













图像和视频等视觉数据的生成是机器学习和计算机视觉领域重要的研究问题之一。近几年,英伟达提出了 SPADE、MUNIT 等多个图像及视频合成模型。
近日,英伟达又开源了一个新的 PyTorch 库「Imaginaire」,共包含 9 种英伟达开发的图像及视频合成方法。
项目地址:https://github.com/NVlabs/imaginaire
这九种方法分别为:
有监督的图像到图像转换
1、pix2pixHD
2、SPADE/GauGAN
无监督的图像到图像转换
1、UNIT
2、MUNIT
3、FUNIT
4、COCO-FUNIT
视频到视频转换
1、vid2vid
2、fs-vid2vid
3、wc-vid2vid
pix2pixHD
「pix2pixHD」是 pix2pix 的升级版本,具备高分辨率图像和语义处理功能,主要解决了深度图像合成编辑中的质量及分辨率问题。

项目主页:https://tcwang0509.github.io/pix2pixHD/

论文链接:https://arxiv.org/pdf/1711.11585.pdf
在这篇论文中,来自英伟达和 UC 伯克利的研究者提出了一种使用条件 GAN 从语义标签图上合成高分辨率照片级逼真图像的方法。此前,条件 GAN 已经有了很广泛的应用,但生成结果均为低分辨率并与现实差异较大。因此,研究者使用了一种新的对抗损失、多尺度生成器和判别器架构来生成 2048x1024 的结果。此外,研究者为该框架扩展了两个附加功能。首先,合并了对象实例分割信息,实现了删除 / 添加对象和更改对象类别等操作;其次,提出了一种在相同输入下生成多种结果的方法,让使用者可以编辑对象外观。该论文被 CVPR 2018 接收。
SPADE/GauGAN
在 GTC 2019 上,英伟达展示了一款交互应用「GauGAN」。它可以轻松地将粗糙的涂鸦变成逼真的杰作,令人叹为观止,效果堪比真人摄影师作品。GauGAN 应用主要使用的技术,就是英伟达的 SPADE。

项目主页:https://nvlabs.github.io/SPADE/

论文地址:https://arxiv.org/pdf/1903.07291.pdf
在这篇论文中,来自 UC 伯克利、英伟达、MIT CSALL 的研究者提出了一种空间自适应归一化方法,在给定输入语义布局的情况下,实现了一种简单有效的逼真图像合成层。以前的方法直接将语义布局作为输入提供给深度网络,然后通过卷积、归一化和非线性层处理深度网络。实验表明,这种方法并不是最优的,因为归一化层倾向于「洗去」语义信息。为了解决这个问题,研究者提出使用输入布局,通过空间自适应的、学习的转换来调节归一化层中的激活函数。在几个具有挑战性的数据集上的实验表明,与现有方法相比,该方法在视觉保真度和与输入布局的对齐方面具有优势。最后,该模型允许用户控制合成图像的语义和风格。该论文被 CVPR 2019 接收为 Oral 论文。
UNIT
项目地址:https://github.com/NVlabs/imaginaire/tree/master/projects/unit

论文地址:https://arxiv.org/abs/1703.00848
UNIT(Unsupervised image-to-image translation)旨在通过使用来自单个域中边缘分布的图像来学习不同域中图像的联合分布。由于要达到给定的边缘分布需要一个联合分布的无限集,因此如果没有其他假设,就无法从边缘分布推断联合分布。为了解决这个问题,研究者提出了一个共享潜在空间的假设,并提出了一个基于耦合 GAN 的无监督图像到图像转换框架。
MUNIT
无监督图像到图像转换是计算机视觉领域一个重要而富有挑战的问题:给定源域(source domain)中的一张图像,需要在没有任何配对图像数据的情况下,学习出目标域(target domain)中其对应图像的条件分布。虽然条件分布是多模态的,但此前方法都引入了过于简化的假设,而将其作为一个确定性的一对一映射,因此无法在特定的源域图像中生成富有多样性的输出结果。
项目地址:https://github.com/NVlabs/imaginaire/tree/master/projects/munit

