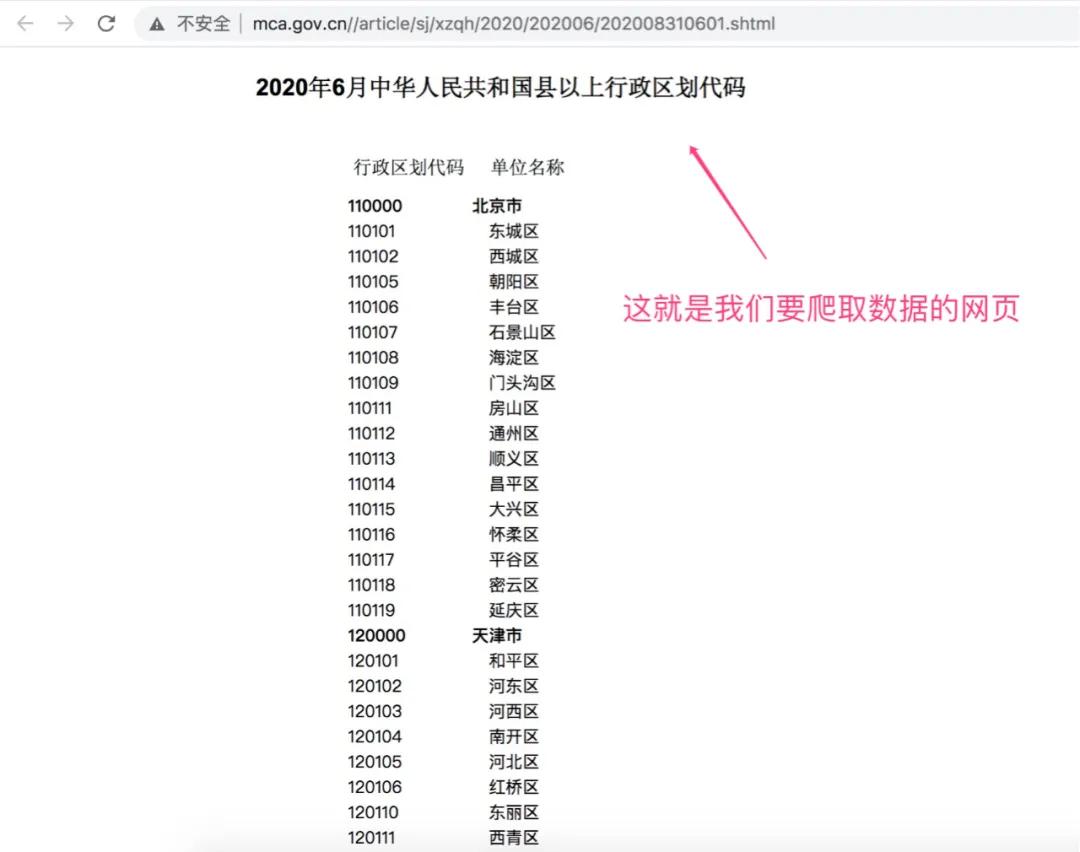
可以很清楚的看到,这就是我们要获取省市区代码的网页信息。
可能有的同学会问,这么直接干合不合法?
国家既然已经公示了,我们直接拿来用就可以,完全合法!而且国家省市区代码是一个公共字典,在很多业务场景下必不可少!
