本文主要分享一些组织管理机器学习项目的实践经验。
Python
Python 是机器学习项目开发的主要使用语言之一。它包含了大量的库/包可以用于机器学习:
- numpy:适用于多维数组、数值计算。常用于数据处理。
- pandas:数据分析常用库。pandas dataframes本质上是numpy数组,它用描述性字符串作为行和列标签。数据在pandas dataframes里可以很容易进行排序、过滤、分组、连接等操作,这对数据处理很有用。
- PyTorch:用于构建神经网络。包括许多预训练模型和计算机视觉数据集。Pytorch鼓励使用面向对象的编程,用Pytorch编写代码很快,而且Pytorch默认支持快速执行,因此可以与Python调试器一起使用。
- TensorFlow:在工业上更受欢迎的Pytorch的替代品。Pytorch更适合做研究。如果您想使用TensorFlow,并且想要一个更高级别的接口,那么可以使用Keras。
- scikit-learn:这是一个很好的库,用于回归、支持向量机、k近邻、随机森林、计算混淆矩阵等。
- matplotlib、seaborn:用于数据可视化的常用库之一。
Git
Git版本控制对于机器学习项目的组织管理非常有用。
Git是一种可以用来跟踪对代码所做的所有更改的工具。Git"repository"是一个包含代码文件的目录。Git使用节省存储空间的技术,因此它不存储代码的多个副本,而是存储旧文件和新文件之间的相对更改。Git有助于保持代码文件目录的整洁和组织,因为只有最新版本才显示存在(尽管您可以随时轻松访问代码的任何版本)。使用者可以选择发生的更改,使用"commit"将代码的特定更改与相关的书面描述捆绑在一起。Git存储库也使共享代码和协作变得更加容易。总的来说,比起保存"myscriptv1.py"、"dataprocessingv56.py"、"utils_73.py"等上百万个不同版本的代码,Git是一个更好的方法来保存旧代码。
Git版本控制可以通过GitHub、GitLab和Bitbucket来实现。我最常使用GitHub。

使用GitHub的方法如下:
- 安装Git
- 注册一个GitHub账户
- 通过SSH链接个人GitHub账户和个人电脑。以便于随时能够将代码上传并保存在云端。
- 单击概要文件的"Repositories"部分中的绿色"new"按钮,在GitHub上创建一个新的存储库。
- 使个人计算机能够将代码推送到该存储库(以下是示例命令):
- echo "# pytorch-computer-vision" >> README.md
- git init git add README.md
- git commit -m "first commit"
- git branch -M master git remote add origin https://github.com/rachellea/pytorch-computer-vision.git
- git push -u origin master
假设现在myeditedscript.py有代码做出了更改,可以通过commit进行版本管理:
- git add myeditedscript.py
- git commit -m 'added super useful functionality'
- git push origin master
Anaconda
