













什么是IO?
IO模型中,先讨论下什么是IO?
在计算机系统中I/O就是输入(Input)和输出(Output)的意思,针对不同的操作对象,可以划分为磁盘I/O模型,网络I/O模型,内存映射I/O, Direct I/O、数据库I/O等,只要具有输入输出类型的交互系统都可以认为是I/O系统,也可以说I/O是整个操作系统数据交换与人机交互的通道,这个概念与选用的开发语言没有关系,是一个通用的概念。
在如今的系统中I/O却拥有很重要的位置,现在系统都有可能处理大量文件,大量数据库操作,而这些操作都依赖于系统的I/O性能,也就造成了现在系统的瓶颈往往都是由于I/O性能造成的。因此,为了解决磁盘I/O性能慢的问题,系统架构中添加了缓存来提高响应速度;或者有些高端服务器从硬件级入手,使用了固态硬盘(SSD)来替换传统机械硬盘;一个系统的优化空间,往往都在低效率的I/O环节上,很少看到一个系统CPU、内存的性能是其整个系统的瓶颈。
那么数据被Input到哪,Output到哪呢?
Input(输入)数据到内存中,Output(输出)数据到IO设备(磁盘、网络等需要与内存进行数据交互的设备)中;
主存(通常时DRAM)的一块区域,用来缓存文件系统的内容,包含各种数据和元数据。
IO接口
IO设备与内存直接的数据传输通过IO接口,操作系统封装了IO接口,我们编程时可以直接使用;
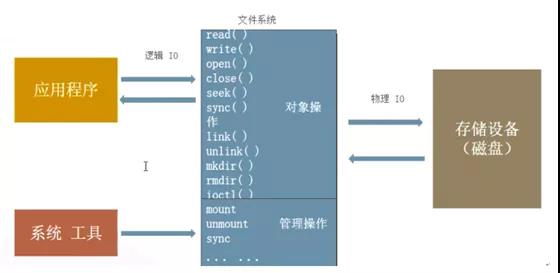
