













具体来说,在本文中,我将概述统计、时间序列分析、自然语言处理、机器学习和运筹学中的方法。
01 应用统计与数学
与前面许多已经讨论过的概念一样,人们如何定义统计以及统计与一般数学(mathematics)有何不同,存在着很大的差异。
有些人认为统计是数学的一个分支(Merriam-Webster,2017b),而另一些人(如John Tukey(Brillinger,2002))则认为统计是一门独立的科学。大多数人认为,就像物理学也使用数学方法但不是数学一样,统计学使用数学但它并不是数学(Milley,2012)。
统计涉及数据的收集、组织、分析、解释和展示。如果使用这个广义的定义,它听起来和分析的概念非常像。然而,分析和数据科学都使用统计学的数量分析基础,但它们的关注范围比传统统计更广泛,而关于统计与其他学科之间的概念关系有几十个观点,我列举了我所看到的这些概念之间的关系,如图1-3所示。
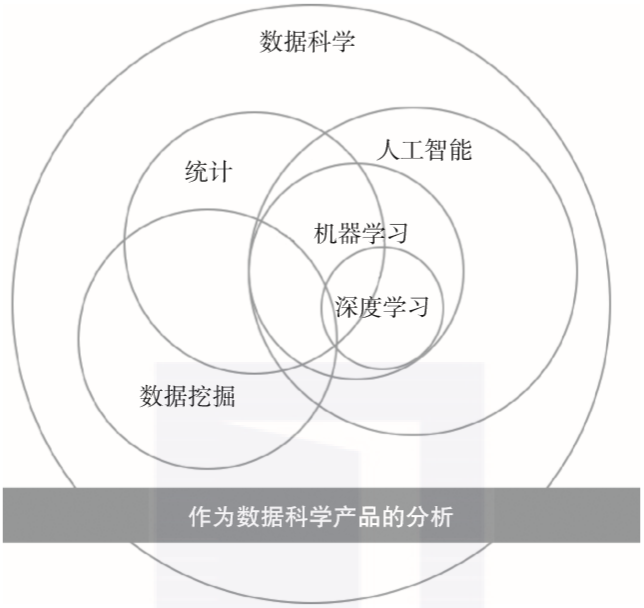
▲图1-3 统计与其他定量学科之间的关系
数学具有一定的绝对和可确定的性质,而数学的教学方式(至少在美国学校是如此)灌输了一种以确定性的方式来看待数量世界的思想。也就是说,我们被教导相信,所有的事实和事件都可以被解释清楚。
但是,统计则把量化数据看成概率的或随机的。也就是说,根据事实可能会推导出普遍正确的结论(除了简单的随机性),但必须承认,存在一些无法准确预测的随机概率分布或模式。
- 拓展学习:想要学习更多的统计学历史及它如何改变科学,请阅读David Salsburg的书The Lady Tasting Tea。
如图1-4所示,数学思维是演绎性的(即,它通过应用一般定律或原则来推断某一特定实例),而统计推理是归纳性的(即,它从具体实例中提炼出一般规律)。
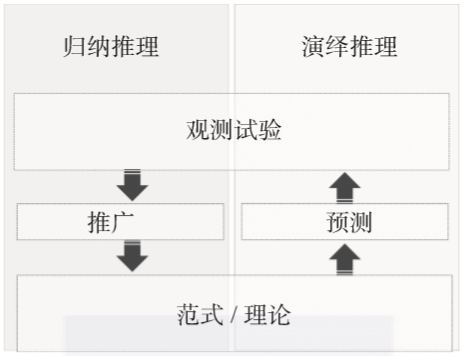
▲图1-4 归纳推理与演绎推理的比较
这种差异在分析的环境下是很重要的,因为我们将归纳推理和演绎推理应用于分析解决不同的问题。因此,将数学和统计都应用到分析领域是适当的和必要的。如果开展分析是一种全面的策略,那么统计和数学就是在众所周知的分析工具箱中帮助我们实现该策略的两个工具。
线性规划(linear programming)可用于支持我们分析解决一类特定的优化问题。例如,迪士尼公司在其数据科学类工作中使用线性、非线性、混合整数和动态规划,来解决诸如优化餐厅座位安排、减少公园之间乘车的等待时间、安排工作人员(如演员)时间表等方面的问题。