Anaconda支持创建不同的环境,这些环境可能包含不同的Python版本和不同的包版本。当我们在处理多个具有冲突依赖关系的项目时,Anaconda特别有用。
使用Anaconda很简单:
首先,安装Anaconda
然后,创建环境。用所在的项目来命名环境是比较好的。例如,如果该项目是关于使用神经网络进行胸部x光分类的,则该环境可以称为chestxraynn:
- conda create --name chestxraynn python=3.5
请注意,避免在环境名称周围加引号,否则引号字符本身将是环境名称的一部分。此外,可以选择任何版本的Python。它不一定是python3.5。
一旦环境被创建,就是激活环境的时候了。"激活"仅仅意味着你将被"放入环境中",这样你就可以使用安装在里面的所有软件。Windows激活命令如下:
- activate chestxraynn
Linux/macOS激活命令如下:
- source activate chestxraynn
使用"conda install"命令在环境中安装包。以安装matplotlib为例:
- conda install -c conda-forge matplotlib
从技术上讲,在conda环境中,也可以使用pip安装包,但这可能会导致问题,因此应尽量避免。
Anaconda将负责确保环境中所有内容的版本都是兼容的。更多命令见Conda Cheat Sheet。
也可以直接使用别人的命令文件创建conda环境。在GitHub中github/rachellea/pytorch-computer-vision, 有一个tutorial_environment.yml文件,此文件指定运行教程代码所需的依赖项。要基于此文件创建conda环境,只需在Anaconda提示符中运行以下命令:
- conda env create -f tutorial_environment.yml
代码管理:类和函数
代码管理非常重要。当数千行的代码,没有文件说明,中间到处都是重复的代码块,一些代码块没有解释就注释掉了,还有各种奇怪的变量名,这简直就是一场灾难。
而Pytorch实现中通常看到的所有代码都是有组织的,并且有很好的说明记录。
从长远来看,如果为自己的项目编写高质量的代码,将节省大量时间。高质量代码的一个方面是它在模块中的组织和管理。
代码管理建议:
- 面向对象编程。强烈推荐使用PyTorch机器学习框架,因为它有助于为所有事情使用面向对象的编程。Pytorch中,模型是一个类,数据集也是一个类。
- 使用函数。如果你写的东西不能作为一个类很好地工作,那么把代码组织成函数。函数是可重用的。
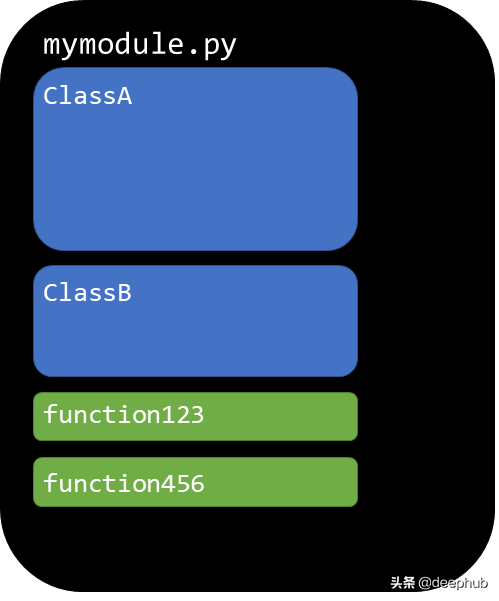
代码管理示意图
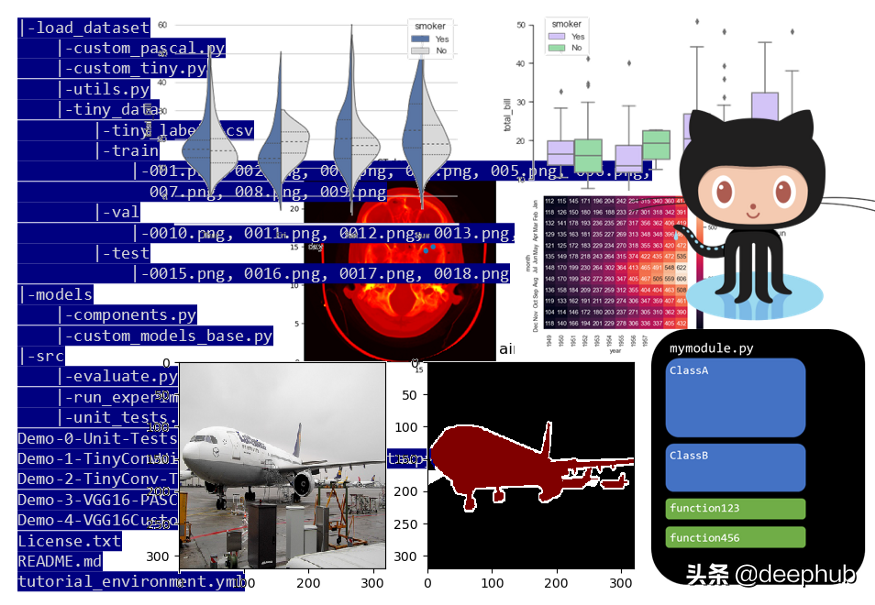
代码管理:目录
使用多个模块来组织代码,并将这些模块组织到目录中。以一个简单的为例:
总体组织如下:
- 一个训练-评估-测试循环模块(src/run_experiment.py)
- 一个用于计算性能指标的模块(src/evaluate.py)
- 一个(或多个)用于数据处理的模块(loaddataset/custom-pascal.py、 loaddatasetcustomtiny.py)
- 一个(或多个)模型模块(models/custommodelsbase.py)

代码管理目录图