对于用来讲,如果要和外设通信,只需要通过这些系统调用即可实现。
无处不在的缓存
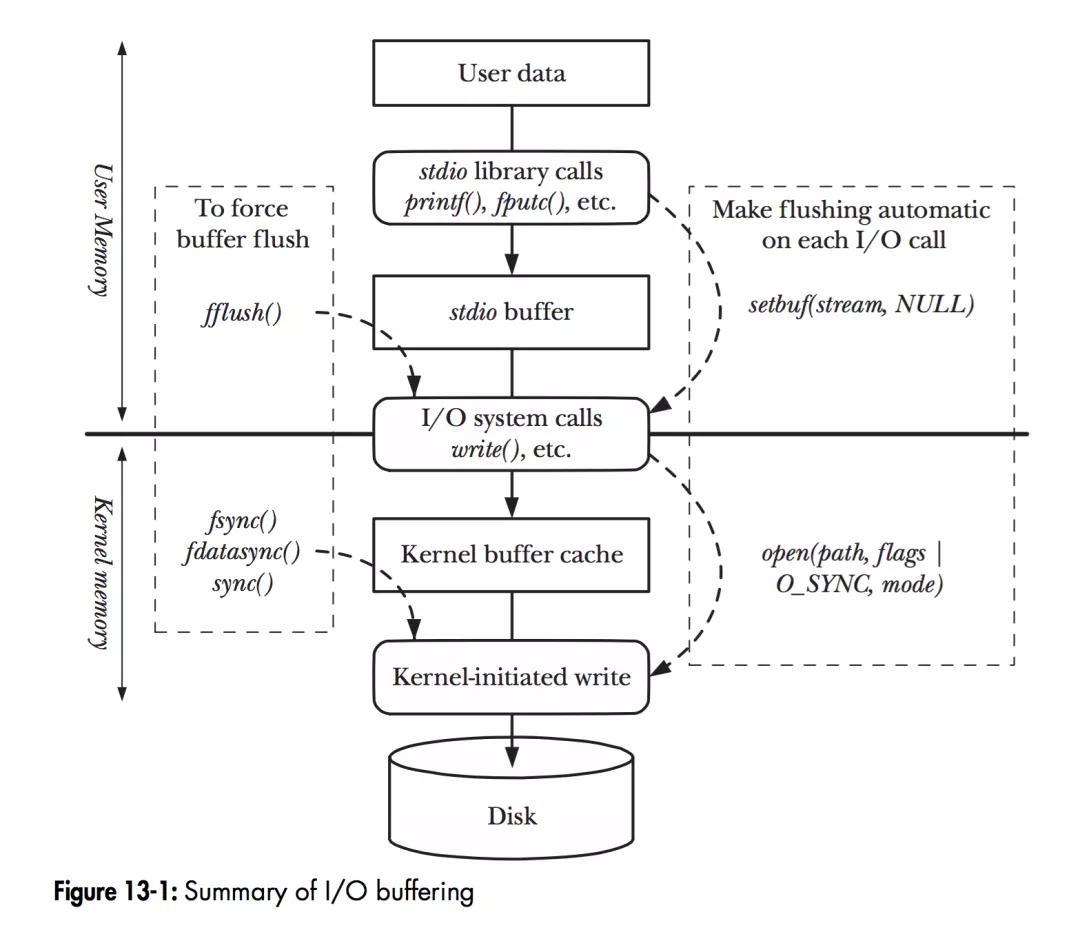
- 如图,当程序调用各类文件操作函数后,用户数据(User Data)到达磁盘(Disk)的流程如图所示。图中描述了Linux下文件操作函数的层级关系和内存缓存层的存在位置。中间的黑色实线是用户态和内核态的分界线。
- 从上往下分析这张图,首先是C语言stdio库定义的相关文件操作函数,这些都是用户态实现的跨平台封装函数。stdio中实现的文件操作函数有自己的stdio buffer,这是在用户态实现的缓存。此处使用缓存的原因很简单——系统调用总是昂贵的。如果用户代码以较小的size不断的读或写文件的话,stdio库将多次的读或者写操作通过buffer进行聚合是可以提高程序运行效率的。stdio库同时也支持fflush(3)函数来主动的刷新buffer,主动的调用底层的系统调用立即更新buffer里的数据。特别地,setbuf(3)函数可以对stdio库的用户态buffer进行设置,甚至取消buffer的使用。
- 系统调用的read(2)/write(2)和真实的磁盘读写之间也存在一层buffer,这里用术语Kernel buffer cache来指代这一层缓存。在Linux下,文件的缓存习惯性的称之为Page Cache,而更低一级的设备的缓存称之为Buffer Cache. 