jdk1.7 hashmap的循环依赖问题是面试经常被问到的问题,如何回答不好,可能会被扣分。今天我就带大家一下梳理一下,这个问题是如何产生的,以及如何解决这个问题。
一、hashmap的数据结构
先一起看看jdk1.7 hashmap的数据结构
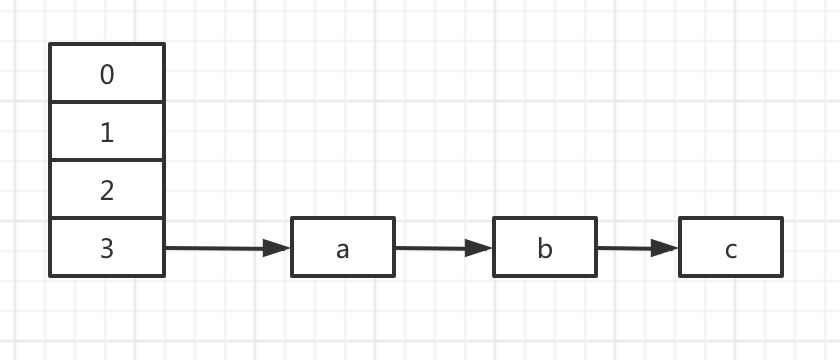
数组 + 链表
hashmap会给每个元素的key生成一个hash值,然后根据这个hash值计算一个在数组中的位置i。i不同的元素放在数组的不同位置,i相同的元素放在链表上,最新的数据放在链表的头部。
往hashmap中保存元素会调用put方法,获取元素会调用get方法。接下来,我们重点看看put方法。
二、put方法
重点看看put方法
- public V put(K key, V value) {
- if (table == EMPTY_TABLE) {
- inflateTable(threshold); } if (key == null)
- return putForNullKey(value);
- //根据key获取hash
- int hash = hash(key); //计算在数组中的下表
- int i = indexFor(hash, table.length); //变量集合查询相同key的数据,如果已经存在则更新数据
- for (Entry<K,V> e = table[i]; e != null; e = e.next) {
- Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
- V oldValue = e.value; e.value = value; e.recordAccess(this); //返回已有数据
- return oldValue;
- } } modCount++; //如果不存在相同key的元素,则添加新元素
- addEntry(hash, key, value, i); return null;
- }
再看看addEntry方法
- void addEntry(int hash, K key, V value, int bucketIndex) {
- // 当数组的size >= 扩容阈值,触发扩容,size大小会在createEnty和removeEntry的时候改变 if ((size >= threshold) && (null != table[bucketIndex])) {
- // 扩容到2倍大小,后边会跟进这个方法 resize(2 * table.length); // 扩容后重新计算hash和index