请注意,虽然在这个存储库中存储了一个数据集(在"train"、"val"和"test"目录中的png图片),但一般来说,将数据集放入存储库并不是一个好主意。此存储库中存在数据集的唯一原因是,它是为演示目的而创建的小型数据集。除非数据非常小,否则不应将其放入存储库中。
导入文件
请注意,需要在每个子目录中都有一个名为init.py的空文件,以便模块可以从这些目录导入文件。
下面是如何根据彼此所在的目录让一个模块awesomecode.py调用名为helpercode.py的模块:

说明文档
写说明文档是很好的。记录所有函数、方法和类,有时在编写函数之前对其进行文档记录。如果文档有时比代码长也可以,"过于清晰"比不够清晰要好。
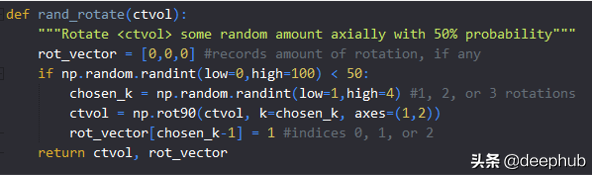
上面的图像是一个简单的函数rand_rotate(),它随机旋转表示CT体积的3D numpy数组。这些注释很有帮助,因为它们解释了为什么旋转的向量使用(k-1)——这是因为所选的k是1、2或3,而Python是零索引的。像这样简单的说明可以防止以后的混乱。
data processing tutorial code中的说明注释
文档将确保回顾旧代码时,可以快速回忆代码和函数的作用。文档可以防止使用者在看到一些看起来很奇怪的东西时意外地破坏自己的代码,并且有更改它的本能。文档也将使其他人能够理解和使用您的代码。
变量命名
始终使用描述性变量名。"volumetricattngr_truth"是一个比"truth"更好的变量名。
即使在行和列上迭代,也要使用"row"和"col"作为变量名,而不是"i"和"j"。有一次我花了一整天的时间寻找一个非常奇怪的bug,结果发现它是由于错误地迭代2D数组而导致的,因为我在数百行代码中只切换了一行"I"和"j"。那是我最后一次使用单字母变量名。
模块测试
很多人声称他们没有时间为他们的代码编写测试,因为这只是为了研究。我认为测试研究代码更重要,因为研究的全部意义在于你不知道"正确答案"是什么,如果你不知道生成答案的代码是否正确那么如何确保答案是正确的呢?
每次我花一天时间为我的代码编写单元测试时,我都会发现一些错误——有些无关紧要,有些则相当重要。如果你编写单元测试,将发现代码中的错误。如果你为别人的代码编写单元测试,你也会在他们的代码中发现错误。
除了促进代码的正确性,单元测试还可以通过阻止编写一次做太多事情的"上帝函数"来帮助实施良好的代码组织管理。上帝函数通常是测试的噩梦,我们应该将其分解成更小、更易于管理的函数。
至少,最好对代码中最关键的部分进行单元测试,例如复杂的数据处理或模型中奇怪的张量排列。确保代码是正确的决不是浪费时间。
这些单元测试包括对一些内置PyTorch函数的测试,以便进行演示。
可视化纠错
特别是在计算机视觉中,使用可视化来执行健全性检查是很有用的。
matplotlib非常适合查看图像、分割图、带边框的图像等。下面是一个通过将matplotlib的imshow()函数应用于输入图像而产生的可视化效果的示例:
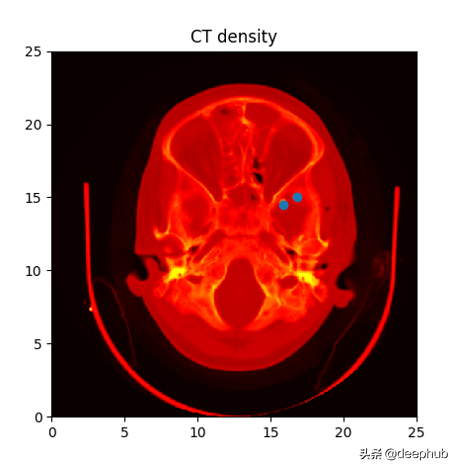
matplotlib可视化
seaborn是为统计数据可视化而设计的。它对于制作热力图和生成性能指标的复杂可视化非常有用。下面是一些在seaborn中可以用大约一行代码绘制的绘图示例:
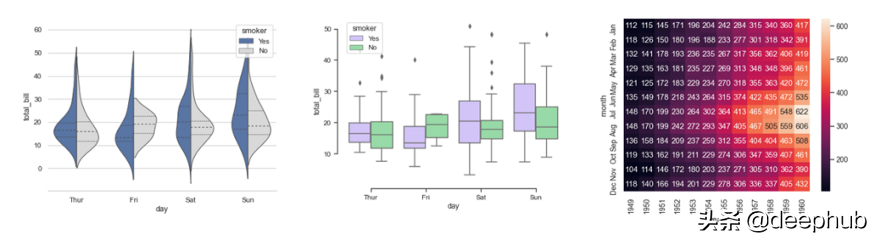
