为啥要弄懂 Event Loop
- 是要增加自己技术的深度,也就是懂得 JavaScript 的运行机制。
- 现在在前端领域各种技术层出不穷,掌握底层原理,可以让自己以不变,应万变。
- 应对各大互联网公司的面试,懂其原理,题目任其发挥。
堆,栈、队列
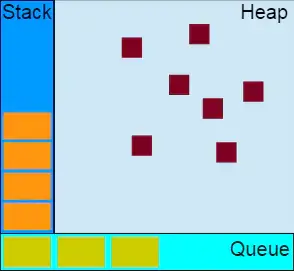
堆(Heap)
堆是一种数据结构,是利用完全二叉树维护的一组数据,堆分为两种,一种为最大堆,一种为最小堆,将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。堆是线性数据结构,相当于一维数组,有唯一后继。
如最大堆
栈(Stack)
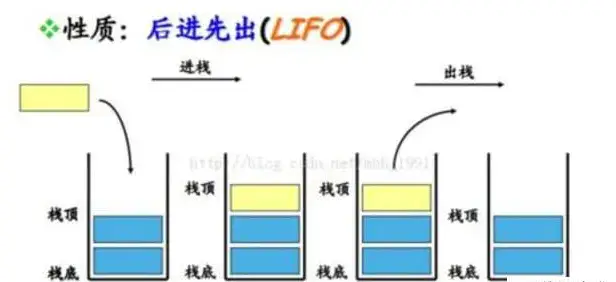
栈在计算机科学中是限定仅在表尾进行插入或删除操作的线性表。栈是一种数据结构,它按照后进先出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据。
栈是只能在某一端插入和删除的特殊线性表。
队列(Queue)
特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,和栈一样,队列是一种操作受限制的线性表。
进行插入操作的端称为队尾,进行删除操作的端称为队头。队列中没有元素时,称为空队列。
队列的数据元素又称为队列元素。在队列中插入一个队列元素称为入队,从队列中删除一个队列元素称为出队。因为队列只允许在一端插入,在另一端删除,所以只有最早进入队列的元素才能最先从队列中删除,故队列又称为先进先出(FIFO—first in first out)
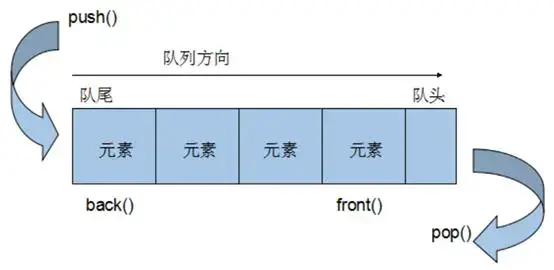
Event Loop
在 JavaScript 中,任务被分为两种,一种宏任务(MacroTask)也叫 Task,一种叫微任务(MicroTask)。
MacroTask(宏任务)
script 全部代码、setTimeout、setInterval、setImmediate(浏览器暂时不支持,只有 IE10 支持,具体可见 MDN)、I/O、UI Rendering。
MicroTask(微任务)
Process.nextTick(Node 独有)、Promise、Object.observe(废弃)、MutationObserver(具体使用方式查看这里[1])
