本文转载自公众号“读芯术”(ID:AI_Discovery)。
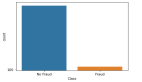
机器学习中的一个常见问题是处理不平衡数据,其中目标类中比例严重失调,存在高度不成比例的数据。
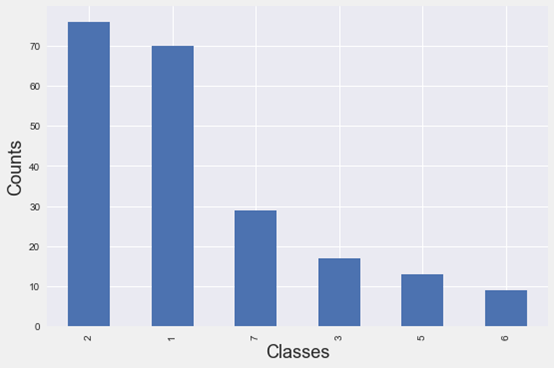
什么是多类不平衡数据?
当分类问题的目标类(两个或两个以上)不均匀分布时,称为不平衡数据。如果不能处理好这个问题,模型将会成为灾难,因为使用类不平衡数据建模会偏向于大多数类。处理不平衡数据有不同的方法,最常见的是过采样(Oversampling)和创建合成样本。
什么是SMOTE算法?
SMOTE是一种从数据集生成合成算例的过采样技术,它提高了对少数类的预测能力。虽然没有信息损失,但它有一些限制。
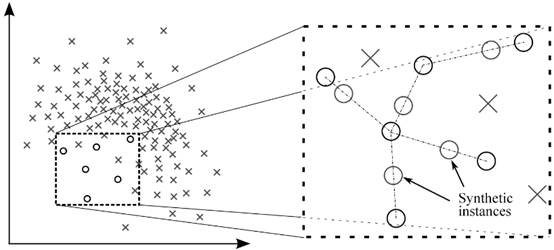
合成样本
限制:
- SMOTE不适用于高维数据。
- 可能会发生类的重叠,并给数据带来更多干扰。
因此,为了跳过这个问题,可以使用'class_weight '参数手动为类分配权重。
为什么使用类别权重(Class weight)?
类别权重通过对具有不同权重的类进行惩罚来直接修改损失函数,有目的地增加少数阶级的权力,减少多数阶级的权力。因此,它比SMOTE效果更好。本文将介绍一些最受欢迎的获得数据的权重的技术,它们对不平衡学习问题十分奏效。
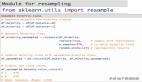
(1) Sklearn utils
可以使用sklearn来获得和计算类权重。在训练模型的同时将这些权重加入到少数类别中,可以提高类别的分类性能。
- from sklearn.utils import class_weightclass_weightclass_weight =class_weight.compute_class_weight('balanced,
- np.unique(target_Y),
- target_Y)model = LogisticRegression(class_weightclass_weight = class_weight)
- model.fit(X,target_Y)# ['balanced', 'calculated balanced', 'normalized'] arehyperpaameterswhic we can play with.
对于几乎所有的分类算法,从逻辑回归到Catboost,都有一个class_weight参数。但是XGboost对二进制分类使用scale_pos_weight,对二进制和多类问题使用样本权重。
(2) 数长比
非常简单明了,用行数除以每个类的计数数,然后
- weights = df[target_Y].value_counts()/len(df)
- model = LGBMClassifier(class_weight = weights)model.fit(X,target_Y)
(3) 平和权重技术(Smoothen Weights)
这是选择权重的最佳方法之一。labels_dict是包含每个类的计数的字典对象,对数函数对不平衡类的权重进行平和处理。
- def class_weight(labels_dict,mu=0.15):
- total = np.sum(labels_dict.values()) keys = labels_dict.keys() weight = dict()for i in keys:
- score =np.log(mu*total/float(labels_dict[i])) weight[i] = score if score > 1else 1return weight# random labels_dict
- labels_dict = df[target_Y].value_counts().to_dict()weights =class_weight(labels_dict)model = RandomForestClassifier(class_weight = weights)
- model.fit(X,target_Y)
(4) 样本权重策略
下面的函数不同于用于为XGboost算法获取样本权重的class_weight参数。它为每个训练样本返回不同的权重。样本权重是一个与数据长度相同的数组,包含应用于每个样本的模型损失的权重。
- def BalancedSampleWeights(y_train,class_weight_coef):
- classes = np.unique(y_train, axis =0)
- classes.sort()class_samples = np.bincount(y_train)total_samples = class_samples.sum()n_classes = len(class_samples) weights = total_samples / (n_classes* class_samples * 1.0)
- class_weight_dict = {key : value for (key, value) in zip(classes, weights)}
- class_weight_dict[classes[1]] = class_weight_dict[classes[1]] *
- class_weight_coefsample_weights = [class_weight_dict[i] for i in y_train]
- return sample_weights#Usage
- weight=BalancedSampleWeights(target_Y,class_weight_coef)
- model = XGBClassifier(sample_weight = weight)
- model.fit(X, target_Y)
(5) 类权重与样本权重:
样本权重用于为每个训练样本提供权重,这意味着应该传递一个一维数组,其元素数量与训练样本完全相同。类权重用于为每个目标类提供权重,这意味着应该为要分类的每个类传递一个权重。
以上是为分类器查找类权重和样本权重的几种方法,所有这些技术都对笔者的项目有效,你可以试试这些技巧,绝对大有帮助。