













本文转载自公众号“读芯术”(ID:AI_Discovery)。
就业市场上,机器学习工程师总是受到质疑,人们不相信他们数学功底深厚。事实上,所有机器学习算法的本质都是数学问题,无论是支持向量机、主成分分析还是神经网络最终都归结为对偶优化、谱分解筛选和连续非线性函数组合等数学问题。只有彻底理解数学,才能正真掌握这些机器学习算法。
Python中的各种数据库能帮助人们利用高级算法来完成一些简单步骤。例如包含了K近邻算法、K均值、决策树等算法的机器学习算法库Scikit-learn,或者Keras,都可以帮助人们构建神经网络架构,而不必了解卷积神经网络CNNs或是循环神经网络RNNs背后的细节。
然而,想要成为一名优秀的机器学习工程师需要的远不止这些。在面试时,面试官通常会问及如何从零开始实现K近邻算法、决策树,又或者如何导出线性回归、softmax反向传播方程的矩阵闭式解等问题。
本文将回顾一些微积分的基本概念助你准备面试,如一元和多元函数的导数、梯度、雅可比矩阵和黑塞矩阵。同时,本文还能为你深入研究机器学习、尤其是神经网络背后的数学运算打下良好的基础。这些概念将通过5个导数公式来展示,绝对是面试必备干货。
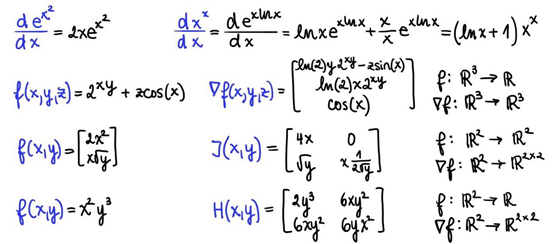
导数1:复合指数函数
指数函数非常基础常见,而且非常有用。它是一个标准正函数。在实数ℝ中eˣ > 0,同时指数函数还有一个重要的性质,即e⁰ = 1。
另外,指数函数与对数函数互为反函数。指数函数也是最容易求导的函数之一,因为指数函数的导数就是其本身,即(eˣ)’ = eˣ。当指数与另一个函数组合形成一个复合函数时,复合函数的导数就变得更为复杂了。在这种情况下,应遵循链式法则来求导,f(g(x))的导数等于f’(g(x))⋅g’(x),即:
运用链式法则可以计算出f(x)= eˣ²的导数。先求g(x)=x²的导数:g(x)’=2x。而指数函数的导数为其本身:(eˣ)’=eˣ。将这两个导数相乘,就可以得到复合函数f(x)= eˣ²的导数:
这是个非常简单的例子,乍一看可能无关紧要,但它经常在面试开始前被面试官用来试探面试者的能力。如果你已经很久没有温习过导数了,那么很难确保自己能够迅速应对这些简单问题。虽然它不一定会让你得到这份工作,但如果你连这么一个基本问题都回答不上,那你肯定会失去这份工作。
导数2:底数为变量的复变指数
复变指数函数是一个经典面试问题,尤其是在计量金融领域,它比科技公司招聘机器学习职位更为看重数学技能。复变指数函数迫使面试者走出舒适区。但实际上,这个问题最难的部分是如何找准正确的方向。
当函数逼近一个指数函数时,首先最重要的是要意识到指数函数与对数函数互为反函数,其次,每个指数函数都可以转化为自然指数函数的形式:
在对复变指数函数f(x) = xˣ求导前,要先用一个简单的指数函数f(x) = 2ˣ来证明复变函数的一种性质。先用上述方程将2ˣ 转化为exp(xln(2)),再用链式法则求导。
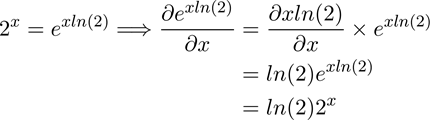