这两个概念很容易混淆,这里简单的介绍下概念上的区别:Page Cache用于缓存文件的内容,和文件系统比较相关。文件的内容需要映射到实际的物理磁盘,这种映射关系由文件系统来完成;Buffer Cache用于缓存存储设备块(比如磁盘扇区)的数据,而不关心是否有文件系统的存在(文件系统的元数据缓存在Buffer Cache中)。
- 综上,既然讨论Linux下的IO操作,自然是跳过stdio库的用户态这一堆东西,直接讨论系统调用层面的概念了。对stdio库的IO层有兴趣的同学可以自行去了解。从上文的描述中也介绍了文件的内核级缓存是保存在文件系统的Page Cache中的。所以后面的讨论基本上是讨论IO相关的系统调用和文件系统Page Cache的一些机制。
Linux IO栈
虽然我们通过系统调用就可以简单的实现对外设的数据读取,实际上这得益于Linux完整的IO栈架构。
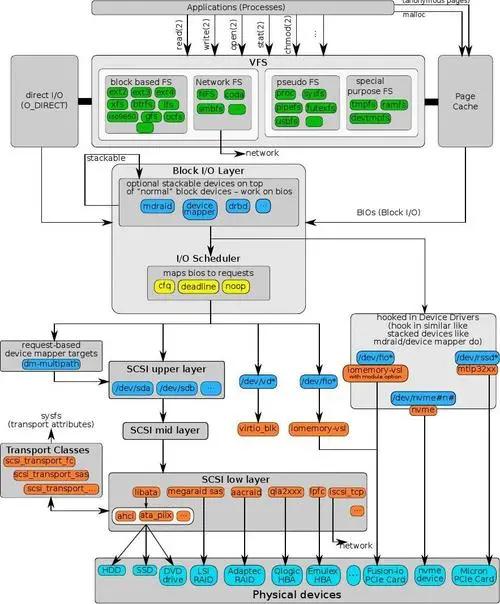
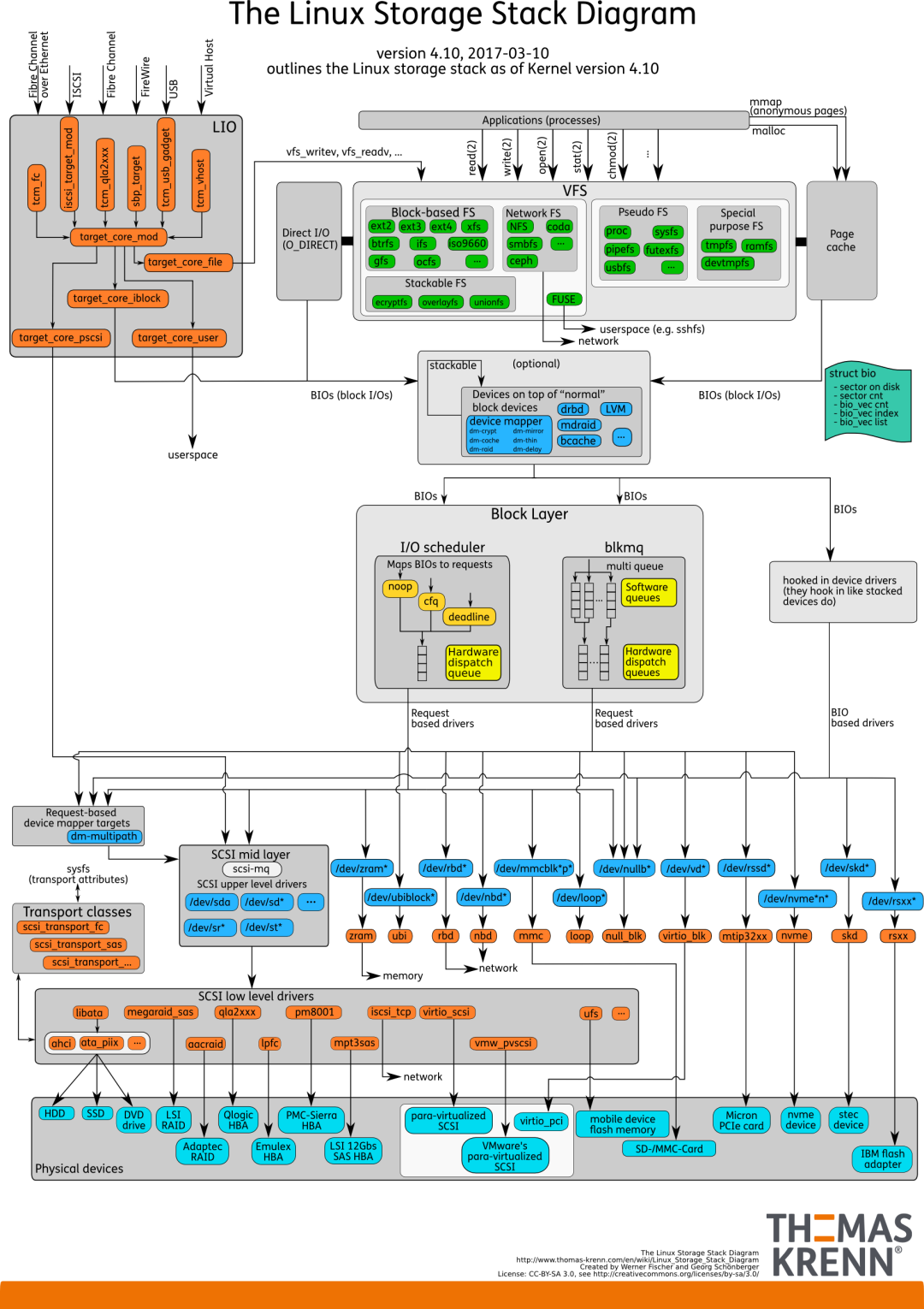
由图可见,从系统调用的接口再往下,Linux下的IO栈致大致有三个层次:
- 文件系统层,以 write(2) 为例,内核拷贝了write(2)参数指定的用户态数据到文件系统Cache中,并适时向下层同步
- 块层,管理块设备的IO队列,对IO请求进行合并、排序(还记得操作系统课程学习过的IO调度算法吗?)