seaborn可视化
matplotlib和seaborn都可以用来创建可视化效果,即时显示输入数据是否合理、基本真实情况是否合理、数据处理是否没有意外出错、模型的输出是否有意义等。
单元测试和可视化
Demo-0-Unit-Tests-and-Visualization.py 首先运行 src/unit_tests.py中的单元测,然后对PASCAL VOC 2012数据集图像分割进行可视化。
为了运行演示的可视化部分,请更改demo-0-Unit-Tests-and-visualization.py到计算机上的一个文件夹内,在其中存储PASCAL VOC 2012数据集。一旦数据集下载完成,你就可以运行可视化程序。实现可视化的代码位于loaddataset/custompascal.py中. 目前,在演示文件中,"imagestovisualize"的总数设置为3;如果希望可视化更多图像,可以进一步增加该数量,例如增加到100。
可视化结果如下:
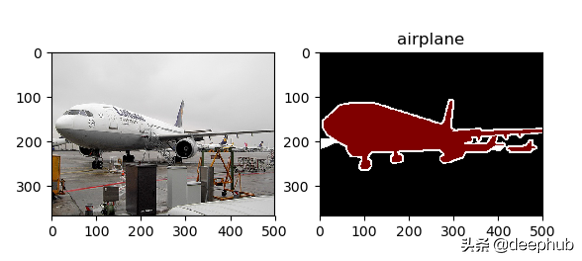
PASCAL VOC 2012数据集中的飞机图像
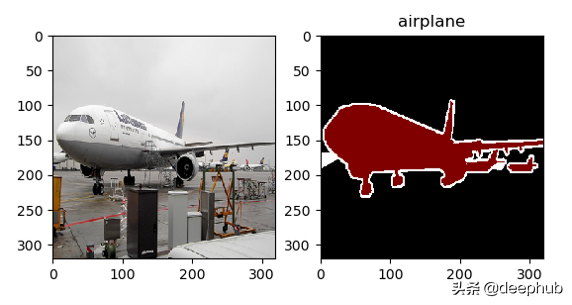
resample处理后的飞机图像
从可视化结果中我们可以推断出一些有用的东西:
- 输入图像与图像分割之间的映射是正确的。
- 用于定义像素级分割的整数与标签描述字符串之间的映射是正确的。比如:1正确地映射为"飞机"。
- 重采样步骤并没有"破坏"输入图像或分割图像。
在终端进行可视化
如果处于"非交互式环境"(即没有图形用户界面的终端),则需要关闭交互式显示并保存图形,以便在其他地方打开:
- import seaborn
- import matplotlib
- matplotlib.use('agg')
- import matplotlib.pyplot as plt
- plt.ioff() #seaborn figure: heatmap = seaborn.heatmap(some_dataframe, cmap = 'Blues', square=True, center=0)
- heatmap.get_figure().savefig('Descriptive_Figure_Name.png',bbox_inches='tight')
- plt.close()
- #matplotlib figure: plt.imshow(chest_x_ray,cmap='gray')
- plt.savefig('Other_Descriptive_Figure_Name.png')
- plt.close()
Python 调试器
Python调试器是一个非常有用的工具,因为它允许在程序崩溃的地方检查变量或对象的状态,并在程序崩溃的地方运行代码片段,以便可以尝试可能的解决方案。使用Python调试器比使用print语句调试效率更高,它将为节省数小时的时间。Python调试器也可以与PyTorch一起使用,检查张量、梯度、记录dataframes等。
要使用Python调试器在终端中以交互方式运行脚本,请使用以下命令:
- python -m pdb myscript.py
输入上述命令后,将看到(Pdb)提示符出现。键入"c"继续。(这只是一个单独的小写字母c,表示continue)。
