












本文转载自公众号“读芯术”(ID:AI_Discovery)。
如果你对数据科学感兴趣,那么可能对这个工作流程很熟悉:通过运行Jupyter notebook开启一个项目,然后开始编写python代码、运行复杂的分析甚至训练模型。随着notebook文件的函数、类、图和日志的大小不断增长,你会发现自己面前堆积了巨大的一团代码块。运气好的话,一切都能顺利进行。那你真的很厉害!
但是,Jupyter notebook隐藏了一些严重的陷阱,可能会让代码变成噩梦。让我们看看这是如何发生的,然后讨论一下防止这种情况出现的最佳编码方法。
Jupyter Notebook的问题
通常,如果你想使Jupyter原型开发更上一层楼,事情结果可能会不符合你的预期。这是笔者在使用此工具时遇到的一些情况,你应该也很熟悉:
- 将所有对象(函数或类)定义并实例化后,可维护性就变得非常困难:即使想对函数做些小改动,也必须将其放在笔记本中的某个位置进行修复,然后重新运行重新编码。你一定不希望这种事情发生。将逻辑和处理功能分离在外部脚本中不是更简单吗?
- 由于其交互性和即时反馈,jupyternotebook促使数据科学家在全局名称空间中声明变量,而不是使用函数。这在python开发中是不好的做法,它限制了有效的代码重用。
由于笔记本电脑变成容纳所有变量的大型状态机,因此也会损害其可重复性。在这种配置下,必须记住要哪个结果被缓存,哪个结果没有被缓存,还必须期望其他用户遵循你的单元执行顺序。
- 笔记本在后台格式化的方式(JSON对象)使代码版本控制变得困难。这就是为什么笔者很少看到数据科学家使用GIT提交不同版本的笔记本,或合并分支以实现特定功能。
因此,团队协作变得低效笨拙:团队成员开始通过电子邮件或Slack交换代码段和笔记本,回滚到以前的代码版本成为一场噩梦,文件组织开始变得混乱。这是在没有正确版本控制的情况下, 使用Jupyter notebook两到三周后,我在项目中通常看到的内容:
- analysis.ipynb
- analysis_COPY(1).ipynb
- analysis_COPY(2).ipynb
- analysis_FINAL.ipynb
- analysis_FINAL_2.ipynb
Jupyter notebook非常适合探索和快速制作原型。它们肯定不是为可重用性或生产用途而设计的。如果你使用Jupyter notebook开发了数据处理管道,那么最好的情况是代码仅按照单元执行顺序以线性同步方式在笔记本电脑或VM上运行。
但这并没有说明你的代码在更复杂的环境中的行为方式,例如,较大的输入数据集,其他异步并行任务或分配较少的资源。实际上我们很难测试笔记本,因为它们的行为有时是不可预测的。
作为一个将大部分时间花在VSCode上的人,我常常利用功能强大的扩展来进行代码添加、样式格式化、代码结构、自动完成和代码库搜索,因此当切换回Jupyter时,笔者不禁感到有些无能为力。与VSCode相比,Jupyter notebook缺少强制执行最佳编程实践的扩展。
好了,抱怨到此为止。笔者真的很喜欢Jupyter,认为它对设计工作非常有用。你肯定可以用它来引导小项目或快速创建想法原型,但你必须遵循软件工程的原则。当数据科学家使用notebook时,有时会忽略这些原则,让我们一起回顾下其中一些吧。
让代码再次出色的小技巧
这些技巧是从不同的项目、笔者参加的聚会以及过去合作过的软件工程师和架构师的讨论中汇编而来的。注意,以下内容皆假设我们正在编写python脚本,而不是notebook。
1. 清理代码

代码质量最重要的维度是清晰,清晰易读的代码对于协作和可维护性至关重要。这样做可以帮你获得更简洁的代码:
使用有意义的描述性和暗示型变量名。例如,如果要声明一个关于属性(例如年龄)的布尔变量来检查一个人是否老了,那么可以使用is_old使其既具有描述性又具有类型信息性。声明数据的方式也是一样的:让它具有解释性。
- # not good ...
- import pandas as pd
- df = pd.read_csv(path)# better!transactions = pd.read_csv(path)
- 避免使用只有你能理解的缩写和没有人能忍受的长变量名。
- 不要直接在代码中编码“魔术数字”。在变量中定义它们,以便每个人都能理解它们所指的内容。
- # not good ...