浏览器中的 Event Loop[2]
Javascript 有一个 main thread 主线程和 call-stack 调用栈(执行栈),所有的任务都会被放到调用栈等待主线程执行。
JS 调用栈
JS 调用栈采用的是后进先出的规则,当函数执行的时候,会被添加到栈的顶部,当执行栈执行完成后,就会从栈顶移出,直到栈内被清空。
同步任务和异步任务
Javascript 单线程任务被分为同步任务和异步任务,同步任务会在调用栈中按照顺序等待主线程依次执行,异步任务会在异步任务有了结果后,将注册的回调函数放入任务队列中等待主线程空闲的时候(调用栈被清空),被读取到栈内等待主线程的执行。
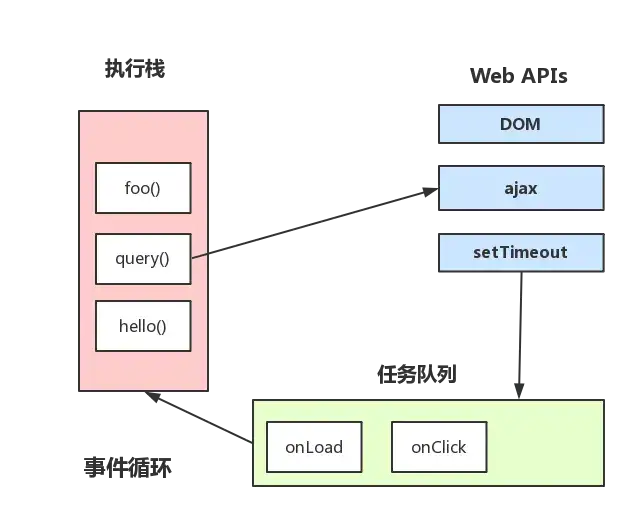
任务队列 Task Queue,即队列,是一种先进先出的一种数据结构。
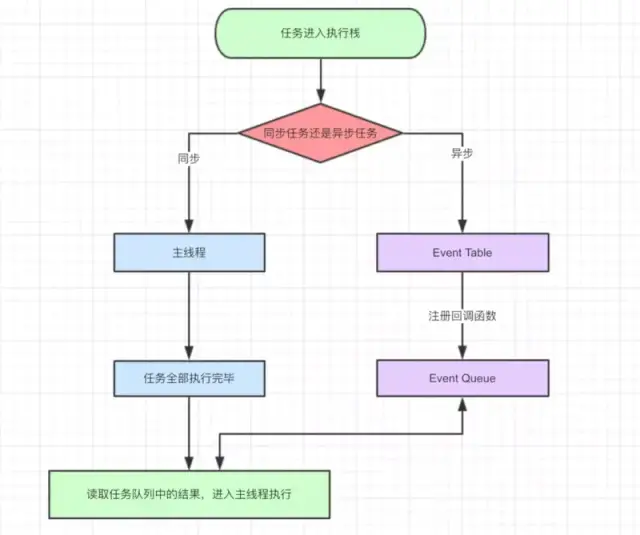
事件循环的进程模型[3]
- 选择当前要执行的任务队列,选择任务队列中最先进入的任务,如果任务队列为空即 null,则执行跳转到微任务(MicroTask)的执行步骤。
- 将事件循环中的任务设置为已选择任务。
- 执行任务。
- 将事件循环中当前运行任务设置为 null。
- 将已经运行完成的任务从任务队列中删除。
- microtasks 步骤:进入 microtask 检查点。
- 更新界面渲染。
- 返回第一步。
执行进入 microtask 检查点时,用户代理会执行以下步骤:
- 设置 microtask 检查点标志为 true。
- 当事件循环 microtask 执行不为空时:选择一个最先进入的 microtask 队列的 microtask,将事件循环的 microtask 设置为已选择的 microtask,运行 microtask,将已经执行完成的 microtask 为 null,移出 microtask 中的 microtask。
- 清理 IndexDB 事务
- 设置进入 microtask 检查点的标志为 false。
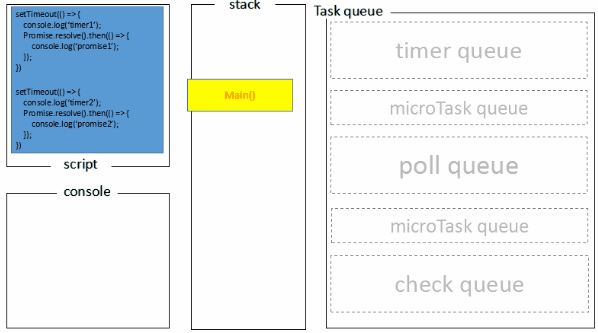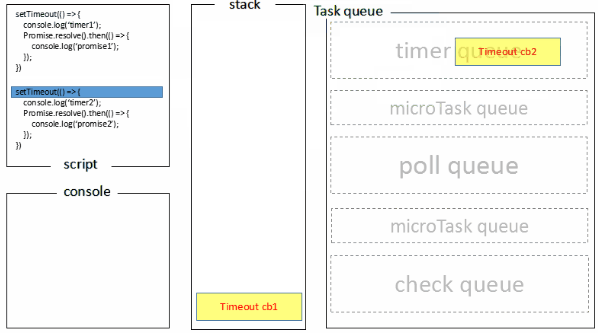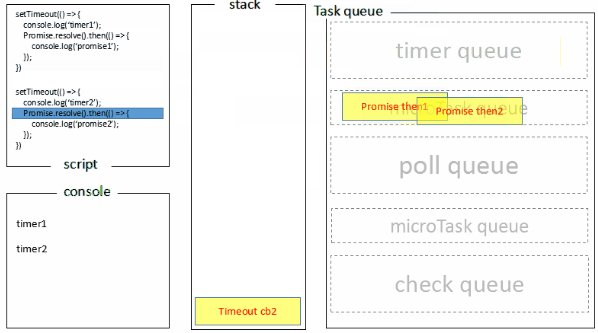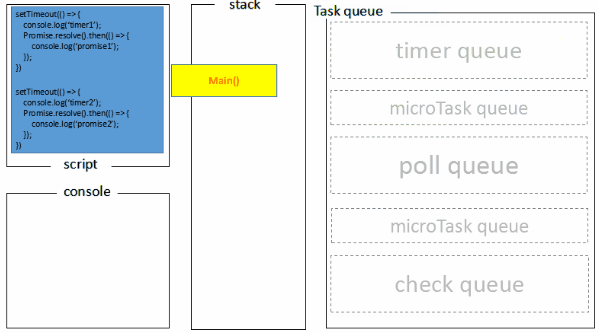