要退出Python调试器,请使用'q'(这是一个单独的小写字母q,表示quit)。有时候可能需要使用q两次才能完全退出。
如果要在程序中的某个特定点停止,则可以在相关模块中导入pdb,然后将"pdb.set_trace()"在你想要停止的特定点。或者,如果不想费心导入pdb,也可以在想停止的地方输入"assert False",这样可以保证程序在指定的地方结束(尽管这不是使用Python调试器的正式方式)。
不要使用Jupyter Notebooks
考虑到前面的所有部分,本文建议不要将jupyter notebooks用于机器学习项目,或者真正用于任何需要花费数天以上时间的编码项目。
为什么?
- jupyter notebooks 鼓励你把所有的东西都放在全局命名空间中,这样就产生了一个巨大的怪物模块,它可以做所有的事情,而且没有函数、类和任何结构。
- jupyter notebooks 使代码的重用变得更加困难。函数是可重用的;而单元格5、10和13中的代码是不可重用的。
- jupyter notebooks 使单元测试变得困难。函数和方法可以进行单元测试。单元格5、10和13中的代码不能进行单元测试。
1. 代码越有条理(也就是说,越细分为类和函数),jupyter notebooks 的交互性就越差,交互性是人们喜欢jupyter notebook的主要原因。jupyter notebooks 吸引人的交互特性与高度结构化、组织良好的代码本质上是对立的。
- jupyter notebooks 很难正确使用Git版本控制。jupyter notebooks只是大量的JSON文件,因此正确地合并它们或用它们执行提交请求基本上是不可能的。
- jupyter notebooks 使人们很难与他人合作。你必须"轮流"在jupyter notebooks上工作(而不是像使用"常规代码"那样从同一个rep中push/pull)。
- jupyter notebooks 有一个非线性的工作流程,这与可重复的研究完全相反。
那么jupyter notebooks有什么用?一些可能适用的场景是初始数据可视化、家庭作业、交互式演示。
代码编写标准
两个实用的代码编写标准是:
- 编写正确易懂的代码。如果你的代码是正确的,你的模型就更有可能产生好的结果,你的研究结论是正确的,你将创造出一些实际有用的东西。
- 确保任何人都可以复制你所做的一切——例如模型、结果、图形——通过在终端中运行一个命令(例如"python main.py"). 将有助于其他人在你的工作基础上再接再厉,也有助于"未来的你"在自己的工作基础上再接再厉。
总结
- Python是一种很好的机器学习语言
- Git版本控制有助于跟踪不同版本的代码。它可以通过GitHub获得。
- Anaconda是一个包管理器,它支持创建不同的环境,这些环境可能包含不同的Python版本和包。在处理具有冲突依赖关系的多个项目时,它非常有用。
- 将代码组织成模块中的类和函数。在Git存储库中以分层目录结构组织模块。
- 用注释和docstring记录代码
- 使用描述性变量名。不要使用单字母变量名。
- 编写单元测试,特别是对于数据处理和模型中最复杂或最关键的部分。
- 使用matplotlib和seaborn可视化显示数据集、模型输出和模型性能
- 使用Python调试器进行快速、高效的调试
- 不要将jupyter notebooks 用于机器学习项目
作者:Rachel Lea Ballantyne Draelos