请注意,为了讨论的方便,我在这里不严格区分运筹学(operation research)、数学最优化(mathematical optimization)、决策科学(decision science)或精算科学(actuarial science)之间的区别,因为在我看来,它们都是我们分析工具箱中众多分析工具的组成部分而已,可以根据思考和解决问题的需要而灵活使用。
- 线性规划:线性规划是解决问题的一个数学方法,其输出是一个线性模型函数。例如,我们可能想通过调节几个关键因素,比如外科手术的复杂度、需要医务人员的数量、可能出现的并发症等,来优化急救部门的效能。
02 预测和时间序列
在讨论支持分析的方法时,预测和时间序列往往被一起提及,并不是因为它们是同一种方法,而是因为它们都针对同一类问题,即基于历史信息对时间序列数据进行特征提炼和预测。
预测和时间序列分析是指对时间序列数据进行分析、从数据中提炼有意义特征的方法。很多时候,预测被描述为通过历史数据对趋势进行判断,并通过可视化手段进行直观展现的方法,有些还提供了关于未来的预测。
而时间序列分析不同于预测,虽然你需要时间序列数据来进行预测,但并非所有的时间序列分析都是用来进行预测的。例如,时间序列分析可用于在多个时间序列中发现模式或相似的特征,或执行统计过程控制。类似地,季节性的分析也可以用来识别模式。
时间序列分析采用了多种方法,既有定量的,也有定性的。时间序列分析的目的是在历史数据(或时间序列数据)中找出一种模式,然后推测未来趋势。通常有四大类时间序列分析方法,如图1-5所示。
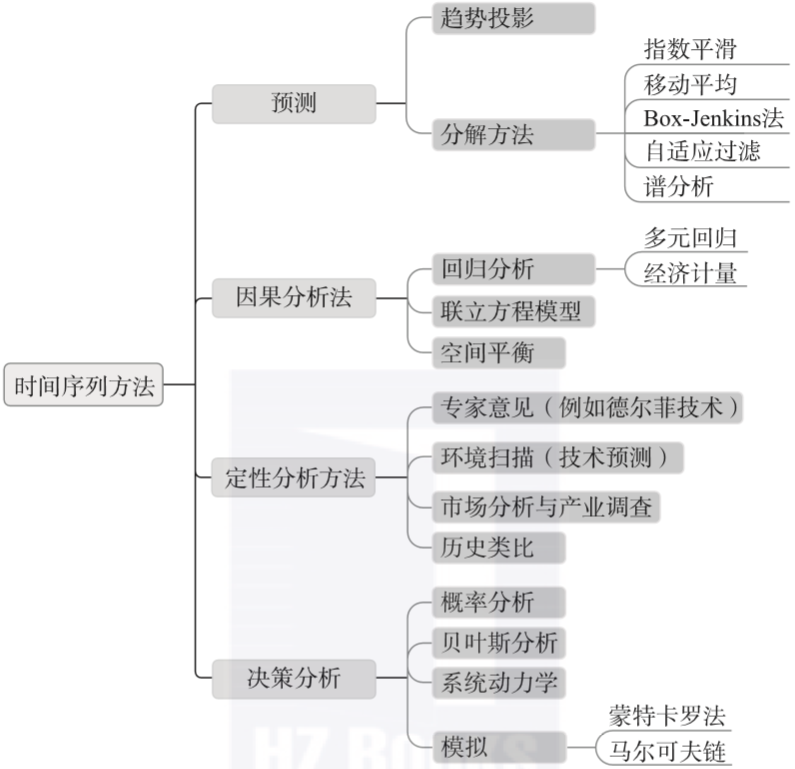
▲图1-5 预测和时间序列分析的方法
一般而言,定量方法是最常见的预测方法。但是,当无法获得定量的历史数据时,或者广泛存在不确定性时,使用定性分析和决策分析方法也很普遍。
03 自然语言处理
自然语言处理(Natural Language Process,NLP)是指通过计算机来理解和生成“自然语言”的方法。
当前,NLP是一个专注于人类语言和计算机之间相互交互的研究领域,处于计算机科学、人工智能和计算语言学的交叉领域。文本挖掘和文本分析技术通常可以互换使用,既是NLP的前置活动也可以是NLP本身的应用。