- optimizer = SGD(0.0045, momentum=True)# better !
- learning_rate = 0.0045
- optimizer = SGD(learning_rate, momentum=True)
图源: prettier.io/
2. 使代码模块化
当你开始构建可以在相同或其他项目中重复使用的东西时,你必须将代码组织为逻辑功能和模块,这有助于构建更好的组织和可维护性。
例如,你正在研究NLP项目,并且你可能具有不同的处理功能来处理文本数据(标记,剥离URL,修饰词等)。你可以将所有这些单元放入名为text_processing.py的python模块中,然后从中导入它们,主程序将更轻巧。
这是有关编写模块化代码的一些技巧:
- 不要自我重复。尽可能泛化或合并你的代码。
- 函数应该用来做一件事。如果一个函数执行多项操作,则很难被概括。
- 在函数中抽象逻辑,但又不要过度设计,否则最终可能会有太多的模块。运用你的判断力,如果你没有经验,请查看scikit-learn等流行的GitHub存储库,并学习其编码风格。
3. 重构代码
重构旨在重新组织代码的内部结构,而不改变其功能,通常是在有效(但仍未完全组织)的代码版本上完成的。它有助于消除重复功能,重组文件结构,并添加更多抽象。
图源:unsplash
4. 提高代码效率
编写高效的代码以快速执行并消耗更少的内存和存储空间,是软件开发中的另一项重要技能。编写高效的代码需要多年的经验,但是以下一些小技巧可以帮助你确定代码是否运行缓慢以及如何提高代码运行速度:
- 在执行任何操作之前,请检查算法的复杂性以评估其执行时间。
- 通过检查每个操作的运行时间来检查脚本可能遇到的瓶颈。
- 尽可能避免for循环并使操作向量化,尤其是在使用NumPy或pandas等库的情况下。
- 通过使用多处理来利用计算机的CPU内核。
5. 使用GIT或任何其他版本控制系统
使用GIT + Github帮助我提高了编码技能,更好地组织了项目。由于我是在与朋友和同事合作时使用它的,所以我遵守了过去不遵守的标准。
图源: freecodecamp
无论是在数据科学还是软件开发中,使用版本控制系统都有很多好处。
- 跟踪你的更改
- 回滚到任何以前的代码版本
- 团队成员之间通过合并和请求进行有效的协作
- 提高代码质量
- 代码审查
- 为团队成员分配任务,并提供“持续集成”和“持续交付”挂钩,以自动构建和部署项目。
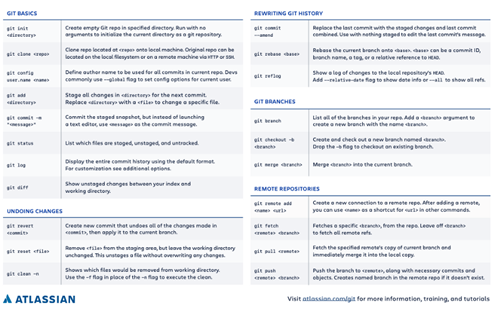
图源: Atlassian
6. 测试代码
如果你要构建一个执行一系列操作的数据管道,且要确保它能够按照设计的目的执行,其中一种方法是编写可检查预期行为的测试。测试可以像检查函数的输出形状或期望值一样简单。
图源:https://pytest-c-testrunner.re
为功能和模块编写测试有很多好处:
- 它提高了代码的稳定性,并使错误更容易发现。
- 防止意外输出
- 有助于检测边缘情况
- 防止将破损的代码推向生产环境
7. 使用日志记录
一旦代码的第一个版本运行了,你需要监察每个步骤,以了解发生了什么、跟踪进度或发现错误,你可以使用日志记录。以下是有效使用日志记录的一些技巧:
- 根据要记录的消息的性质,使用不同的级别(调试,信息,警告)。
- 在日志中提供有用的信息,以帮助解决相关问题。
- import logging
- logging.basicConfig(filename='example.log',level=logging.DEBUG)
- logging.debug('This message should go to the log file')
- logging.info('So should this')
- logging.warning('And this, too')
图源:techgig
告别代码噩梦,这些小技巧要学起来。






