- hash = (null != key) ? hash(key) : 0;
- bucketIndex = indexFor(hash, table.length);
- } // 创建一个新的链表节点,点进去可以了解到是将新节点添加到了链表的头部 createEntry(hash, key, value, bucketIndex);
- }
看看resize是如何扩容的
- void resize(int newCapacity) {
- Entry[] oldTable = table; int oldCapacity = oldTable.length;
- if (oldCapacity == MAXIMUM_CAPACITY) {
- threshold = Integer.MAX_VALUE; return;
- } // 创建2倍大小的新数组
- Entry[] newTable = new Entry[newCapacity];
- // 将旧数组的链表转移到新数组,就是这个方法导致的hashMap不安全,等下我们进去看一眼
- transfer(newTable, initHashSeedAsNeeded(newCapacity));
- table = newTable;
- // 重新计算扩容阈值(容量*加载因子)
- threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
- }
出问题的就是这个transfer方法
- void transfer(Entry[] newTable, boolean rehash) {
- int newCapacity = newTable.length; // 遍历旧数组
- for (Entry<K,V> e : table) {
- // 遍历链表
- while(null != e) {
- //获取下一个元素,记录到一个临时变量,以便后面使用
- Entry<K,V> next = e.next;
- if (rehash) {
- e.hash = null == e.key ? 0 : hash(e.key);
- } // 计算节点在新数组中的下标
- int i = indexFor(e.hash, newCapacity);
- // 将旧节点插入到新节点的头部
- e.next = newTable[i];
- //这行才是真正把数据插入新数组中,前面那行代码只是设置当前节点的next
- //这两行代码决定了倒序插入
- //比如:以前同一个位置上是:3,7,后面可能变成了:7、3
- newTable[i] = e;
- //将下一个元素赋值给当前元素,以便遍历下一个元素