NLP的目标是理解计算机文本中的自然语言,NLP用于文本的分类、提取和总结,我们在理解和技术方面的进步正迅速将NLP推向分析和其他许多领域应用的前沿。例如,在分析过程中,我们获取过去的描述信息(如文本、文档、推文、演讲),并对它们进行语义分类或情绪理解。
情绪分析对于理解人们如何看待产品或服务特别有用。在医疗保健领域,情绪分析被用来衡量患者的情绪,以及识别那些有心力衰竭风险的患者。然后,这些文本摘要将作为分析过程的输入,用于预测建模、决策分析、搜索或回答问题的机器人。
图1-6概述了这样一个自然语言处理的普遍过程。

▲图1-6 自然语言处理过程示意图
NLP的一个非常实际的应用是在市场营销领域,文本用于理解客户对某商品(通常指品牌或产品)的整体“情感”。这里的情感指的是如何理解客户的情绪并对情绪进行提炼与归类。除了情感分析,NLP还可以有多种应用,比如:
- 语法检查
- 实体提取
- 翻译
- 搜索
- 标准化
- 回答问题
- 拓展学习:欲了解更多自然语言处理中使用的技术,请阅读Matthew Mayo的文章:https://www.kdnuggets.com/2017/02/natural-language-processing-key-terms-explained.html
自然语言生成(Natural Language Generation,NLG)是人工智能和NLP研究的一个子集,它指自动从结构化数据中生成有意义的、可阅读的文本。与NLP不同,NLG走的是另一条研究道路。
也就是说,NLG以数据或其他形式的信息作为输入,以文本作为输出。
NLG已经被广泛应用于各种聊天机器人,从客户服务(见Pathania和Guzma,Chatbots in Customer Service)到疾病症状诊断。聊天机器人只是NLG的一种应用,其他应用还包括自动化完成下列事项:
- 把商业智能报表归纳成完整的分析报告(Qlik、Tableau、TIBCO、Microstrategy、Sisense、Information Builders都提供这类方法)
- 自动创建财务报表并完成分析(Nanalyze软件提供此类功能)
- 制作每日体育资讯简报(StatsMonkey提供此类功能)
- 自动编制客户服务代表的绩效评估(Narrative Science公司的Quill软件提供此类功能)
- 在客户关系管理系统中自动创建CRM话术脚本,建议销售机会(Yseop的Savvy提供此类功能)