当我们找到了目标网页之后,我们首先要做的就是对网页进行分析,打开浏览器调试器,可以很清晰的看到它是一个table表格组成的数据。
熟悉 html 标签的同学,想必已经知道了它的组成原理。
其实table是一个非常简单的 html 标签,主要有tr和td组成,其中tr代表行,td代表列,例如用table标签画一个学生表格,代码如下:
- <table>
- <!-- 定义表格头部 -->
- <tr>
- <td>编号</td>
- <td>姓名</td>
- </tr>
- <!-- 定义表格内容 -->
- <tr>
- <td>100</td>
- <td>张三</td>
- </tr>
- <tr>
- <td>101</td>
- <td>李四</td>
- </tr>
- </table>
展示结果如下:

了解了table标签之后,我们再对网页进行详细分析。
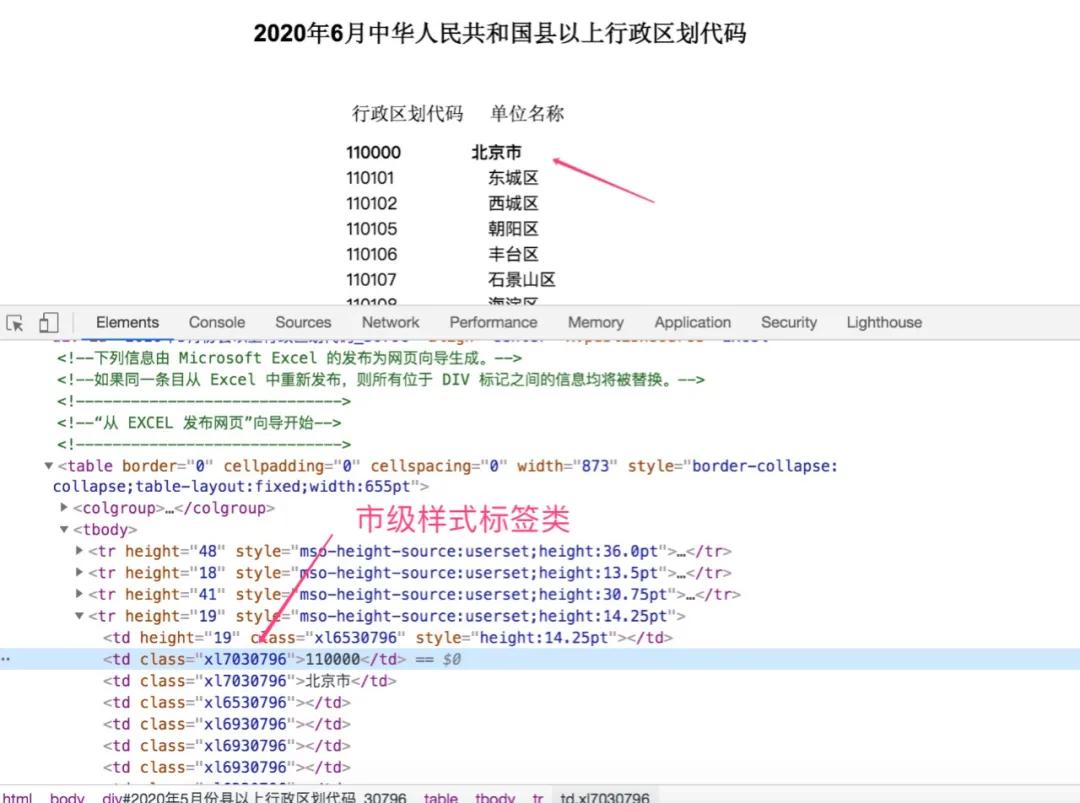
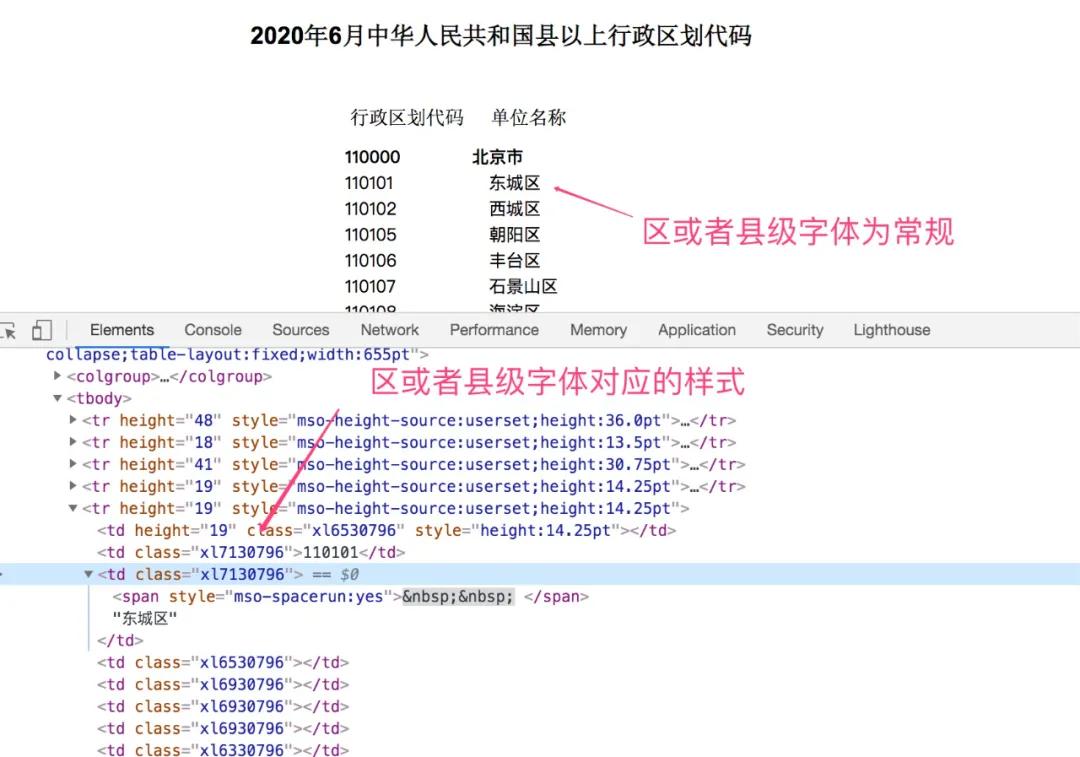
