有水友在评论中留言问我:
| 沈老师,我在一家创业公司,大概有20人左右的研发团队。
团队正在推进前后端分离,我觉得架构变得复杂了,项目研发周期变长了,但组长说,互联网公司都在搞前后端分离,所以我们也要搞。 我还是不理解,为什么要进行前后端分离呀? |
今天,简单说说,互联网分层架构里的前后端分离。
画外音:“别人在搞xxoo技术”一定不能成为,一家公司推动“xxoo技术”的理由。
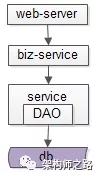
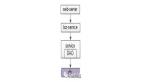
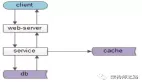
上图,是一个典型的互联网分层架构:
- 业务站点层:web-server;
- 业务服务层:biz-service;
- 基础数据服务层:data-service;
- 数据存储层:db+cache;
随着时间的推移,业务越来越复杂,改版越来越多,此时业务站点层web-server层虽然使用了MVC架构,但以下诸多痛点是否似曾相识?
(1)产品追求绚丽的效果,并对设备兼容性要求高,这些需求不断折磨着使用MVC的Java工程师们;
画外音:本文以Java后端举例。
(2)不管是PC,还是手机H5,还是APP,应用前端展现的变化频率远远大于后端逻辑的变化频率,改velocity模版并不是Java工程师喜欢和擅长的工作;
画外音:感谢那些喜欢做改版的产品经理。
此时,为了缓解这些问题,一般会成立单独的前端FE部门,来负责交互与展现的研发,其职责与后端Java工程师分离开,但痛点真的解决了吗?
- 一点点展现的改动,需要Java工程师们重新编译,打包,上线,重启tomcat,效率极低;
- 原先Java工程师负责所有MVC的研发工作,现在分为Java和FE两块,需要等前端和后端都完成研发,才能一起调试整体效果,不仅增加了沟通成本,任何一块出问题,都可能导致项目延期;
画外音:你有没有被折磨过?
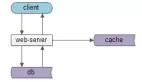
更具体的,看一个这样的例子,最开始产品只有PC版本,此时其系统分层架构如下:
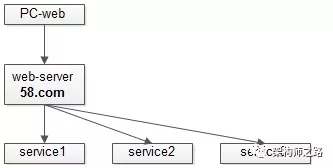
客户端,web-server,service,非常清晰。
随着业务的发展,产品需要新增Mobile版本,Mobile版本和PC版本大部分业务逻辑都一样,区别是什么呢?
- 信息展现的条数会比较少,即调用service服务时,传入的参数会不一样;
- 产品功能会比较少,大部分service的调用一样,少数service不需要调用;
- 展现,交互会有所区别;
由于工期较紧,Mobile版本的web-server一般怎么来呢?
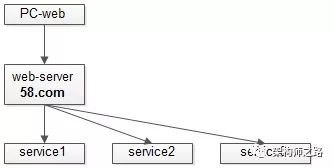
没错,把PC版本的工程拷贝一份,然后再做小量的修改:
- service调用的参数有些变化;
- 大部分service的调用一样,少数service的调用去掉;
- 修改展现,交互相关的代码;
画外音:你有没有拷贝过代码?
业务继续发展,产品又需要新增APP版本,APP版本和Mobile版本业务逻辑完全相同,区别是什么呢?
(1)Mobile版本返回html格式的数据,APP版本返回json格式的数据,然后进行本地渲染;
由于工期较紧,APP版本的web-server一般怎么来呢?
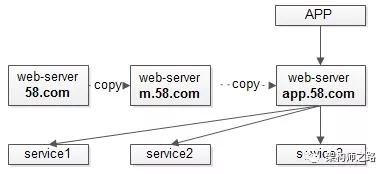
没错,把Mobile版本的工程拷贝一份,然后再做小量的修改:
(2) 把拼装html数据的代码,修改为拼装json数据;
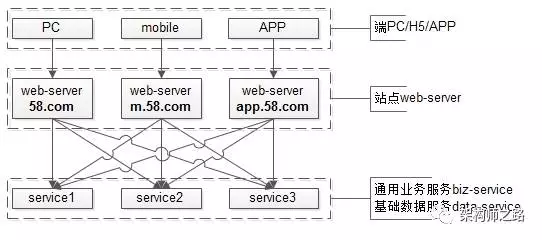
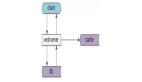
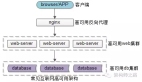
这么迭代演化,架构会进化成什么样子?
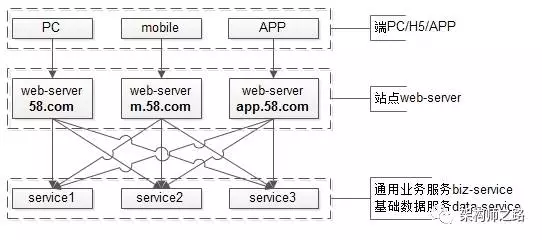
- 端:是PC,Mobile,APP;
- 站点应用层:是PC站,M站,APP站;
- 服务层:通用的业务服务,以及基础数据服务;
这个架构图中的依赖关系是不是看上去很别扭?