- e = next;
- }
- }
- }
我来给大家分析一下,为什么这几个代码是头插法,网上很多技术文章都没有说清楚。
三、头插法
我们把目光聚焦到这几行代码:
- //获取下一个元素,记录到一个临时变量,以便后面使用
- Entry<K,V> next = e.next;
- // 计算节点在新数组中的下标 int i = indexFor(e.hash, newCapacity); // 将旧节点插入到新节点的头部 e.next = newTable[i];
- //这行才是真正把数据插入新数组中,前面那行代码只是设置当前节点的next
- newTable[i] = e; //将下一个元素赋值给当前元素,以便遍历下一个元素 e = next;
假设刚开始hashMap有这些数据
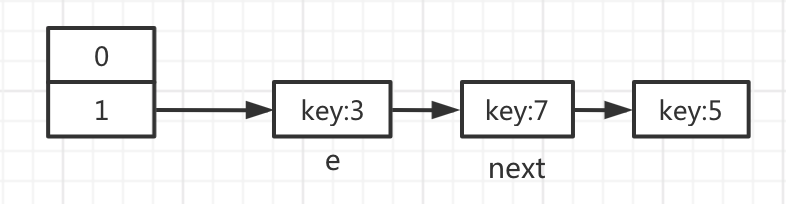
调用put方法需要进行一次扩容,刚开始会创建一个空的数组,大小是以前的2倍,如图所示:
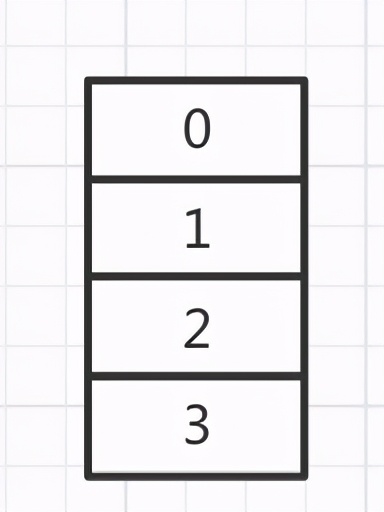
开始第一轮循环:
- //next= 7 e = 3 e.next = 7
- Entry<K,V> next = e.next;
- // i=3
- int i = indexFor(e.hash, newCapacity);//e.next = null ,刚初始化时新数组的元素为null
- e.next = newTable[i];
- //给新数组i位置 赋值 3
- newTable[i] = e;// e = 7
- e = next;
执行完之后,第一轮循环之后数据变成这样的
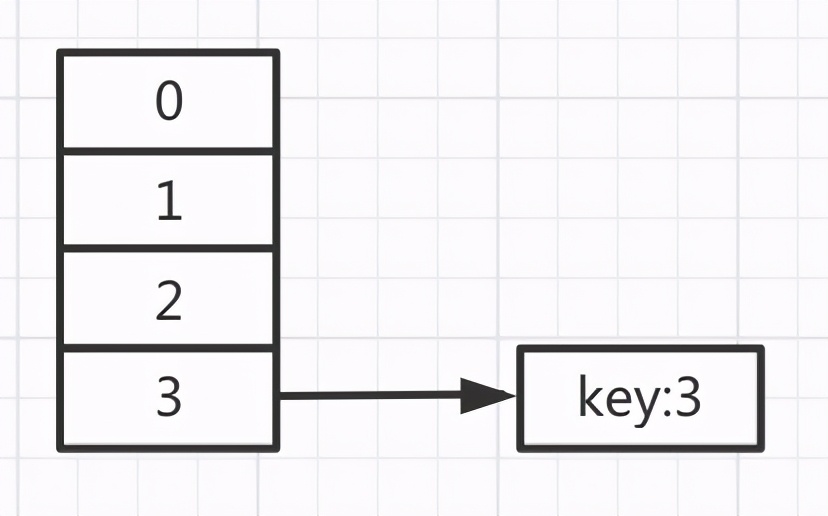
再接着开始第二轮循环:
- //next= 5 e = 7 e.next = 5
- Entry<K,V> next = e.next;
- // i=3
- int i = indexFor(e.hash, newCapacity);//e.next = 3 ,此时相同位置上已经有key=3的值了,将该值赋值给当前元素的next
- e.next = newTable[i];
- //给新数组i位置 赋值 7
- newTable[i] = e;// e = 5
- e = next;
上面会构成一个新链表,连接的顺序正好反过来了。
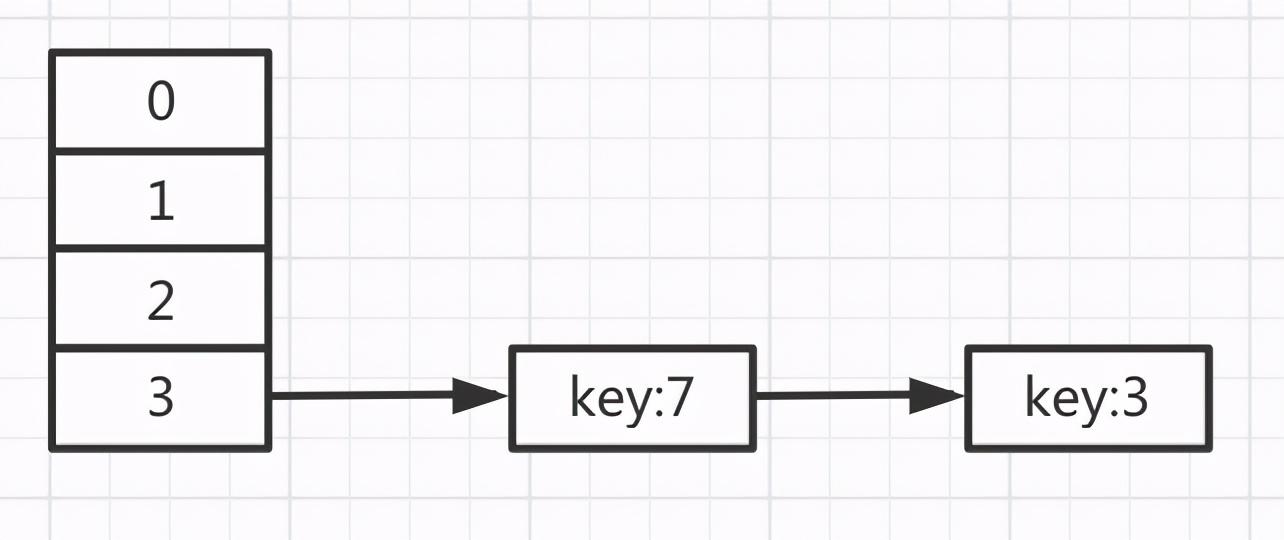
由于第二次循环时,节点key=7的元素插到相同位置上已有元素key=3的前面,所以说是采用的头插法。
四、死循环的产生
接下来重点看看死循环是如何产生的?
