













本文转载自微信公众号「云巅论剑」,作者费曼 。转载本文请联系云巅论剑公众号。
1. 概述
传统高性能网络编程通常是基于select, epoll, kequeue等机制实现,网络上有非常多的资料介绍基于这几种接口的编程模型,尤其是epoll,nginx, redis等都基于其构建,稳定高效,但随着linux kernel主线在v5.1版本引入io_uring新异步编程框架,在高并发网络编程方面我们多了一个利器。
io_uring在进行初始设计时就充分考虑其框架自身的高性能和通用性,不仅仅面向传统基于块设备的fs/io领域,对网络异步编程也提供支持,其最终目的是实现linux下一切基于文件概念的异步编程。
2. echo_server场景下的性能对比
我们先看下io_uring和epoll在echo_server模型下的性能对比,测试环境为:
1. server端cpu Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz, client端cpu Intel(R) Xeon(R) CPU E5-2630 0 @ 2.30GHz
2. 两台物理机器,一台做server, 一台做client。
Note: 如下性能数据都是在meltdown和spectre漏洞修复场景下测试。
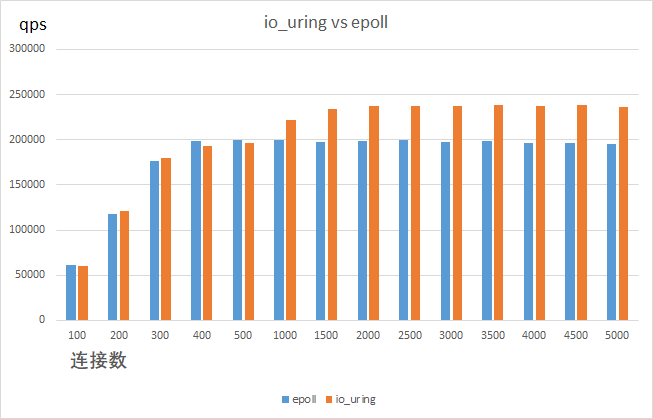
上图是io_uring和epoll在echo_server场景下qps数据对比,可以看出在笔者的测试环境中,连接数1000及以上时,io_uring的性能优势开始体现,io_uring的极限性能单core在24万qps左右,而epoll单core只能达到20万qps左右,收益在20%左右。
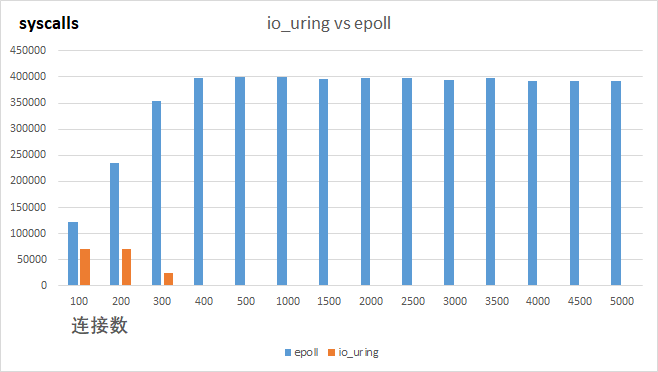
上图统计的是io_uring和epoll在echo_server场景下系统调用上下文切换数量的对比,可以看出io_uring可以极大的减少用户态到内核态的切换次数,在连接数超过300时,io_uring用户态到内核态的切换次数基本可以忽略不计。
3. epoll 网络编程模型
下面展开介绍epoll和io_uring两种编程模型基本用法对比,首先介绍下传统的epoll网络编程模型, 通常采用如下模式:
struct epoll_event ev;
/* for accept(2) */
ev.events = EPOLLIN;
ev.data.fd = sock_listen_fd;
epoll_ctl(epollfd, EPOLL_CTL_ADD, sock_listen_fd, &ev);
/* for recv(2) */
ev.events = EPOLLIN | EPOLLET;
ev.data.fd = sock_conn_fd;
epoll_ctl(epollfd, EPOLL_CTL_ADD, sock_conn_fd, &ev);
然后在一个主循环中:
new_events = epoll_wait(epollfd, events, MAX_EVENTS, -1);
for (i = 0; i < new_events; ++i) {
/* process every events */
...
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
本质上是实现类似如下事件驱动结构:
struct event {
int fd;
handler_t handler;
};
- 1.
- 2.
- 3.
- 4.
将fd通过epoll_ctl进行注册,当该fd上有事件ready, 在epoll_wait返回时可以获知完成的事件,然后依次调用每个事件的handler, 每个handler里调用recv(2), send(2)等进行消息收发。
4. io_uring 网络编程模型
io_uring的网络编程模型不同于epoll, 以recv(2)为例,它不需要通过epoll_ctl进行文件句柄的注册,io_uring首先在用户态用sqe结构描述一个io 请求,比如此处的recv(2)系统调用,然后就可以通过io_uring_enter(2)系统调用提交该recv(2)请求,用户程序通过调用io_uring_submit_and_wait(3),类似于epoll_wait(2),获得完成的io请求,cqe结构用于描述完成的ioq请求。
/* 用sqe对一次recv操作进行描述 */
struct io_uring_sqe *sqe = io_uring_get_sqe(ring);
io_uring_prep_recv(sqe, fd, bufs[fd], size, 0);
/* 提交该sqe, 也就是提交recv操作 */
io_uring_submit(&ring);
/* 等待完成的事件 */
io_uring_submit_and_wait(&ring, 1);
cqe_count = io_uring_peek_batch_cqe(&ring, cqes, sizeof(cqes) / sizeof(cqes[0]));
for (i = 0; i < cqe_count; ++i) {
struct io_uring_cqe *cqe = cqes[i];
/* 依次处理reap每一个io请求,然后可以调用请求对应的handler */
...
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
总结下:为什么io_uring相比epoll模型能极大的减少用户态到内核态的上下文切换?举个简单例子,epoll_wait返回1000个事件,则用户态程序需要发起1000个系统调用,则就是1000个用户态和内核态切换,而io_uring可以初始化1000个io请求的sqes, 然后调用一次io_uring_enter(2)系统调用就可以下发这1000个请求。
在meltdown和spectre漏洞没有修复的场景下,io_uring相比于epoll的提升几乎无,甚至略有下降,why? 我们不是减少了大量的用户态到内核态的上下文切换?
原因是在meldown和spectre漏洞没有修复的场景下,用户态到内核态的切换开销很小,所带来的的收益不足以抵消io_uring框架自身的开销,这也说明io_uirng框架本身需要进一步的优化。
详细的epoll和io_uring基于echo_server模型的对比程序在 :https://github.com/OpenAnolis/io_uring-echo-server(详见原文链接)。
5. 接下来的工作
1.目前从分析来看,io_uring框架本身存在的overhead不容小觑,需要进一步优化,我们已经在io_uring社区进行io_uring框架开销不断增大的讨论,并已经开展了一系列的优化尝试。
2.echo_server代表着一类编程模型,不是真实的应用,但redis, nginx等应用其实都是基于echo_server模型,将其用io_uirng来改造,理论上在cpu 漏洞修复场景下都会带来明显性能提升,我们已经在开展nginx, redis的io_uring适配工作,后续会有进一步的介绍。





