- 端到web-server之间连接关系很清晰;
- web-server与service之间的连接关系变成了蜘蛛网;
上述分层架构,可能存在什么问题呢?
PC/H5/APP的web-server层大部分业务是相同的,只有少数的逻辑/展现/交互不一样:
- 一旦一个服务RPC接口有稍许变化,所有web-server系统都需要升级修改;
- web-server之间存在大量代码拷贝;
- 一旦拷贝代码,出现一个bug,多个子系统都需要升级修改;
如何让数据的获取更加高效快捷,如何让数据生产与数据展现解耦分离呢?
前后端分离的分层抽象势在必行。
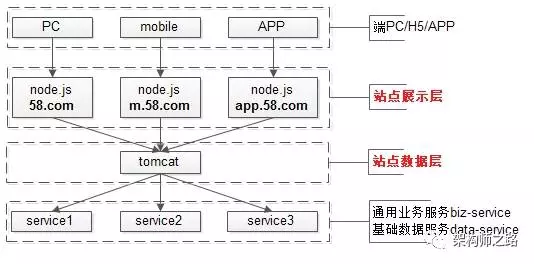
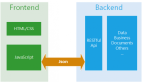
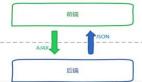
通过前后端分离分层抽象:
- 站点展示层:node.js,负责数据的展现与交互,由FE维护;
- 站点数据层:web-server,负责业务逻辑与json数据接口的提供,由Java工程师维护;
这样做有什么好处呢?
- 复杂的业务逻辑与数据生成,只有在站点数据层处写了一次,没有代码拷贝;
- 底层service接口发生变化,只有站点数据层一处需要升级修改;
- 底层service如果有bug,只有站点数据层一处需要升级修改;
- 站点展现层可以根据产品的不同形态,传入不同的参数,调用不同的站点数据层接口;
除此之外,还有其他诸多优点:
- 产品追求绚丽的效果,并对设备兼容性要求高,不再困扰Java工程师,由更专业的FE对接;
- 一点点展现的改动,不再需要Java工程师们重新编译,打包,上线,重启tomcat;
- 约定好json接口后,Java和FE分开开发,FE可以用mock的接口自测,不再等待一起联调;
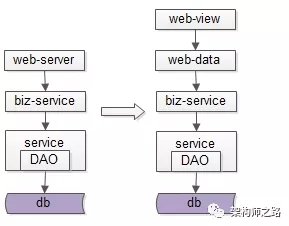
于是乎,如上图所示,架构进化了,前后端分离了。
当业务越来越复杂,端上的产品越来越多,展现层的变化越来越快越来越多,站点层存在大量代码拷贝,数据获取复杂性成为通用痛点的时候,就应该进行前后端分离分层抽象,简化数据获取过程,提高数据获取效率,向上游屏蔽底层的复杂性。
另外要强调的是,是否需要前后端分离,和业务复杂性,业务发展阶段,人员素质模型有关,千万不可一概而论。
要实施前后端分离,以下四点是必须要考虑的。
(1) 第一点,SEO的考虑。
如果是 PC 端的站点,需要考虑是否需要强支持 SEO ,前后端分离的架构,很可能对搜索引擎的 spider 不友好,可能影响站点的收录。
当然,如果是原生 APP ,后端 node.js 只返回 json 数据,或者单页应用 SPA (对百度来说就是一个页面),则不太需要考虑这方面的问题。
(2) 第二点,产品特性的考虑。
很多产品追求酷炫的前端效果,并且对前端兼容性要求很高,前端产品改版频率很高,那么前后端分离是有必要的。
否则,前后端分离只会带来更多系统架构的复杂性。
第三点,公司发展阶段考虑。
公司发展的初级阶段,人比较少,对产品迭代速度的要求较高,此时更多的需要一些全栈的工程师,一个人开发从前到后全搞定。如果此时实施前后端分离,将引入“联调”一说,并且增加了沟通成本比,可能导致产品迭代的速度降低。
第四点、人员技能考虑。传统 FE 与后端 Java/PHP 工程师的合作方式, FE 工程师不需要有很深的后端功底,一旦引入前后端分离, node.js 层的前端同学需要了解更多的后端知识体系,不排除有 FE 同学对后端技能的排斥,引发人员的不稳定。
总之,前后端分离不只是一个分层架构的技术决策,和SEO、产品特性、公司发展阶段、人员知识体系相关,千万不可一概而论。
任何脱离业务的架构设计,都是耍流氓。
希望大家有收获。
【本文为51CTO专栏作者“58沈剑”原创稿件,转载请联系原作者】