上述可能不太好理解,下图是我做的一张图片。
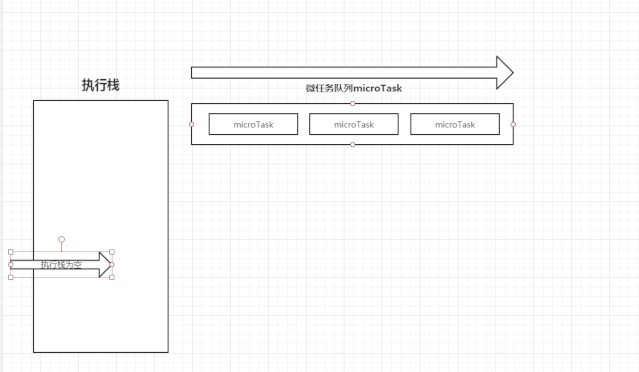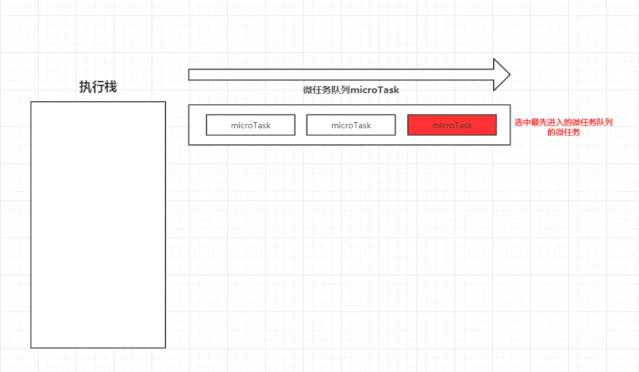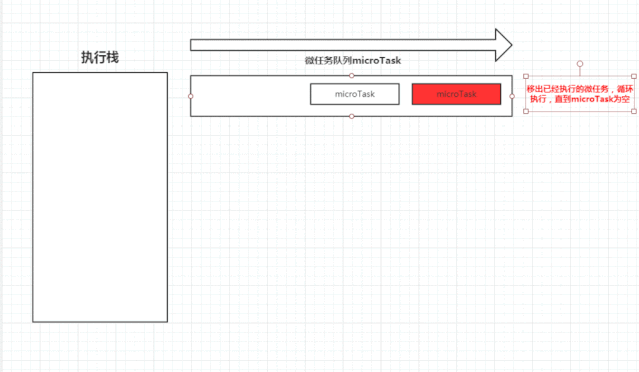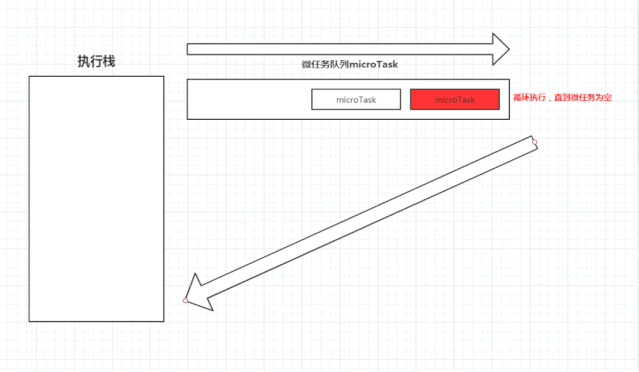
执行栈在执行完同步任务后,查看执行栈是否为空,如果执行栈为空,就会去检查微任务(microTask) 队列是否为空,如果为空的话,就执行 Task(宏任务),否则就一次性执行完所有微任务。
每次单个宏任务执行完毕后,检查微任务(microTask)队列是否为空,如果不为空的话,会按照先入先出的规则全部执行完微任务(microTask)后,设置微任务(microTask)队列为 null,然后再执行宏任务,如此循环。
举个例子
console.log('script start');
setTimeout(function() {
console.log('setTimeout');
}, 0);
Promise.resolve().then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
});
console.log('script end');
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
首先我们划分几个分类:
第一次执行:
Tasks:run script、 setTimeout callback
Microtasks:Promise then
JS stack: script
Log: script start、script end。
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
执行同步代码,将宏任务(Tasks)和微任务(Microtasks)划分到各自队列中。
第二次执行:
Tasks:run script、 setTimeout callback
Microtasks:Promise2 then
JS stack: Promise2 callback
Log: script start、script end、promise1、promise2
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