首先对整个内容进行观察,很容易的看到,市级以上(包括市级),都是黑体字加粗的,区或者县级地区,都是常规!

出现这个现象,其实是由样式标签CSS来控制的,点击北京市,找到对应的代码位置,从图中我们可以很清晰的看到,市级对应的样式class为xl7030796,区或者县级地区对应的样式class为xl7130796
除此之外,我们继续来看看省和市级的区别!
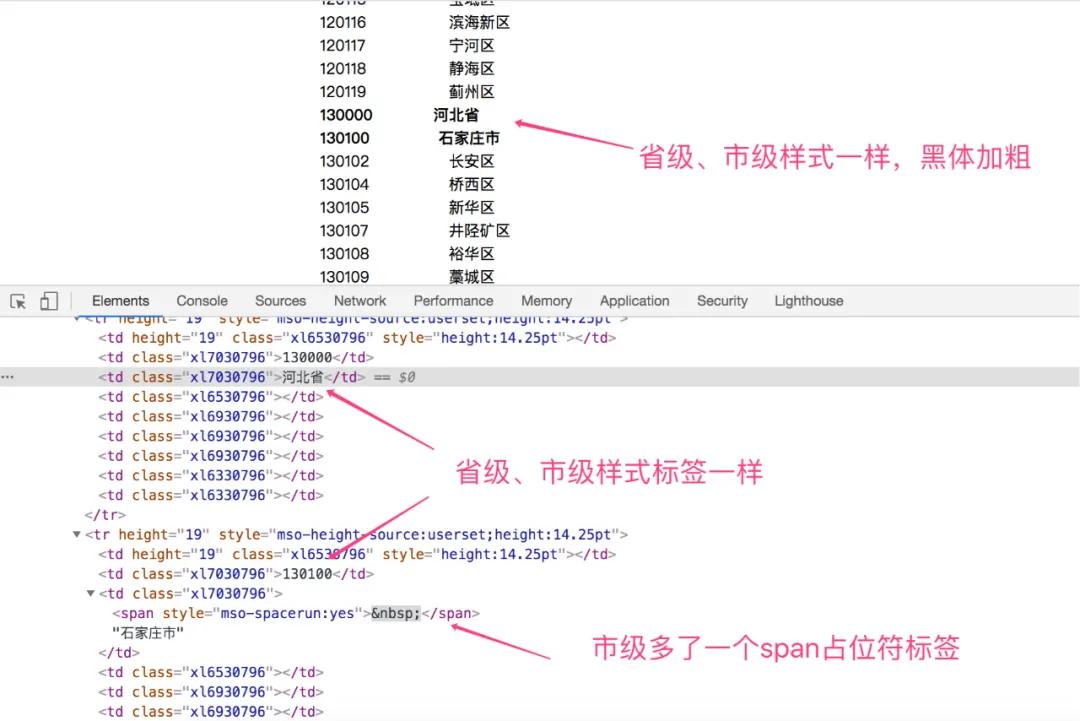
可以很清晰的看到,市级相比省级信息,多了一个span占位符标签。
于是,我们可以得出如下结论:
省级信息,样式标签为xl7030796
市级信息,样式标签为xl7030796,同时包含span占位符标签
区或者县级信息,样式标签为xl7130796
等会会通过这些规律信息来从网页信息中抓取省、市、区信息。
三、编写爬虫程序
3.1、创建项目
新建一个基于 maven 工程 java 项目,在pom.xml工程中引入如下 jar 包!