- 为小企业提供智能的“财务分析师”整体解决方案(Arria公司的Recount软件提供此类功能)
历史上,自然语言处理领域涉及规则的直接编码,以便处理语言本体,定义单词的结构,理解内容和上下文,以及它们在日常语言中的使用方式。统计计算、计算语言学和机器学习的现代进步正以前所未有的速度改变着NLP的世界。
04 文本挖掘与文本分析
一般来说,文本分析中最令人困惑的一个方面可能是NLP和文本挖掘之间的区别。就像在数据挖掘中所做的一样,我们试图从数据中提取有用的信息。在文本分析情况下,数据恰好是文本,从中提取的信息包括在文本数据中发现的模式和趋势。
文本挖掘处理文本数据本身,我们试图回答诸如词汇的频率、句子长度、某些文本字符串的存在或不存在等问题。我们可以解决概述的问题(例如,使用NLP中的技术进行分类)。本质上,文本挖掘通常是NLP的前奏。
文本分析涵盖的范围广泛,通常包括应用统计分析、机器学习和其他一些高级分析技术,但通常被认为等同于文本挖掘。我觉得这是个灰色地带。
注意,在商业智能领域人们经常使用文本分析这一术语,以表示更多的简单行动可以通过典型的报表方式(例如词云、词频分析等),以一种自动和可视化的方式完成。
文本挖掘一般是数据科学家喜欢使用的提法,他们虽然拥有很多更先进的方法,但那些在文本挖掘中需要做的计数、统计之类的基础事务也是他们复杂工作的一部分。我认为这符合我的观点,即分析是商业智能(BI)的一种自然进化。
需要特别注意的是,不同的社区、不同的场景,会使用不同的术语,这在实际工作中可能会引起一些理解的混淆。例如,参见:
www.linguamatics.com/blog/are-terms-text-mining-and-text-analytics-largely-inter changeable
05 机器学习
美国最大的私营软件公司和分析巨头SAS公司将机器学习定义为:
……一种自动建立分析模型的数据分析方法。机器学习使用数据迭代学习的算法,使计算机能够在无须显式编程的情况下具有找到隐藏见解的洞察力。
机器学习的核心是使用算法来建立量化分析模型,帮助计算机模型从数据中“学习”。它同以人为中心的处理过程不同,它是由计算机学习和发现隐藏在数据中的模式,而不是由人去直接建立模型。
一般而言,机器学习中模型建立和模型管理的概念是指能够持续并且重复开展后续的决策流程,而不是高度人工参与的常常基于统计手段的分析。