执行宏任务后,检测到微任务(Microtasks)队列中不为空,执行 Promise1,执行完成 Promise1 后,调用 Promise2.then,放入微任务(Microtasks)队列中,再执行 Promise2.then。
第三次执行:
Tasks:setTimeout callback
Microtasks:
JS stack: setTimeout callback
Log: script start、script end、promise1、promise2、setTimeout
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
当微任务(Microtasks)队列中为空时,执行宏任务(Tasks),执行 setTimeout callback,打印日志。
第四次执行:
Tasks:setTimeout callback
Microtasks:
JS stack:
Log: script start、script end、promise1、promise2、setTimeout
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
清空 Tasks 队列和 JS stack。
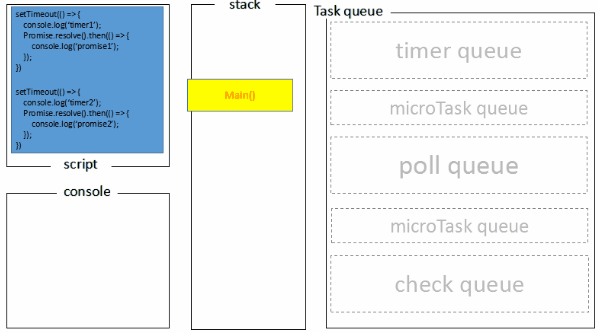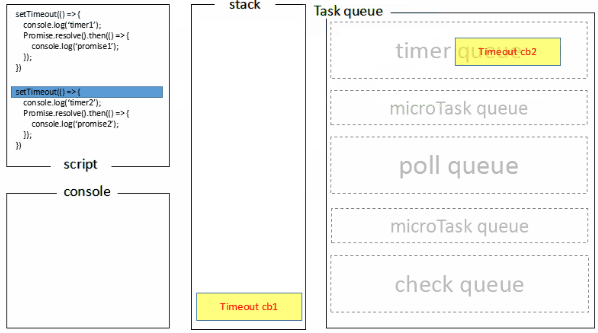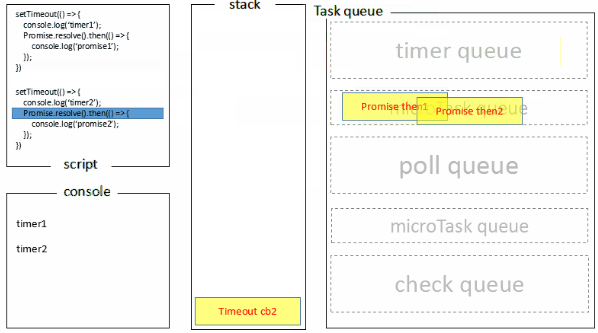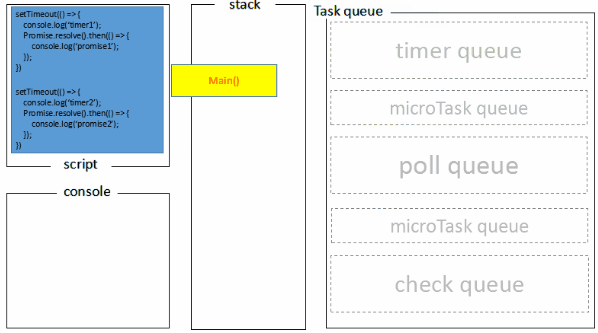
以上执行帧动画可以查看 Tasks, microtasks, queues and schedules[4]
或许这张图也更好理解些。
再举个例子
console.log('script start')
async function async1() {
await async2()
console.log('async1 end')
}
async function async2() {
console.log('async2 end')
}
async1()
setTimeout(function() {
console.log('setTimeout')
}, 0)
new Promise(resolve => {