论文地址:https://arxiv.org/abs/1804.04732
在这篇论文中,康奈尔大学和英伟达的研究者提出了多模态无监督图像到图像转换 MUNT 框架。研究者假设,图像表征可以分解为一个具有域不变性(domain-invariant)的内容码(content code)和一个能刻画域特有性质的风格码(style code)。为了将图像转化到另一个域中,研究者将:1. 原图像的内容码,2. 从目标域中随机抽取的某个风格码 进行重组,并分析了 MUNT 框架,并建立了相应的理论结果。大量实验表明,将 MUNT 与其他 SOTA 方法相比具备优越性。最后,通过引入一个风格图像(style image)样例,使用者可以利用 MUNT 来控制转化的输出风格。
FUNIT
项目地址:https://github.com/NVlabs/imaginaire/tree/master/projects/funit

论文地址:https://arxiv.org/abs/1905.01723
虽然此前无监督图像到图像转换算法在很多方面都非常成功,尤其是跨图像类别的复杂外观转换,但根据先验知识从新一类少量样本中进行泛化的能力依然无法做到。具体来说,如果模型需要在某些类别上执行图像转换,那么这些算法需要所有类别的大量图像作为训练集。也就是说,它们不支持 few-shot 泛化。总体而言有以下两方面的限制:
其一,这些方法通常需要在训练时看到目标类的大量图像;
其二,用于一个转换任务的训练模型在测试时无法应用于另一个转换任务。
在这篇论文中,英伟达的研究者提出一种 Few-shot 无监督图像到图像转换(FUNIT)框架。该框架旨在学习一种新颖的图像到图像转换模型,从而利用目标类的少量图像将源类图像映射到目标类图像。也就是说,该模型在训练阶段从未看过目标类图像,却被要求在测试时生成一些目标类图像。
COCO-FUNIT
项目地址:https://github.com/NVlabs/imaginaire/tree/master/projects/coco_funit

论文地址:https://nvlabs.github.io/COCO-FUNIT/paper.pdf
COCO-FUNIT 之前的图像到图像变换模型在模拟不可见域的外观时很难保留输入图像的结构,这被称为内容丢失问题。当输入图像和示例图像中对象的姿势有较大差异时,这个问题尤其严重。为了解决这个问题,研究者提出了一种新的 few-shot 的图像变换模型,即 COCO-FUNIT。
vid2vid
2018 年,英伟达联合 MIT CSAIL 开发出了直接视频到视频的转换系统。该系统不仅能用语义分割掩码视频合成真实街景视频,分辨率达到 2K,能用草图视频合成真实人物视频,还能用姿态图合成真人舞蹈视频。此外,在语义分割掩码输入下,只需换个掩码颜色,该系统就能直接将街景中的树变成建筑。
项目主页:https://tcwang0509.github.io/vid2vid/