现在回到原来的函数f(x)=xˣ,只要把它转化为f(x)=exp(x ln x),求导就变得相对简单,可能唯一困难的部分是链式法则求导这一步。
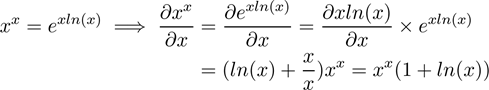
注意这里是用乘积法则(uv)’=u’v+uv’来求指数xln(x)的导数。
通常情况下,面试官提问这个函数时不会告诉你函数定义域。如果面试官没有给定函数定义域,他可能是想测试一下你的数学敏锐度。这便是这个问题具有欺骗性的地方。没有限定定义域,xˣ既可以为正也可以为负。当x为负时,如(-0.9)^(-0.9),结果为复数-1.05–0.34i。
一种解决方法是将该函数的定义域限定为ℤ⁻ ∪ ℝ⁺ \0,但对于负数来说,函数依然不可微。因此,为了正确推导出复变指数函数xˣ的导数,只需要把该函数的定义域严格限定为正数即可。排除0是因为此时导数也为0,左右导数需相等,但在这种情况下,此条件是不成立的。因为左极限是没有定义的,函数在0处不可微,因此函数的定义域只能限定为正数。
在继续以下内容之前,先考考你,这里有一个比复变指数函数f(x) = xˣ更高级的函数f(x) = xˣ²。如果你理解了第一个例子背后的逻辑和步骤,再加一个指数应该毫无难度,可以推导出以下结果:
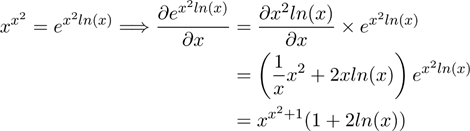
导数3:多元输入函数的梯度
到目前为止,前面讨论的函数导数都是从ℝ映射到ℝ的函数,即函数的定义域和值域都是实数。但机器学习本质上是矢量的,函数也是多元的。
下面这个例子最能阐释这种多元性:当神经网络的输入层大小为m和输出层大小为k时,即f(x) = g(Wᵀx + b),此函数是线性映射Wᵀx(权阵W和输入向量x)和非线性映射g(激活函数)按元素组成的。一般情况下,该函数也可视作是从ℝᵐ到ℝᵏ的映射。
我们把k=1时的导数称为梯度。现在来计算以下从ℝ³映射到ℝ的三元函数:
可以把f看作是一个函数,它从大小为3的向量映射到大小为1的向量。
图源:unsplash
多元输入函数的导数被称为梯度,用倒三角符号∇(英文为nabla)表示。从ℝⁿ映射到ℝ的函数g的梯度是n个偏导数的集合,每个偏导数都是一个n元函数。因此,如果g是一个从ℝⁿ到ℝ的映射,其梯度∇g是一个从ℝⁿ到ℝⁿ的映射。
要推导出函数f(x,y,z) = 2ˣʸ + zcos(x)的梯度,需要构造一个矢量的偏导数:∂f/∂x,∂f/∂y和∂f/∂z,结果如下:
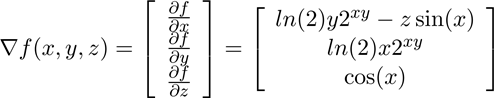
需要注意,此处也需要利用公式进行等值转化,即2ˣʸ=exp(xy ln(2))。
总之,对于一个从ℝ³映射到 ℝ的三元函数f,其导数是一个从ℝ³映射到ℝ³的梯度∇ f。从ℝᵐ映射到ℝᵏ(k > 1)的一般式中,一个从ℝᵐ映射到ℝᵏ的多元函数的导数是一个雅可比矩阵,而非一个梯度向量。
导数4:多元输入输出函数的雅可比矩阵
上一节中已经提到从ℝᵐ映射到ℝ的函数的导数,是一个从ℝᵐ映射到ℝᵐ的梯度。但如果输出域也是多元的,即从ℝᵐ映射到ℝᵏ(k > 1),那又当如何?