console.log('Promise')
resolve()
})
.then(function() {
console.log('promise1')
})
.then(function() {
console.log('promise2')
})
console.log('script end')
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
这里需要先理解 async/await。
async/await 在底层转换成了 promise 和 then 回调函数。也就是说,这是 promise 的语法糖。每次我们使用 await, 解释器都创建一个 promise 对象,然后把剩下的async函数中的操作放到 then 回调函数中。async/await 的实现,离不开 Promise。从字面意思来理解,async 是“异步”的简写,而 await 是 async wait 的简写可以认为是等待异步方法执行完成。
关于 73 以下版本和 73 版本的区别
在老版本版本以下,先执行 promise1 和 promise2,再执行 async1。在 73 版本,先执行 async1 再执行promise1和 promise2。主要原因是因为在谷歌(金丝雀)73 版本中更改了规范,如下图所示:
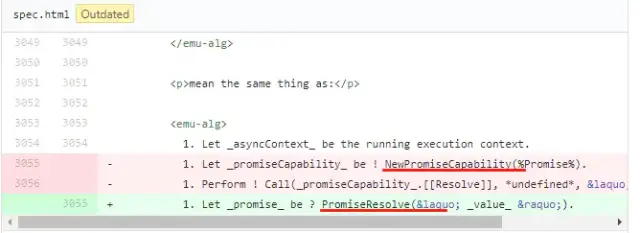
区别在于 RESOLVE(thenable)和之间的区别 Promise.resolve(thenable)。
在老版本中
- 首先,传递给 await 的值被包裹在一个 Promise 中。然后,处理程序附加到这个包装的 Promise,以便在 Promise 变为 fulfilled 后恢复该函数,并且暂停执行异步函数,一旦 promise 变为 fulfilled,恢复异步函数的执行。
- 每个 await 引擎必须创建两个额外的 Promise(即使右侧已经是一个 Promise)并且它需要至少三个 microtask 队列 ticks(tick 为系统的相对时间单位,也被称为系统的时基,来源于定时器的周期性中断(输出脉冲),一次中断表示一个 tick,也被称做一个“时钟滴答”、时标。)。
引用贺老师知乎上的一个例子
async function f() {
await p
console.log('ok')
}
- 1.
- 2.
- 3.
- 4.