论文地址:https://arxiv.org/abs/1808.06601
在这篇论文中,来自英伟达和 MIT 的研究者提出了一种新型的生成对抗网络框架下的视频到视频合成方法。通过精心设计生成器和判别器架构,结合空间 - 时间对抗目标函数,研究者在多种输入视频格式下生成了高分辨率、时间连贯的照片级视频,其中多种形式的输入包括分割掩码、草图和姿态图。在多个基准上的实验结果表明,相对于强基线,本文方法更具优越性,该模型可以合成长达 30 秒的 2K 分辨率街景视频,与当前最佳的视频合成方法相比具备显著的优势。研究者将该方法应用到未来视频预测中,表现均超越其他方法。该论文被 NeurIPS 2018 接收。
Few-shot vid2vid
「vid2vid」旨在将人体姿态或分割掩模等输入的语义视频,转换为逼真的输出视频,但它依然存在以下两种局限:其一,现有方法极其需要数据。训练过程中需要大量目标人物或场景的图像;其二,学习到的模型泛化能力不足。姿态到人体(pose-to-human)的 vid2vid 模型只能合成训练集中单个人的姿态,不能泛化到训练集中没有的其他人。
2019 年,英伟达又推出了新的「few-shot vid2vid」框架,仅借助少量目标示例图像就能合成之前未见过的目标或场景的视频,在跳舞、头部特写、街景等场景中都能得到逼真的结果。
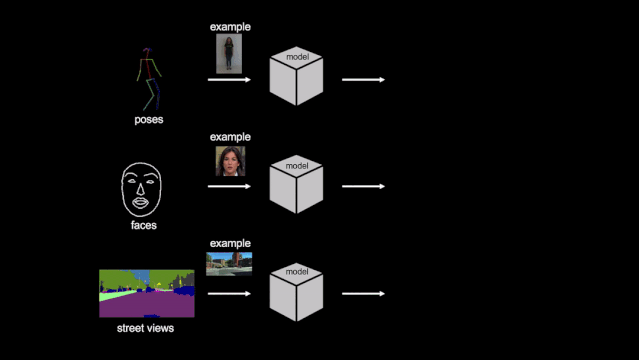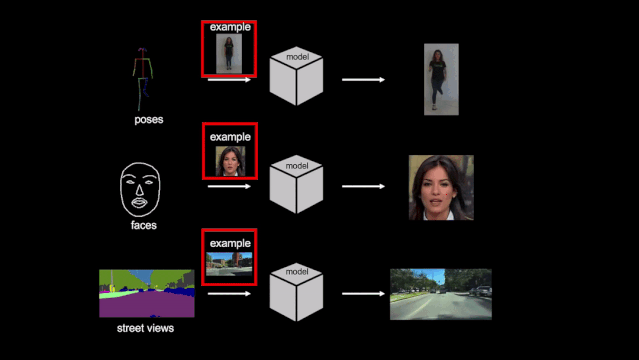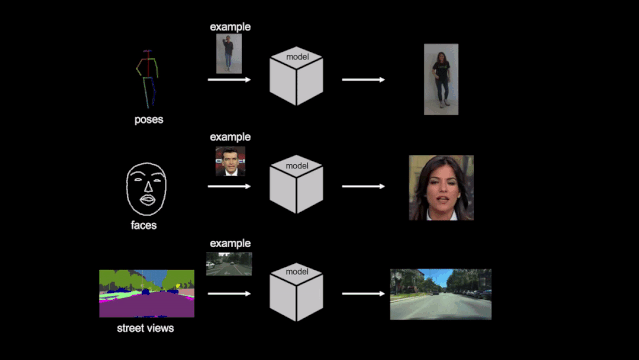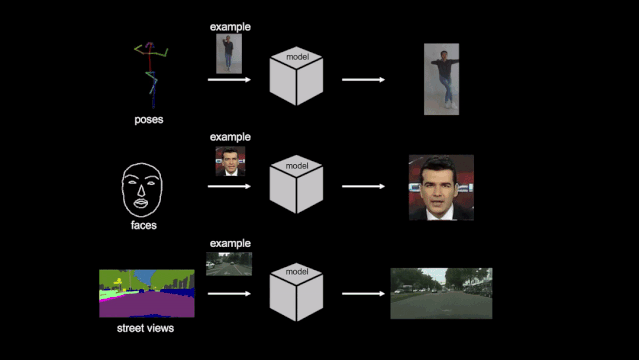
项目主页:https://nvlabs.github.io/few-shot-vid2vid/

论文地址:https://arxiv.org/pdf/1910.12713.pdf
在这篇论文中,英伟达的研究者提出了一种 few-shot vid2vid 框架,该框架在测试时通过利用目标主体的少量示例图像,学习对以前未见主体或场景的视频进行合成。
借助于一个利用注意力机制的新型网络权重生成模块,few-shot vid2vid 模型实现了在少样本情况下的泛化能力。研究者进行了大量的实验验证,并利用人体跳舞、头部特写和街景等大型视频数据集与强基准做了对比。
实验结果表明,英伟达提出的 few-shot vid2vid 框架能够有效地解决现有方法存在的局限性。该论文被 NeurIPS 2019 接收。
World Consistent vid2vid
「World Consistent vid2vid」是英伟达在 2020 年 7 月推出的一种视频到视频合成方法。vid2vid 视频编码方法能够实现短时间的时间一致性,但在长时间的情况下不能时间一致性。这是因为对 3D 世界渲染方式缺乏了解,并且只能根据过去的几帧来生成每一帧。
项目主页:https://nvlabs.github.io/wc-vid2vid/

论文地址:https://arxiv.org/pdf/2007.08509.pdf
在这篇论文中,英伟达的研究者引入了一个新的视频渲染框架,该框架能够在渲染过程中有效利用过去生成的所有帧,来改善后续视频的合成效果。研究者利用「制导图像」,并进一步提出了一种新的神经网络结构以利用存储在制导图像中的信息。一系列实验结果表明,该方法具备良好表现,输出视频在 3D 世界渲染上是一致的。



