这种情况下,导数为雅可比矩阵。可以把梯度简单视为一个m x 1的特殊雅可比矩阵,此时m与变量个数相等。雅可比矩阵J(g)是一个从ℝᵐ到ℝᵏ*ᵐ的映射,其中函数g从ℝᵐ映射到ℝᵏ。这也就是说输出域的维数是k x m,即为一个k x m矩阵。换言之,在雅可比矩阵J(g)中,第i行表示函数gᵢ的梯度∇ gᵢ。
假设上述函数f(x, y) = [2x², x √y]从ℝ²映射到ℝ²,通过推导该函数的导数可以发现函数的输入和输出域都是多元的。在这种情况下,由于平方根函数在负数上没有定义,需要把y的定义域限定为ℝ⁺。输出雅可比矩阵的第一行就是函数1的导数,即∇ 2x²;第二行为函数2的导数,即∇ x √y。
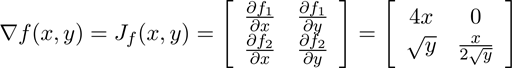
雅可比矩阵在深度学习中的可解释性领域中有一个有趣用例,目的是为了理解神经网络的行为,并分析神经网络的输出层对输入的灵敏度。
雅可比矩阵有助于研究输入空间的变化对输出的影响,还可以用于理解神经网络中间层的概念。总之需要记住梯度是标量对向量的导数,雅可比矩阵是一个向量对另一个向量的导数。
导数5:多元输入函数的黑塞矩阵
目前仅讨论了一阶导数求导,但在神经网络中,会经常讨论多元函数的高阶导数。其中一种特殊情况就是二阶导数,也被称为黑塞矩阵,用H(f)或∇ ²(微分算符的平方)表示。从ℝⁿ映射到ℝ的函数g的黑塞矩阵是从ℝⁿ到ℝⁿ*ⁿ的映射H(g)。
现在分析一下我们是如何将输出域从ℝ转化为ℝⁿ*ⁿ。一阶导数,即梯度∇g,是一个从ℝⁿ到ℝⁿ的映射,其导数是一个雅可比矩阵。因此,每一个子函数的导数∇gᵢ都由n个从ℝⁿ映射到ℝⁿ的函数组成。可以这样想,就好比是对展开成一个向量的梯度向量的每个元素都求导,从而变成向量中的向量,即为一个矩阵。
要计算黑塞矩阵,需要计算交叉导数,即先对x求导,再对y求导,反过来也可以。求交叉导数的顺序会不会影响结果,换句话说,黑塞矩阵是否对称。在这种情况下,函数f为二次连续可微函数(用符号²表示),施瓦兹定理表明交叉导数是相等的,因此黑塞矩阵是对称的。一些不连续但可微的函数,不满足交叉导数等式。
构造函数的黑塞矩阵就相当于求一个标量函数的二阶偏导数。以f(x,y) = x²y³为例,计算结果如下:
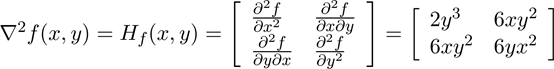
可以看到交叉导数6xy²实际上是相等的。先对x求导得到关于x的偏导数2xy³,再对y求导得到关于y的偏导数6xy²。对于x或y的每个一元子函数,对角元素都为fᵢ。
此类函数的拓展部分将讨论从ℝᵐ映射到ℝᵏ的多元函数的二阶导数的情况,可以将其视为一个二阶雅可比矩阵。这是一个从ℝᵐ到ℝᵏ*ᵐ*ᵐ的映射,即一个三维张量。与黑塞矩阵相似,为了求出雅可比矩阵的梯度(求二阶微分),要对k x m矩阵的每一个元素微分,得到一个向量矩阵,即为一个张量。虽然不太可能要求面试者进行手动计算,但了解多元函数的高阶导数相当重要。
本文回顾了机器学习背后重要的微积分基础知识,列举了几个一元和多元函数的例子,讨论了梯度、雅可比矩阵和黑塞矩阵,全面梳理了机器学习面试中可能出现的概念和涉及的微积分知识,希望你能面试顺利!
