- 设备层,通过DMA与内存直接交互,完成数据和具体设备之间的交互
结合这个图,想想Linux系统编程里用到的Buffered IO、mmap(2)、Direct IO。
这些机制怎么和Linux IO栈联系起来呢?
上面的图有点复杂,画一幅简图,把这些机制所在的位置添加进去:
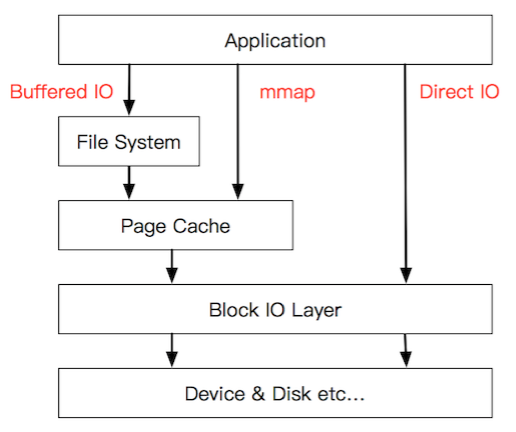
传统的Buffered IO使用read(2)读取文件的过程什么样的?
假设要去读一个冷文件(Cache中不存在),open(2)打开文件内核后建立了一系列的数据结构,接下来调用read(2),到达文件系统这一层,发现Page Cache中不存在该位置的磁盘映射,然后创建相应的Page Cache并和相关的扇区关联。然后请求继续到达块设备层,在IO队列里排队,接受一系列的调度后到达设备驱动层,此时一般使用DMA方式读取相应的磁盘扇区到Cache中,然后read(2)拷贝数据到用户提供的用户态buffer中去(read(2)的参数指出的)。
整个过程有几次拷贝?
从磁盘到Page Cache算第一次的话,从Page Cache到用户态buffer就是第二次了。
而mmap(2)做了什么?
mmap(2)直接把Page Cache映射到了用户态的地址空间里了,所以mmap(2)的方式读文件是没有第二次拷贝过程的。
那Direct IO做了什么?
这个机制更狠,直接让用户态和块IO层对接,直接放弃Page Cache,从磁盘直接和用户态拷贝数据。
好处是什么?