随着近年来计算能力的进步,机器学习可以用来自动地实现针对大数据的复杂数学计算,而这在以前是不可能实现的。
人类通常每周可以建立一到两个好的模型,而机器学习每周可以创建数千个模型。
——Thomas H.Davenpot,分析思想领袖(Davenport,2013年)
图1-7概述了机器学习中的常见方法。
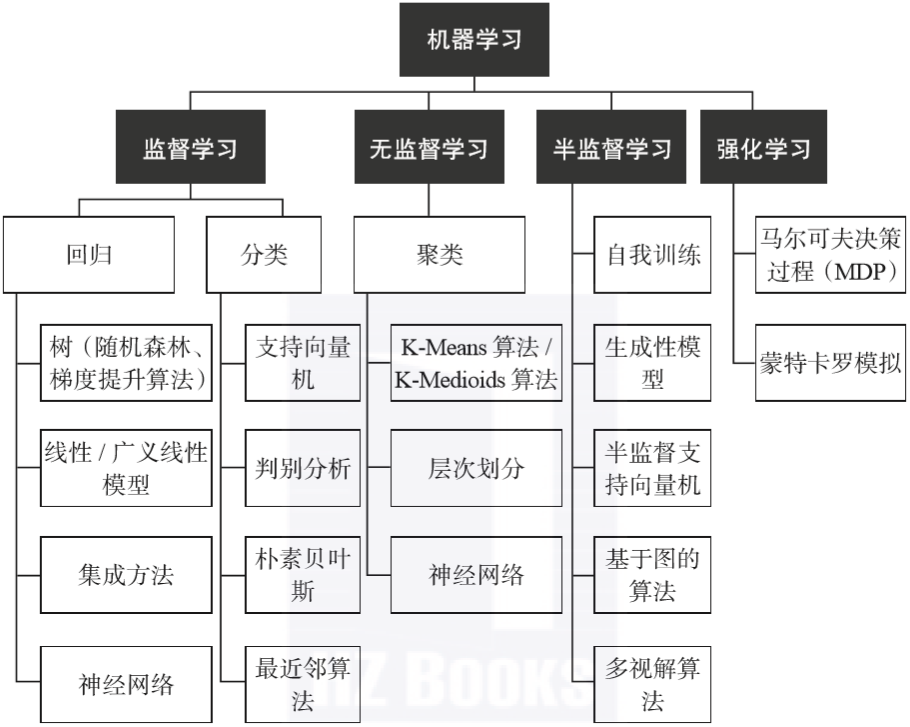
▲图1-7 机器学习常用技术归纳
- 拓展学习:要学习更多相关知识及机器学习中的其他术语,请访问谷歌开发者机器学习词汇表,网址为:developers.google.com/machine-learning/glossary/
人们通常根据计算机的“学习模式”对机器学习算法进行分类(记住,机器学习就是让计算机通过分析数据中的模式来提炼规律),也就是说,针对同样的数据,可以有不同的机器学习算法来对真实世界(问题)建模。
一般而言,有四种机器学习模式或者学习模型算法,它们的区别在于输入变量扮演的角色不同,以及如何为训练模型准备数据。
表1-1概述了不同机器学习算法的差异。
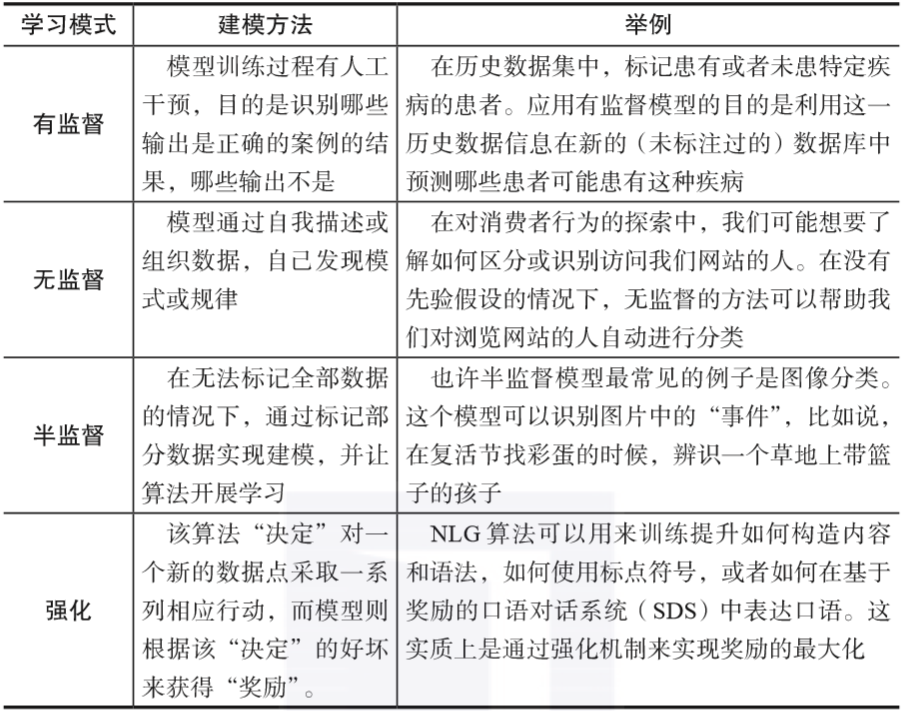
表1-1 机器学习模式
06 数据挖掘
- 数据挖掘:数据挖掘是在(通常是大型)数据集中发现和解释规律模式,以解决业务问题的过程。
在20世纪90年代末和21世纪初,数据挖掘作为一种分析大型数据库以生成新的或与众不同的信息的方法而被广泛应用。数据挖掘界的梦想是“找到干草堆中的一根针”。数据挖掘与统计学不同的是,在数据探索之前,不一定有一个先验的理论驱动假说。
- 先验:“先验”被定义为“从早期开始”,或者简单地解释为“事先”。先验假设是在进行实验或收集数据之前陈述的假设。
数据挖掘采用传统的统计方法以及人工智能和机器学习技术,目的是在我们拥有的数据中识别出以前未知的模式并进行预测。
就像分析中采用的其他技术一样,数据挖掘遵循这样一个生命周期:通常从问题描述开始,然后对数据进行理解,再进行模型构建,并根据结果采取相应行动。
一般情况下,数据挖掘人员识别出感兴趣的输出变量,然后使用各种技术对数据进行预处理(如聚类、主成分分析和关联规则学习),然后将这些输出变量作为输入应用到数据挖掘算法中,如回归算法、神经网络、决策树或支持向量机。
数据挖掘过程中的一个关键部分是模型评估和确保我们不会过度拟合模型。





