- <!--解析HTML-->
- <dependency>
- <groupId>org.jsoup</groupId>
- <artifactId>jsoup</artifactId>
- <version>1.11.2</version>
- </dependency>
3.2、编写爬取程序
先创建一个实体数据类,用于存放抓取的数据
- public class ChinaRegionsInfo {
- /**
- * 行政区域编码
- */
- private String code;
- /**
- * 行政区域名称
- */
- private String name;
- /**
- * 行政区域类型,1:省份,2:城市,3:区或者县城
- */
- private Integer type;
- /**
- * 上一级行政区域编码
- */
- private String parentCode;
- //省略get、set
- }
然后,我们来编写爬取代码,将抓取的数据封装到实体类中
- //需要抓取的网页地址
- private static final String URL = "http://www.mca.gov.cn//article/sj/xzqh/2020/202006/202008310601.shtml";
- public static void main(String[] args) throws IOException {
- List<ChinaRegionsInfo> regionsInfoList = new ArrayList<>();
- //抓取网页信息
- Document document = Jsoup.connect(URL).get();
- //获取真实的数据体
- Element element = document.getElementsByTag("tbody").get(0);
- String provinceCode = "";//省级编码
- String cityCode = "";//市级编码
- if(Objects.nonNull(element)){
- Elements trs = element.getElementsByTag("tr");
- for (int i = 3; i < trs.size(); i++) {
- Elements tds = trs.get(i).getElementsByTag("td");
- if(tds.size() < 3){
- continue;
- }
- Element td1 = tds.get(1);//行政区域编码
- Element td2 = tds.get(2);//行政区域名称
- if(StringUtils.isNotEmpty(td1.text())){