假设数据跟元素数据一致,有两个线程:线程1 和 线程2,同时执行put方法,最后同时调用transfer方法。
线程1 先执行,到 Entry next = e.next; 这一行,被挂起了。
- //next= 7 e = 3 e.next = 7
- Entry<K,V> next = e.next;
- int i = indexFor(e.hash, newCapacity);e.next = newTable[i];
- newTable[i] = e;e = next;
此时线程1 创建的数组会创建一个空数组
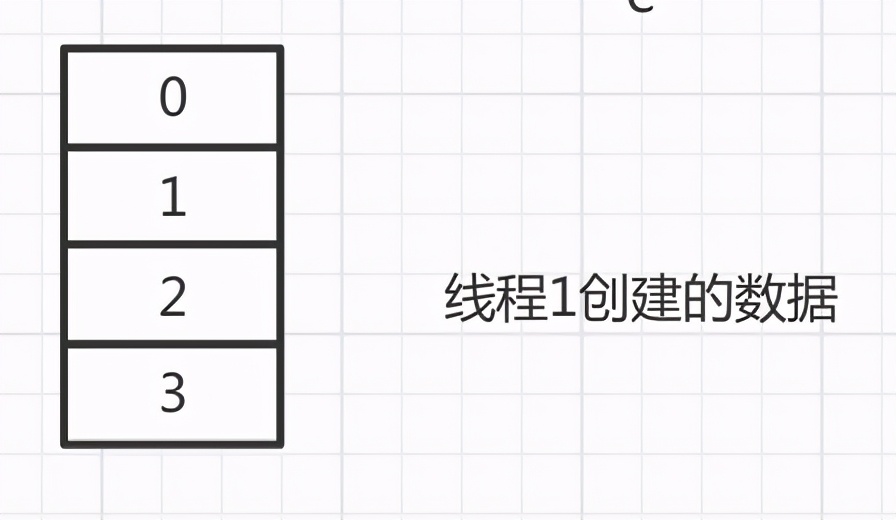
接下来,线程2开始执行,由于线程2运气比较好,没有被中断过,执行完毕了。
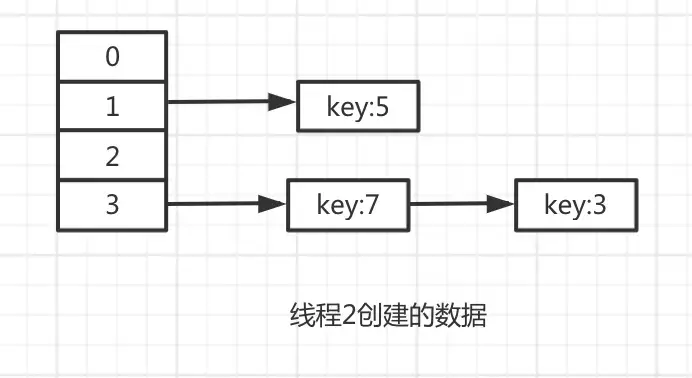
过一会儿,线程1被恢复了,重新执行代码。
- //next= 7 e = 3 e.next = 7
- Entry<K,V> next = e.next;
- // i = 3
- int i = indexFor(e.hash, newCapacity);// e.next = null,刚初始化时新数组的元素为null
- e.next = newTable[i];
- // 给新数组i位置 赋值 3
- newTable[i] = e;// e = 7
- e = next;
这时候线程1的数组会变成这样的
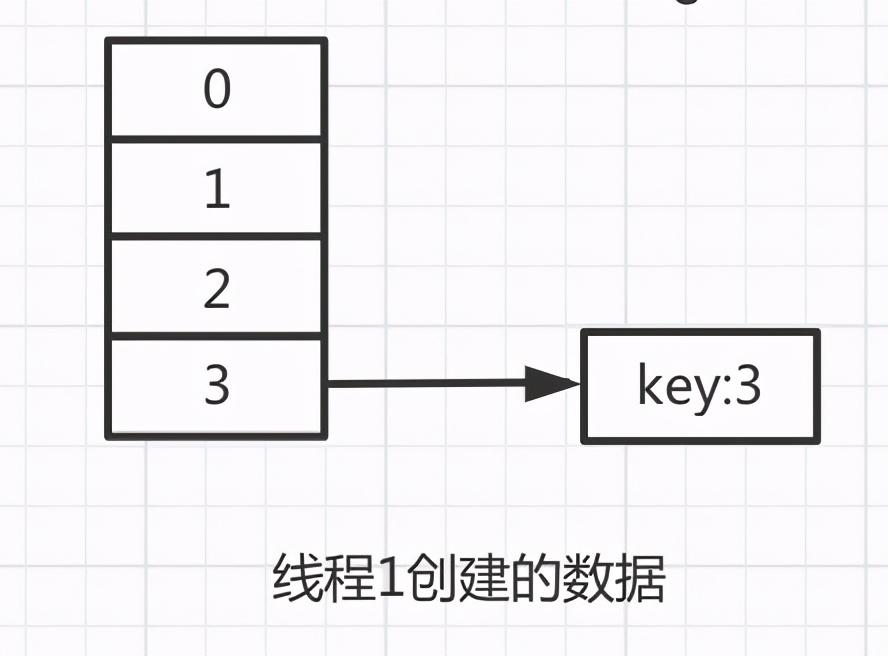
再执行第二轮循环,此时的e=7
- //next= 3 e = 7 e.next = 3
- Entry<K,V> next = e.next;
- // i = 3
- int i = indexFor(e.hash, newCapacity);// e.next = 3,此时相同位置上已经有key=3的值了,将该值赋值给当前元素的next
- e.next = newTable[i];
- // 给新数组i位置 赋值 7
- newTable[i] = e;// e = 3
- e = next;
这里特别要说明的是 此时e=7,而e.next为什么是3呢?