简化理解为:
function f() {
return RESOLVE(p).then(() => {
console.log('ok')
})
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 如果 RESOLVE(p) 对于 p 为 promise 直接返回 p 的话,那么 p 的 then 方法就会被马上调用,其回调就立即进入 job 队列。
- 而如果 RESOLVE(p) 严格按照标准,应该是产生一个新的 promise,尽管该 promise 确定会 resolve 为 p,但这个过程本身是异步的,也就是现在进入 job 队列的是新 promise 的 resolve 过程,所以该 promise 的 then 不会被立即调用,而要等到当前 job 队列执行到前述 resolve 过程才会被调用,然后其回调(也就是继续 await 之后的语句)才加入 job 队列,所以时序上就晚了。
谷歌(金丝雀)73 版本中
- 使用对 PromiseResolve 的调用来更改 await 的语义,以减少在公共 awaitPromise 情况下的转换次数。
- 如果传递给 await 的值已经是一个 Promise,那么这种优化避免了再次创建 Promise 包装器,在这种情况下,我们从最少三个 microtick 到只有一个 microtick。
详细过程:
73 以下版本
首先,打印 script start,调用 async1()时,返回一个 Promise,所以打印出来 async2 end。每个 await,会新产生一个 promise,但这个过程本身是异步的,所以该 await 后面不会立即调用。继续执行同步代码,打印 Promise 和 script end,将 then 函数放入微任务队列中等待执行。同步执行完成之后,检查微任务队列是否为 null,然后按照先入先出规则,依次执行。然后先执行打印 promise1,此时 then 的回调函数返回 undefinde,此时又有 then 的链式调用,又放入微任务队列中,再次打印 promise2。再回到 await 的位置执行返回的 Promise 的 resolve 函数,这又会把 resolve 丢到微任务队列中,打印 async1 end。当微任务队列为空时,执行宏任务,打印 setTimeout。
谷歌(金丝雀 73 版本)
如果传递给 await 的值已经是一个 Promise,那么这种优化避免了再次创建 Promise 包装器,在这种情况下,我们从最少三个 microtick 到只有一个 microtick。引擎不再需要为 await 创造 throwaway Promise - 在绝大部分时间。现在 promise 指向了同一个 Promise,所以这个步骤什么也不需要做。然后引擎继续像以前一样,创建 throwaway Promise,安排 PromiseReactionJob 在 microtask 队列的下一个 tick 上恢复异步函数,暂停执行该函数,然后返回给调用者。具体详情查看(这里[5])。
NodeJS 的 Event Loop[6]
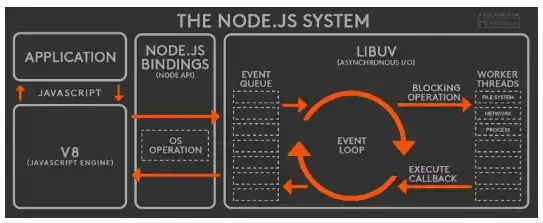
Node 中的 Event Loop 是基于 libuv 实现的,而 libuv 是 Node 的新跨平台抽象层,libuv 使用异步,事件驱动的编程方式,核心是提供 i/o 的事件循环和异步回调。libuv 的 API 包含有时间,非阻塞的网络,异步文件操作,子进程等等。Event Loop 就是在 libuv 中实现的。
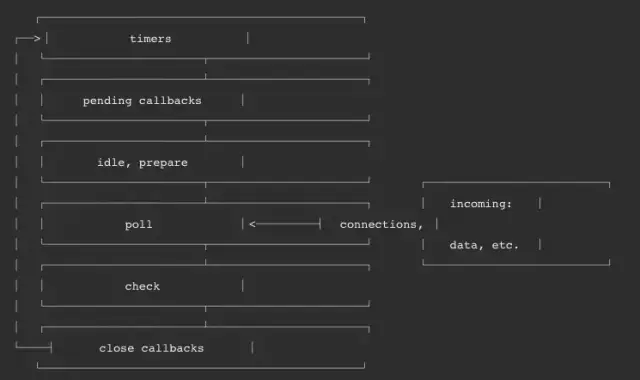
Node[7] 的 Event loop 一共分为 6 个阶段,每个细节具体如下:
- timers: 执行 setTimeout 和 setInterval 中到期的 callback。
- pending callback: 上一轮循环中少数的 callback 会放在这一阶段执行。
- idle, prepare: 仅在内部使用。
- poll: 最重要的阶段,执行 pending callback,在适当的情况下回阻塞在这个阶段。
- check: 执行 setImmediate(setImmediate()是将事件插入到事件队列尾部,主线程和事件队列的函数执行完成之后立即执行 setImmediate 指定的回调函数)的 callback。
- close callbacks: 执行 close 事件的 callback,例如 socket.on('close'[,fn])或者 http.server.on('close, fn)。具体细节如下:
timers
执行 setTimeout 和 setInterval 中到期的 callback,执行这两者回调需要设置一个毫秒数,理论上来说,应该是时间一到就立即执行 callback 回调,但是由于 system 的调度可能会延时,达不到预期时间。以下是官网文档[8]解释的例子:
const fs = require('fs');
function someAsyncOperation(callback) {
// Assume this takes 95ms to complete
fs.readFile('/path/to/file', callback);
}
const timeoutScheduled = Date.now();
setTimeout(() => {
const delay = Date.now() - timeoutScheduled;
console.log(`${delay}ms have passed since I was scheduled`);
}, 100);
// do someAsyncOperation which takes 95 ms to complete
someAsyncOperation(() => {
const startCallback = Date.now();
// do something that will take 10ms...