写操作直接映射进程的buffer到磁盘扇区,以DMA的方式传输数据,减少了原本需要到Page Cache层的一次拷贝,提升了写的效率。
对于读而言,第一次肯定也是快于传统的方式的,但是之后的读就不如传统方式了(当然也可以在用户态自己做Cache,有些商用数据库就是这么做的)。
除了传统的Buffered IO可以比较自由的用偏移+长度的方式读写文件之外,mmap(2)和Direct IO均有数据按页对齐的要求,Direct IO还限制读写必须是底层存储设备块大小的整数倍(甚至Linux 2.4还要求是文件系统逻辑块的整数倍)。所以接口越来越底层,换来表面上的效率提升的背后,需要在应用程序这一层做更多的事情。所以想用好这些高级特性,除了深刻理解其背后的机制之外,也要在系统设计上下一番功夫。
阻塞/非阻塞与同步/异步
了解了IO的概念,现在我们来讲解什么是阻塞、非阻塞、同步、异步。
阻塞/非阻塞
针对的对象是调用者自己本身的情况
阻塞
指调用者在调用某一个函数后,一直在等待该函数的返回值,线程处于挂起状态。
非阻塞
指调用者在调用某一个函数后,不等待该函数的返回值,线程继续运行其他程序(执行其他操作或者一直遍历该函数是否返回了值)
同步/异步
针对的对象是被调用者的情况
同步
指的是被调用者在被调用后,操作完函数所包含的所有动作后,再返回返回值
异步
指的是被调用者在被调用后,先返回返回值,然后再进行函数所包含的其他动作。
五种IO模型
下面以recvfrom/recv函数为例,这两个函数都是操作系统的内核函数,用于从(已连接)socket上接收数据,并捕获数据发送源的地址。
recv函数原型:
- ssize_t recv(int sockfd, void *buff, size_t nbytes, int flags)
- sockfd:接收端套接字描述符
- buff:用来存放recv函数接收到的数据的缓冲区
- nbytes:指明buff的长度
- flags:一般置为0
网络IO的本质是socket的读取,socket在linux系统被抽象为流,IO可以理解为对流的操作。对于一次IO访问(以read举例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。
所以说,当一个recv操作发生时,它会经历两个阶段:
- 第一阶段:等待数据准备 (Waiting for the data to be ready)。
- 第二阶段:将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)。
对于socket流而言:
- 第一步:通常涉及等待网络上的数据分组到达,然后被复制到内核的某个缓冲区。
- 第二步:把数据从内核缓冲区复制到应用进程缓冲区。
阻塞IO(Blocking IO)
指调用者在调用某一个函数后,一直在等待该函数的返回值,线程处于挂起状态。好比你去商场试衣间,里面有人,那你就一直在门外等着。(全程阻塞)
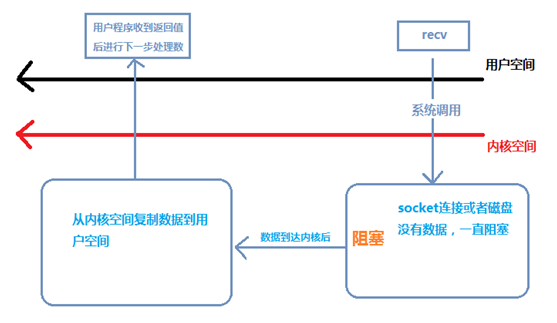
BIO程序流
当用户进程调用了recv()/recvfrom()这个系统调用,kernel就开始了IO的第一个阶段:准备数据(对于网络IO来说,很多时候数据在一开始还没有到达。比如,还没有收到一个完整的UDP包。这个时候kernel就要等待足够的数据到来)。这个过程需要等待,也就是说数据被拷贝到操作系统内核的缓冲区中是需要一个过程的。而在用户进程这边,整个进程会被阻塞(当然,是进程自己选择的阻塞)。