因为hashMap的数据是公共的,还记得线程2中的生成的数据吗?
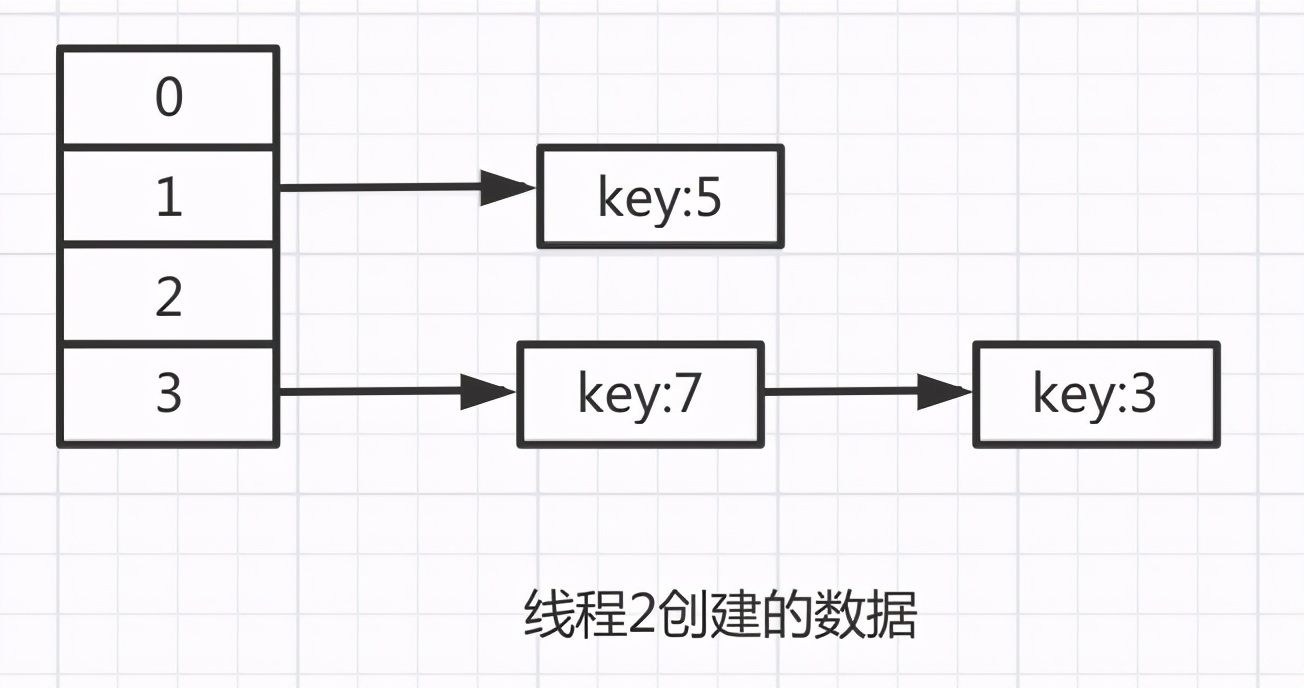
此时e=7,那么e.next肯定是3。
经过上面第二轮循环之后,线程1得到的数据如下:
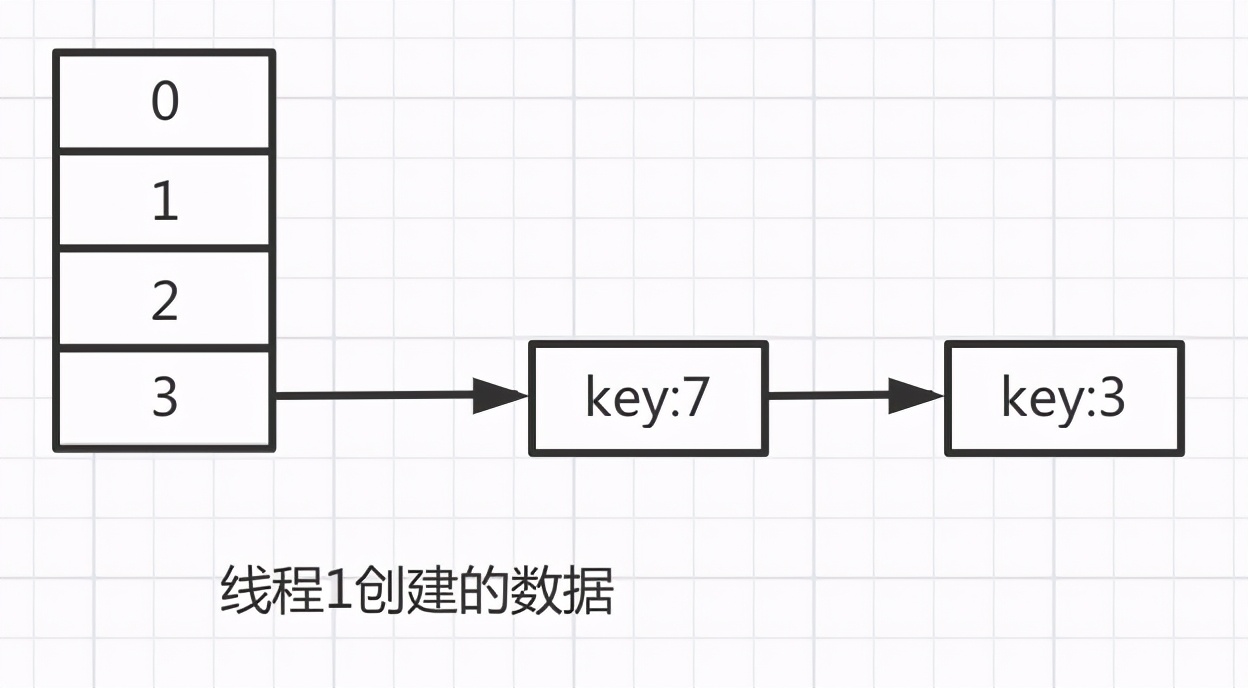
此时由于循环判断还没有退出,判断条件是: while(null != e),所以要开始第三轮循环:
- //next= null e = 3 e.next = null
- Entry<K,V> next = e.next;
- // i = 3
- int i = indexFor(e.hash, newCapacity);// e.next = 7,关键的一步,由于第二次循环是 key:7 .next = key:3,现在key:3.next = key:7
- e.next = newTable[i];
- // 给新数组i位置 赋值 3
- newTable[i] = e;// e = nulle = next;
由于e=null,此时会退出循环,最终线程1的数据会是这种结构:
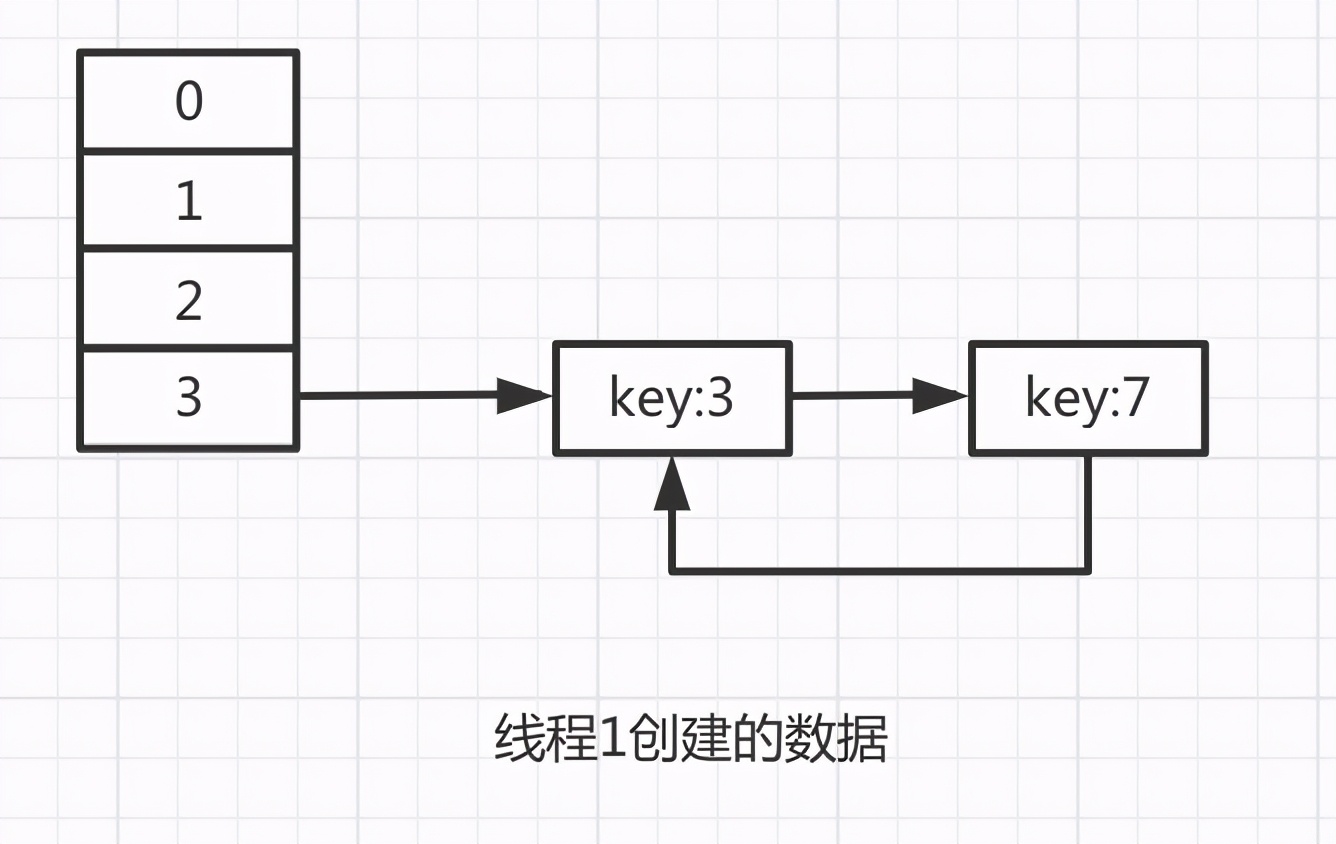
key:3 和 key:7又恢复了刚开始的顺序,但是他们的next会相互引用,构成环形引用。
注意,此时调用hashmap的get方法获取数据时,如果只是获取循环链上key:3 和 key:7的数据,是不会有问题的,因为可以找到。就怕获取循环链上没有的数据,比如:key:11,key:15等,会进入无限循环中导致CPU使用率飙升。
五、如何避免死循环
为了解决这个问题,jdk1.8把扩容是复制元素到新数组由 头插法 改成了 尾插法 。此外,引入了红黑树,提升遍历节点的效率。在这里我就不过多介绍了,如果有兴趣的朋友,可以关注我的公众号,后面会给大家详细分析jdk1.8的实现,以及 jdk1.7、jdk1.8 hashmap的区别。
此外,HashMap是非线程安全的,要避免在多线程的环境中使用HashMap,而应该改成使用ConcurrentHashMap。
所以总结一下要避免发生死循环的问题的方法:
- 改成ConcurrentHashMap
PS. 即使JDK升级到1.8任然有死循环的问题。