- if(td1.classNames().contains("xl7030796")){
- if(td2.toString().contains("span")){
- //市级
- ChinaRegionsInfo chinaRegions = new ChinaRegionsInfo();
- chinaRegions.setCode(td1.text());
- chinaRegions.setName(td2.text());
- chinaRegions.setType(2);
- chinaRegions.setParentCode(provinceCode);
- regionsInfoList.add(chinaRegions);
- cityCode = td1.text();
- } else {
- //省级
- ChinaRegionsInfo chinaRegions = new ChinaRegionsInfo();
- chinaRegions.setCode(td1.text());
- chinaRegions.setName(td2.text());
- chinaRegions.setType(1);
- chinaRegions.setParentCode("");
- regionsInfoList.add(chinaRegions);
- provinceCode = td1.text();
- }
- } else {
- //区或者县级
- ChinaRegionsInfo chinaRegions = new ChinaRegionsInfo();
- chinaRegions.setCode(td1.text());
- chinaRegions.setName(td2.text());
- chinaRegions.setType(3);
- chinaRegions.setParentCode(StringUtils.isNotEmpty(cityCode) ? cityCode : provinceCode);
- regionsInfoList.add(chinaRegions);
- }
- }
- }
- }
- //打印结果
- System.out.println(JSONArray.toJSONString(regionsInfoList));
- }
运行程序,输出结果如下:

json解析结果如下:
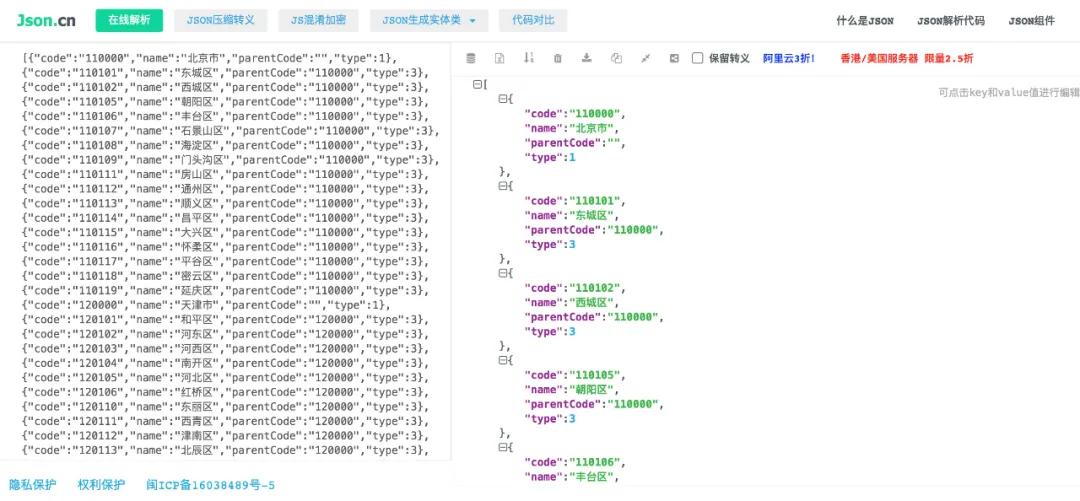
至此,网页有效数据已经全部抓取完毕!
四、写入数据库
在实际的业务场景中,我们需要做的不仅仅只是抓取出有价值的数据,最重要的是将这些数据记录数据库,以备后续的业务可以用的上!
例如,当我们在开发一个给员工发放薪资系统的时候,其中的社保、公积金,可能每个城市都不一样,这个时候就会到国家省市区编码。