第二个阶段:当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
所以,blocking IO的特点就是在IO执行的两个阶段都被block了。
优点:
1. 能够及时返回数据,无延迟;
2. 对内核开发者来说这是省事了;
缺点:
对用户来说处于等待就要付出性能的代价了;
非阻塞IO
指调用者在调用某一个函数后,不等待该函数的返回值,线程继续运行其他程序(执行其他操作或者一直遍历该函数是否返回了值)。好比你要喝水,水还没烧开,你就隔段时间去看一下饮水机,直到水烧开为止。(复制数据时阻塞)
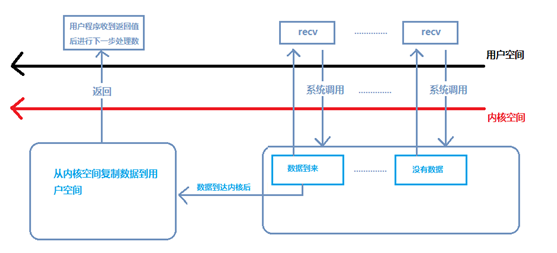
非阻塞IO程序流
当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。
所以,nonblocking IO的特点是用户进程需要不断的主动询问kernel数据好了没有。
同步非阻塞方式相比同步阻塞方式:
优点:
能够在等待任务完成的时间里干其他活了(包括提交其他任务,也就是 “后台” 可以有多个任务在同时执行)。
缺点:
任务完成的响应延迟增大了,因为每过一段时间才去轮询一次read操作,而任务可能在两次轮询之间的任意时间完成。这会导致整体数据吞吐量的降低。
IO多路复用
I/O是指网络I/O,多路指多个TCP连接(即socket或者channel),复用指复用一个或几个线程。意思说一个或一组线程处理多个连接。比如课堂上学生做完了作业就举手,老师就下去检查作业。(对一个IO端口,两次调用,两次返回,比阻塞IO并没有什么优越性;关键是能实现同时对多个IO端口进行监听,可以同时对多个读/写操作的IO函数进行轮询检测,直到有数据可读或可写时,才真正调用IO操作函数。)
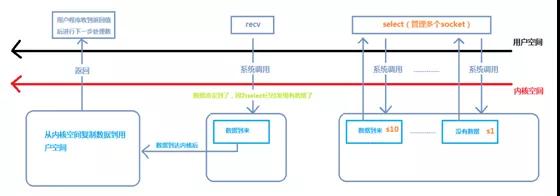
IO多路复用程序流
这种模型其实和BIO是一模一样的,都是阻塞的,只不过在socket上加了一层代理select,select可以通过监控多个socekt是否有数据,通过这种方式来提高性能。
一旦检测到一个或多个文件描述有数据到来,select函数就返回,这时再调用recv函数(这块也是阻塞的),数据从内核空间拷贝到用户空间,recv函数返回。
多路复用的特点是通过一种机制一个进程能同时等待IO文件描述符,内核监视这些文件描述符(套接字描述符),其中的任意一个进入读就绪状态,select, poll,epoll函数就可以返回。对于监视的方式,又可以分为 select, poll, epoll三种方式。
IO多路复用是阻塞在select,epoll这样的系统调用之上,而没有阻塞在真正的I/O系统调用如recvfrom之上。
在I/O编程过程中,当需要同时处理多个客户端接入请求时,可以利用多线程或者I/O多路复用技术进行处理。I/O多路复用技术通过把多个I/O的阻塞复用到同一个select的阻塞上,从而使得系统在单线程的情况下可以同时处理多个客户端请求。与传统的多线程/多进程模型比,I/O多路复用的最大优势是系统开销小,系统不需要创建新的额外进程或者线程,也不需要维护这些进程和线程的运行,降底了系统的维护工作量,节省了系统资源,I/O多路复用的主要应用场景如下:
1. 服务器需要同时处理多个处于监听状态或者多个连接状态的套接字。
2. 服务器需要同时处理多种网络协议的套接字。
在用户进程进行系统调用的时候,他们在等待数据到来的时候,处理的方式不一样,直接等待,轮询,select或poll轮询,两个阶段过程:
第一个阶段有的阻塞,有的不阻塞,有的可以阻塞又可以不阻塞。