while (Date.now() - startCallback < 10) {
// do nothing
}
});
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
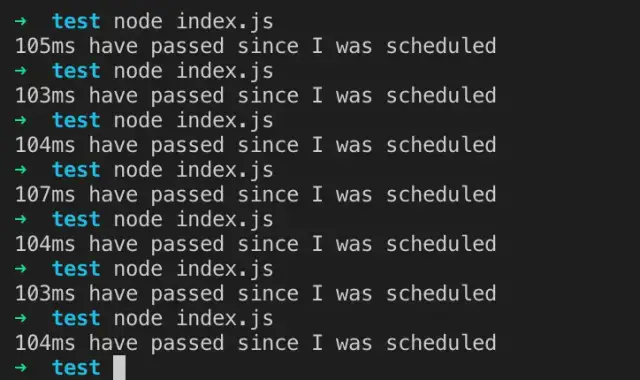
当进入事件循环时,它有一个空队列(fs.readFile()尚未完成),因此定时器将等待剩余毫秒数,当到达 95ms 时,fs.readFile()完成读取文件并且其完成需要 10 毫秒的回调被添加到轮询队列并执行。当回调结束时,队列中不再有回调,因此事件循环将看到已达到最快定时器的阈值,然后回到 timers 阶段以执行定时器的回调。
在此示例中,您将看到正在调度的计时器与正在执行的回调之间的总延迟将为 105 毫秒。
以下是我测试时间:
pending callbacks
此阶段执行某些系统操作(例如 TCP 错误类型)的回调。例如,如果 TCP socket ECONNREFUSED 在尝试 connect 时 receives,则某些* nix 系统希望等待报告错误。这将在 pending callbacks 阶段执行。
poll
该 poll 阶段有两个主要功能:
- 执行 I/O 回调。
- 处理轮询队列中的事件。
当事件循环进入 poll 阶段并且在 timers 中没有可以执行定时器时,将发生以下两种情况之一
- 如果 poll 队列不为空,则事件循环将遍历其同步执行它们的 callback 队列,直到队列为空,或者达到 system-dependent(系统相关限制)。
- 如果 poll 队列为空,则会发生以下两种情况之一
- 如果有 setImmediate()回调需要执行,则会立即停止执行 poll 阶段并进入执行 check 阶段以执行回调。
- 如果没有 setImmediate()回到需要执行,poll 阶段将等待 callback 被添加到队列中,然后立即执行。
当然设定了 timer 的话且 poll 队列为空,则会判断是否有 timer 超时,如果有的话会回到 timer 阶段执行回调。
check
此阶段允许人员在 poll 阶段完成后立即执行回调。如果 poll 阶段闲置并且 script 已排队 setImmediate(),则事件循环到达 check 阶段执行而不是继续等待。
setImmediate()实际上是一个特殊的计时器,它在事件循环的一个单独阶段运行。它使用 libuv API 来调度在 poll 阶段完成后执行的回调。
通常,当代码被执行时,事件循环最终将达到poll阶段,它将等待传入连接,请求等。但是,如果已经调度了回调 setImmediate(),并且轮询阶段变为空闲,则它将结束并且到达check阶段,而不是等待 poll 事件。
console.log('start')
setTimeout(() => {
console.log('timer1')
Promise.resolve().then(function() {
console.log('promise1')
})
}, 0)
setTimeout(() => {
console.log('timer2')
Promise.resolve().then(function() {
console.log('promise2')
})
}, 0)
Promise.resolve().then(function() {
console.log('promise3')
})
console.log('end')
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
如果 node 版本为 v11.x, 其结果与浏览器一致。
start
end
promise3
timer1
promise1
timer2
promise2
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
具体详情可以查看《又被 node 的 eventloop 坑了,这次是 node 的锅》[9]。
如果 v10 版本上述结果存在两种情况:
- 如果 time2 定时器已经在执行队列中了
start
end
promise3
timer1
timer2
promise1
promise2
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 如果 time2 定时器没有在执行对列中,执行结果为
start
end
promise3
timer1
promise1
timer2
promise2
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
具体情况可以参考 poll 阶段的两种情况。
从下图可能更好理解:
setImmediate() 的 setTimeout()的区别
setImmediate 和 setTimeout()是相似的,但根据它们被调用的时间以不同的方式表现。
- setImmediate()设计用于在当前 poll 阶段完成后check阶段执行脚本 。
- setTimeout() 安排在经过最小(ms)后运行的脚本,在 timers 阶段执行。举个例子
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
执行定时器的顺序将根据调用它们的上下文而有所不同。如果从主模块中调用两者,那么时间将受到进程性能的限制。
其结果也不一致
如果在 I / O 周期内移动两个调用,则始终首先执行立即回调:
const fs = require('fs');
fs.readFile(\_\_filename, () => {
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});
});
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
其结果可以确定一定是 immediate => timeout。主要原因是在 I/O 阶段读取文件后,事件循环会先进入 poll 阶段,发现有 setImmediate 需要执行,会立即进入 check 阶段执行 setImmediate 的回调。
然后再进入 timers 阶段,执行 setTimeout,打印 timeout。
┌───────────────────────────┐
┌─>│ timers │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ pending callbacks │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ idle, prepare │
│ └─────────────┬─────────────┘ ┌───────────────┐
│ ┌─────────────┴─────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └─────────────┬─────────────┘ │ data, etc. │
│ ┌─────────────┴─────────────┐ └───────────────┘
│ │ check │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
└──┤ close callbacks │
└───────────────────────────┘
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
Process.nextTick()
process.nextTick()虽然它是异步 API 的一部分,但未在图中显示。这是因为 process.nextTick()从技术上讲,它不是事件循环的一部分。
process.nextTick()方法将 callback 添加到 next tick 队列。一旦当前事件轮询队列的任务全部完成,在 next tick 队列中的所有 callbacks 会被依次调用。换种理解方式:
当每个阶段完成后,如果存在nextTick队列,就会清空队列中的所有回调函数,并且优先于其他 microtask 执行。例子
let bar;
setTimeout(() => {
console.log('setTimeout');
}, 0)
setImmediate(() => {
console.log('setImmediate');
})
function someAsyncApiCall(callback) {
process.nextTick(callback);
}
someAsyncApiCall(() => {
console.log('bar', bar); // 1
});
bar = 1;
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
在 NodeV10 中上述代码执行可能有两种答案,一种为:
bar 1
setTimeout
setImmediate
- 1.
- 2.
- 3.
另一种为:
bar 1
setImmediate
setTimeout
- 1.
- 2.
- 3.
最后
感谢@Dante_Hu 提出这个问题 await 的问题,文章已经修正。修改了 node 端执行结果。V10 和 V11 的区别。
参考资料
MutationObserver: https://javascript.ruanyifeng.com/dom/mutationobserver.html
[2]jS事件循环机制: https://segmentfault.com/a/1190000015559210
[3]事件循环的进程模型: https://segmentfault.com/a/1190000010622146
[4]Tasks, microtasks, queues and schedules: https://jakearchibald.com/2015/tasks-microtasks-queues-and-schedules/
[5]Promise : https://v8.js.cn/blog/fast-async/
[6]浏览器与Node的事件循环(Event Loop)有何区别?: https://juejin.im/post/6844903761949753352
[7]不要混淆nodejs和浏览器中的event loop: https://cnodejs.org/topic/5a9108d78d6e16e56bb80882
[8]The Node.js Event Loop, Timers, and process.nextTick(): https://nodejs.org/en/docs/guides/event-loop-timers-and-nexttick/
[9]《又被 node 的 eventloop 坑了,这次是 node 的锅》: https://juejin.im/post/6844903761979113479