因此,我们可以将抓取的国家省市区编码写入数据库!
在上面,我们已经将具体的省市区数据结构封装成数组对象,写入过程也很简单。
首先,创建一张国家行政地域信息表china_regions
- CREATE TABLE `china_regions` (
- `id` bigint(20) unsigned NOT NULL COMMENT '主键ID',
- `code` varchar(32) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT '行政地域编码',
- `name` varchar(50) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT '行政地域名称',
- `type` tinyint(4) NOT NULL DEFAULT '1' COMMENT '行政地域类型,1:省份,2:城市,3:区域',
- `parent_code` varchar(32) COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT '上一级行政编码',
- `is_delete` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否删除 1:已删除;0:未删除',
- `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
- `update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
- PRIMARY KEY (`id`),
- KEY `idx_code` (`code`) USING BTREE,
- KEY `idx_name` (`name`) USING BTREE,
- KEY `idx_type` (`type`) USING BTREE,
- KEY `idx_parent_code` (`parent_code`) USING BTREE
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='国家行政地域信息表';
搭建一个springboot工程,通过mybatis-plus组件,一键生成代码
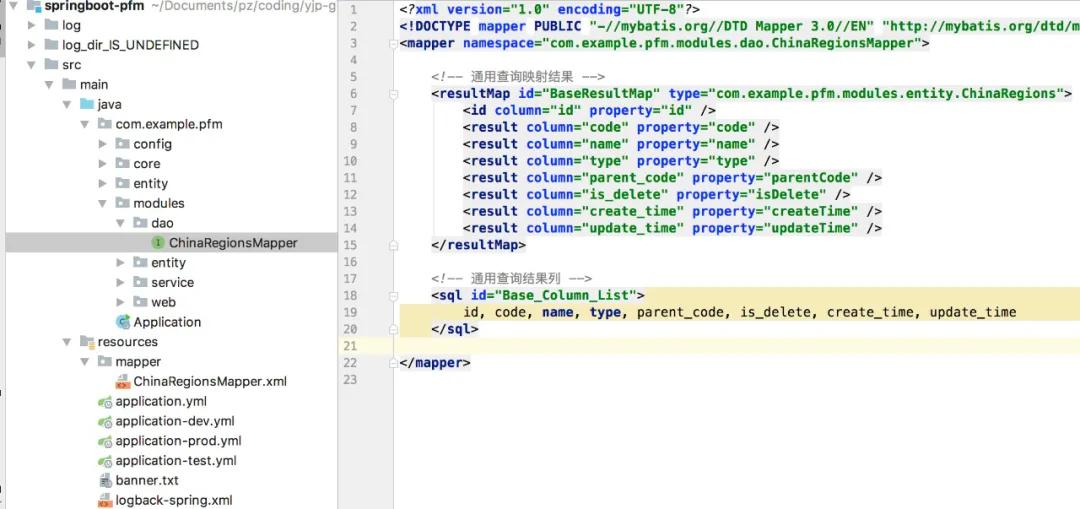
最后,配置好数据源,重新封装数组对象,调用批量插入方法,即可插入操作
- chinaRegionsService.saveBatch(regionsInfoList);
插入执行完之后,数据库结果如下
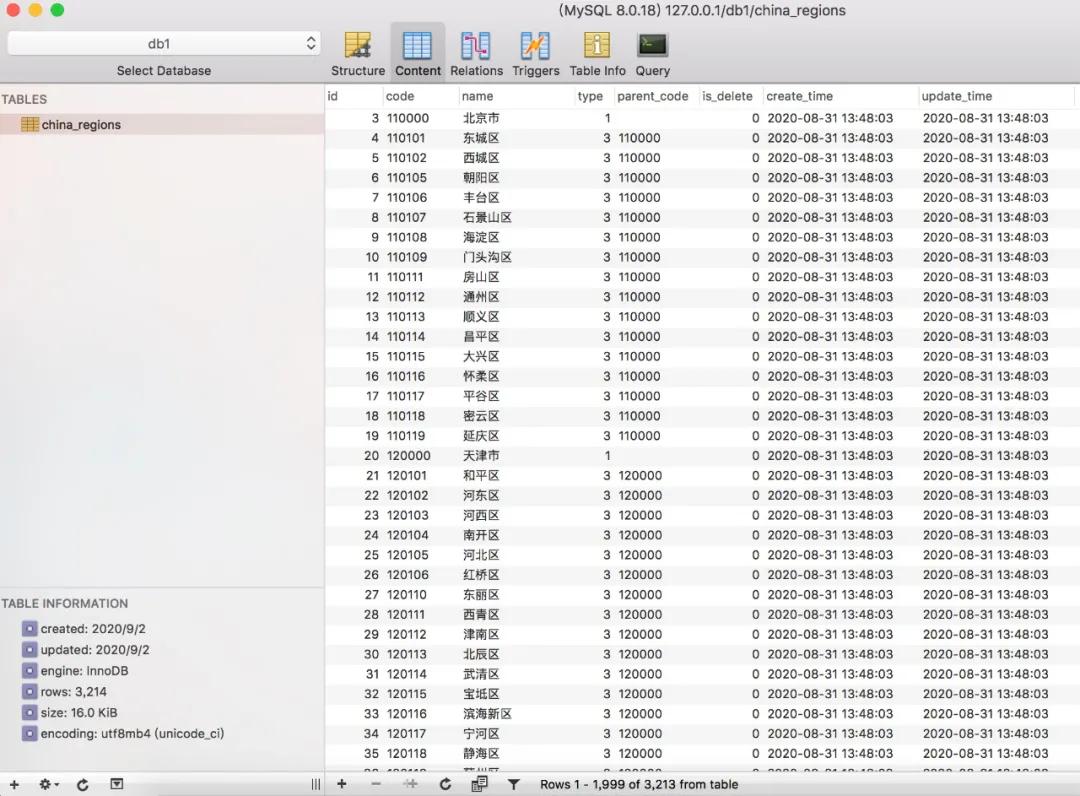
至此,大部分工作基本已经完成!
