













本文转自雷锋网,如需转载请至雷锋网官网申请授权。
无专业背景知识,也可以写出专业文案。
这就是NLP可以辅助人类做的事,它通过预训练模型查找相关内容,并解释上下文来完成一系列文本任务。
目前,诸如GPT-3等通用NLP模型已经在文本生成领域展现出强大的性能,它表明预训练模型可以在参数中储备大量知识,在执行特定任务时,只需调用和微调即可得到SOTA结果。
但这款被称为“暴力美学”的超大模型,以及普遍的通用NLP,在预训练成本、处理知识密集型(Knowledge-Intensive Tasks,)任务等方面仍然存在一定的局限性。
对此,Facebook提出了一种检索增强生成(Retrieval-Augmented Generation,RAG)模型的解决方法。

这篇名为《检索增强生成处理知识密集型NLP任务》的论文表明,RAG预训练模型在微调下游任务时,同样可以达到最佳结果。
不同的是,与其他如预训练模型相比,它可以对内部知识进行随时补充和调整,无需浪费时间或因计算能力重新训练整个模型。
检索增强型语言模型,更高效、更灵活
检索增强生成(RAG)架构,是一个端到端的可微模型,主要由问题编码器、神经检索器、生成器模型三个部分构成。
其中生成器采用的是Seq2Seq模型,神经检索器访问的是维基百科密集向量索引,二者通过结合预训练的参数存储(Parametric Memory)与非参数存储(Nonparametric Memory)来生成语言。
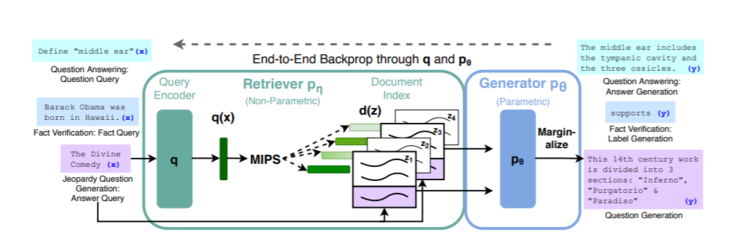
采用标准Seq2Seq模型,意味着RAG无需考虑序列长度和顺序,每个输入对应一个输出序列,但不同的是,RAG不会直接将输入结果直接传递给生成器,而是使用输入来检索一组相关文档,这也让RAG在性能比传统Seq2Seq模型有所提升。
举个例子,在以下问题编码器中,输入“第一个哺乳动物是什么时候出现在地球上?”
RAG会先从Wikipedia之类的数据库中检索一组相关文档。如与“哺乳动物”,“地球历史”和“哺乳动物进化”相关的内容,然后将这些内容作为上下文与输入串联起来,一起馈入到模型以产生最终的输出文本。
因此,RAG具有两种知识来源。一是seq2seq模型存储在其参数中的知识,即参数存储;二是检索语料库中存储的知识,也就是非参数存储。
这种两种知识来源是相辅相成的。Facebook在博客中表明,
RAG使用非参数内存来“提示” Seq2Seq模型生成正确的响应,这种方式相当于将“仅参数存储”方法的灵活性与“基于检索”方法的性能结合在了一起。
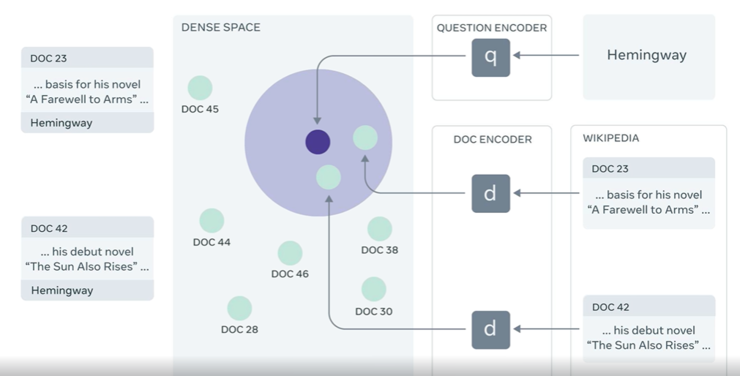
RAG采用后期融合(Late Fusion)的形式来整合所有检索到的文档中的知识,这意味着它会根据文档内容提前进行答案预测,然后再汇总最终的预测结果。这种后期融合的形式可以让输出中的错误信号反向传播到检索机制中,这可以大大提高端到端系统的性能。
另外,Facebook研究团队表示,RAG最大的一个优势在于它的灵活性。更改预先训练的语言模型所知道的内容需要使用新文档对整个模型进行重新训练,而这对于RAG而言,只需交换掉用于知识检索的文档即可,相比较而言,它更快速且高效。
基于精准的文档输入,参数存储与非参数存储结合的方法,RAG在文本生成方面表现出了很高的性能,在某些情况下,它甚至可以自己生成答案,而这些答案不包含在任何检索到的文档中。
开放域问答测试,擅长知识密集型任务
论文中,研究人员在NaturalQuestions(NQ),CuratedTrec(CT),TriviaQA
(TQA)以及WebQuestions(WQ)四个开放域问答(Open-QA)中,对RAG的性能进行了基准测试。Open-QA是用于知识密集任务测试的常用应用程序。
在标准问答任务中,诸如“等边三角形一角是多少度“之类的问题,模型只需从输入的文档找查找答案即可,但Open-QA并不会提供特定文档,需要模型自主查找知识。由此,Open-QA是检测RAG性能非常好的工具。
论文中,研究人员采用了Jeopardy的问题形式,它是一种精确的、事实性的陈述,如“世界杯”,Jeopardy问题的回答是“1986年墨西哥成为第一个举办世界杯的国家”。
结果显示,RAG在知识密集型自然语言问题上表现出色,与其他模型相比,RAG产生的Jeopardy问题更为具体,多样且真实,这可能是由于RAG能够使用从多个来源获取的不同信息合成响应的能力有关。
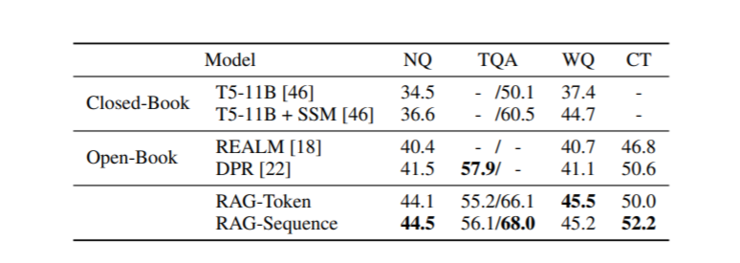
Closed-Book代表“仅参数化”,Open-Book代表“检索方法”
如图,RAG结合仅参数化和基于检索方法,在各个Open-QA中,其性能非常显著。另外,与REALM和T5+SSM不同的是,RAG无需高成本的“Salient Span Masking”预培训,只依靠现成的组件就可以获得如此效果。
Facebook在博客中也表明,RAG可以帮助研究人员快速开发和部署,以解决知识密集型任务。他们表示,未来对知识密集型任务的处理将是NLP主要的研究方向之一,而RAG通过引入检索的方法,“允许NLP模型绕过再培训步骤,直接访问和提取最新信息,最后使用生成器输出结果”的方式表现出了良好的性能。
目前,这项研究已经在Github开源,感兴趣的朋友的来体验一下~
Github地址:https://github.com/huggingface/transformers/blob/master/model_cards/facebook/rag-token-nq/README.md
Wikipedia 语料库:https://archive.org/details/wikimediadownloads
论文地址:https://arxiv.org/pdf/2005.11401.pdf
