第二个阶段都是阻塞的。
从整个IO过程来看,他们都是顺序执行的,因此可以归为同步模型(synchronous)。都是进程主动等待且向内核检查状态。
信号驱动IO
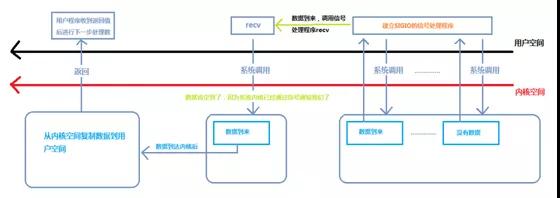
信号驱动IO程序流
在用户态程序安装SIGIO信号处理函数(用sigaction函数或者signal函数来安装自定义的信号处理函数),即recv函数。然后用户态程序可以执行其他操作不会被阻塞。
一旦有数据到来,操作系统以信号的方式来通知用户态程序,用户态程序跳转到自定义的信号处理函数。
在信号处理函数中调用recv函数,接收数据。数据从内核空间拷贝到用户态空间后,recv函数返回。recv函数不会因为等待数据到来而阻塞。
这种方式使异步处理成为可能,信号是异步处理的基础。
在 Linux 中,通知的方式是信号:
如果这个进程正在用户态忙着做别的事,那就强行打断之,调用事先注册的信号处理函数,这个函数可以决定何时以及如何处理这个异步任务。由于信号处理函数是突然闯进来的,因此跟中断处理程序一样,有很多事情是不能做的,因此保险起见,一般是把事件 “登记” 一下放进队列,然后返回该进程原来在做的事。
如果这个进程正在内核态忙着做别的事,例如以同步阻塞方式读写磁盘,那就只好把这个通知挂起来了,等到内核态的事情忙完了,快要回到用户态的时候,再触发信号通知。
如果这个进程现在被挂起了,例如无事可做 sleep 了,那就把这个进程唤醒,下次有 CPU 空闲的时候,就会调度到这个进程,触发信号通知。
异步 API 说来轻巧,做来难,这主要是对 API 的实现者而言的。Linux 的异步 IO(AIO)支持是 2.6.22 才引入的,还有很多系统调用不支持异步 IO。Linux 的异步 IO 最初是为数据库设计的,因此通过异步 IO 的读写操作不会被缓存或缓冲,这就无法利用操作系统的缓存与缓冲机制。
很多人把 Linux 的 O_NONBLOCK 认为是异步方式,但事实上这是前面讲的同步非阻塞方式。需要指出的是,虽然 Linux 上的 IO API 略显粗糙,但每种编程框架都有封装好的异步 IO 实现。操作系统少做事,把更多的自由留给用户,正是 UNIX 的设计哲学,也是 Linux 上编程框架百花齐放的一个原因。
异步IO
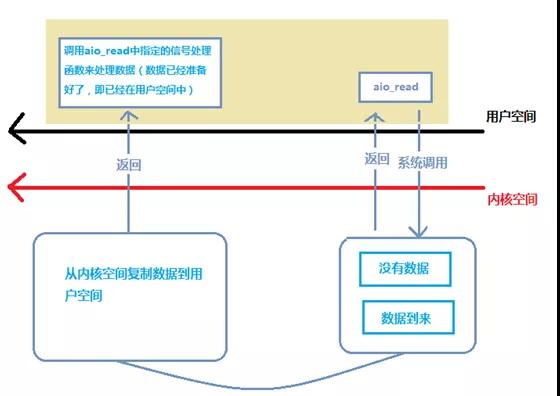
异步IO程序流
异步IO的效率是最高的。
异步IO通过aio_read函数实现,aio_read提交请求,并递交一个用户态空间下的缓冲区。即使内核中没有数据到来,aio_read函数也立刻返回,应用程序就可以处理其他的事情。
当数据到来后,操作系统自动把数据从内核空间拷贝到aio_read函数递交的用户态缓冲区。拷贝完成以信号的方式通知用户态程序,用户态程序拿到数据后就可以执行后续操作。
异步IO和信号驱动IO的不同?
在于信号通知用户态程序时数据所处的位置。异步IO已经把数据从内核空间拷贝到用户空间了;而信号驱动IO的数据还在内核空间,等着recv函数把数据拷贝到用户态空间。
异步IO主动把数据拷贝到用户态空间,主动推送数据到用户态空间,不需要调用recv方法把数据从内核空间拉取到用户态空间。异步IO是一种推数据的机制,相比于信号处理IO拉数据的机制效率更高。
推数据是直接完成的,而拉数据是需要调用recv函数,调用函数会产生额外的开销,故效率低。
本文转载自微信公众号「一口Linux」,可以通过以下二维码关注。转载本文请联系一口Linux公众号。