但是,细心的你,可能会发现还有数据问题,因为我们国家在省级区域上,还有一个直辖市的概念,以北京市为例,在数据库中type类型为1,表示省级类型,但是它的子级是一个区,中间还掉了一层市级类型。
因此,我们还需要对这些直辖市类型的数据进行修复,查询出所有的直辖市类型的城市。
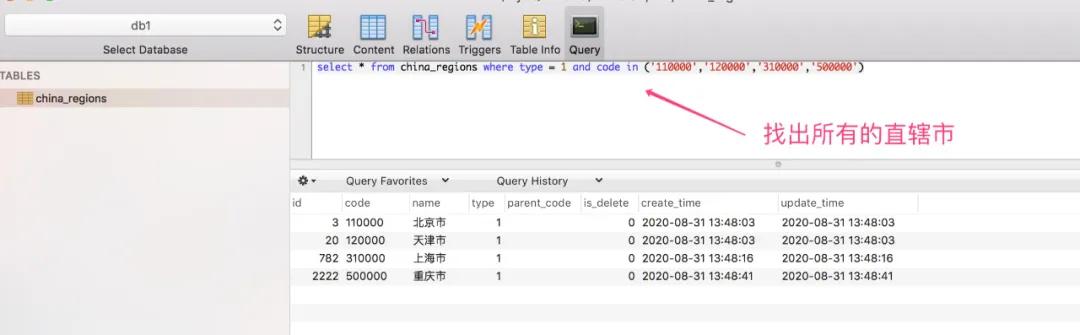
对这些编号的城市,单独处理,中间加一层市级类型!
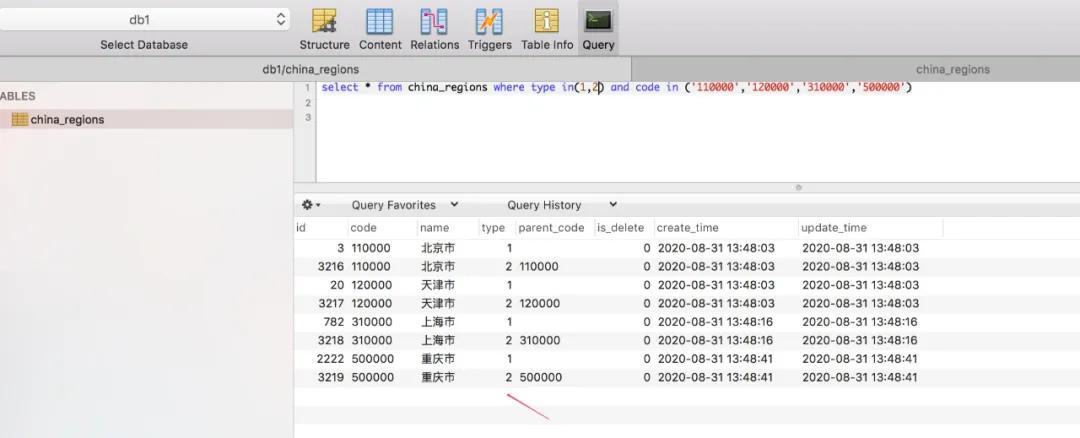
至此,国家省市区编码数据字典,全部处理完毕!
五、总结
本篇主要以爬取国家省市区编号为例,以 java 技术为背景进行讲解,在整个爬取过程中,最重要的一部分就是网页分析,找出规律,然后通过jsoup工具包解析网页,获取其中的有效数据。
同时,技术是一把双面刀,希望同学们能正当使用!
七、参考
1、2020年行政区划代码
2、jsoup -中文文档



















