由于可以检索应用程序代码的Java表示形式,因此通常认为Android应用程序的逆向工程比较容易。攻击者就是通过了解这些代码版本,收集应用程序信息,来发现漏洞的。如今,大多数Android应用程序编辑器已经意识到了这一点,并尽力使反向工程不再那么容易。由于Java本地接口(Java Native Interface,简称JNI),攻击者通常依靠集成混淆策略或将敏感函数从Java / Kotlin端转移到本机代码。但是,当他们决定同时使用两者时(即,混淆的本机代码),逆向工程过程变得更加复杂。结果,静态查看本机库的反汇编结果非常繁琐且耗时。幸运的是,运行时检查仍然是可能的,并且提供了一种便捷的方法来有效地掌握应用程序的内部机制,甚至避免混淆。JNI(Java Native Interface) Java本地接口,又叫Java原生接口。它允许Java调用C/C++的代码,同时也允许在C/C++中调用Java的代码。可以把JNI理解为一个桥梁,连接Java和底层。其实根据字面意思,JNI就是一个介于Java层和Native层的接口,而Native层就是C/C++层面。
由于针对常规调试器的保护在流行的应用程序中非常普遍,因此使用动态二进制工具(DBI)框架(例如Frida)仍然是进行全面检查的理想选择。从技术上讲,在其他强大函数中,Frida允许用户在本机函数的开头和结尾插入自己的代码,或替换整个实现。但是,Frida在某些时候缺乏粒度,特别是在以指令规模检查执行情况时。在这种情况下,Quarkslab开发的DBI框架QBDI可以帮助Frida在调用给定的本机函数时确定已执行了代码的哪些部分。
首先,我们必须正确设置测试环境。我们假设设备已经植根并且Frida服务器已经在运行并且可以使用。除了Frida,我们还需要安装QBDI。我们可以从源代码编译它或下载Android的发行版,使用说明可以直接从官方页面检索到。解压缩后,我们必须将共享库libQBDI.so推送到设备上的/ data / local / tmp中。除此之外,我们还可以注意到在frida-qbdi.js中定义的QBDI绑定,该文件负责提供QBDI函数的接口。换句话说,它充当QBDI和Frida之间的桥梁。
请注意,必须先关闭SELinux,否则由于某些限制规则,Frida无法将QBDI共享库加载到内存中。这将会显示一条明确的错误消息,告诉用户权限被拒绝。在大多数情况下,仅使用root特权运行此命令行即可完成此工作:
- setenforce 0
现在我们已经具备了基于Frida和QBDI编写脚本的所有要求。
跟踪本机函数
在对JNI共享库执行反向工程时,始终值得检查JNI_OnLoad()。确实,此函数在库加载后立即调用,并负责初始化。它能够与Java端进行交互,例如设置类的属性,调用Java函数以及通过几个JNI函数注册其他本机方法。攻击者通常依靠这些属性来隐藏一些敏感的检查和秘密的内部机制。
接下来,让我们假设我们要分析一个流行的Android应用程序,比如Whatsapp,其软件包名称为com.whatsapp,这是当前Android上最广泛的即时消息解决方案。它嵌入了一堆共享库,其中一个是libwhatsapp.so。不过要注意的是,该库并不位于常规的lib /目录中,因为在运行时存在一种解压缩机制,该机制可将其从存档中提取出来,然后将其加载到内存中,我们的目标是弄清楚它的初始化函数在做什么。
利用 Frida
- /** * frida -Uf com.whatsapp --no-pause -l script.js */function processJniOnLoad(libraryName) {
- const funcSym = "JNI_OnLoad";
- const funcPtr = Module.findExportByName(libraryName, funcSym);
- console.log("[+] Hooking " + funcSym + "() @ " + funcPtr + "...");
- // jint JNI_OnLoad(JavaVM *vm, void *reserved);
- var funcHook = Interceptor.attach(funcPtr, {
- onEnter: function (args) {
- const vm = args[0];
- const reserved = args[1];
- console.log("[+] " + funcSym + "(" + vm + ", " + reserved + ") called");
- },
- onLeave: function (retval) {
- console.log("[+]\t= " + retval);
- }
- });}function waitForLibLoading(libraryName) {
- var isLibLoaded = false;
- Interceptor.attach(Module.findExportByName(null, "android_dlopen_ext"), {
- onEnter: function (args) {
- var libraryPath = Memory.readCString(args[0]);
- if (libraryPath.includes(libraryName)) {
- console.log("[+] Loading library " + libraryPath + "...");
- isLibLoaded = true;
- }
- },
- onLeave: function (args) {
- if (isLibLoaded) {
- processJniOnLoad(libraryName);
- isLibLoaded = false;
- }
- }
- });}Java.perform(function() {
- const libraryName = "libwhatsapp.so";
- waitForLibLoading(libraryName);});
首先,借助Frida提供的便捷API,我们可以轻松地挂接我们要研究的函数。但是,由于Android应用程序中嵌入的库是通过System.loadLibrary()动态加载的,该函数在后台调用了本机android_dlopen_ext(),因此我们需要等待将目标库放入进程的内存中。使用此脚本,我们可以只访问函数的输入(参数)和输出(返回值),也就是说,我们位于函数层。这是非常有限的,仅凭这一点基本上还不足以准确掌握内部的情况。因此,在这种精确的情况下,我们希望在较低级别上彻底检查该函数。
利用 Frida 和 QBDI
QBDI提供的导入函数可以帮助我们克服以上的问题,实际上,该DBI框架允许用户通过跟踪执行的指令来执行细粒度的分析。这对我们非常有用,因为我们可以深入了解我们的目标函数。
这样做的想法是,不是让JNI_OnLoad()在常规启动期间运行,而是在基本块/指令范围内通过有条件的上下文来执行它,以便确切地知道已执行了什么。由于我们可以将这两个DBI框架结合在一起,因此可以在我们之前编写的Frida脚本的基础上集成这一全新的部分。
但是,我们使用的Interceptor.attach()函数只允许我们定义onEnter和onLeave回调。它意味着真正的函数总是被执行,而不管你的条目回调应该做什么。因此,初始化函数将执行两次:首先通过QBDI执行,然后正常执行。这是有问题的,因为根据情况不同,可能会出现一些意外的运行时错误,因为这个函数只需要调用一次。
幸运的是,我们可以利用Frida的拦截器模块带来的另一个函数,该函数包括替换本机函数的实现。这样做,我们能够设置QBDI上下文,执行检测的函数并像往常一样无缝地将返回值转发给调用方,以防止应用程序崩溃,该技术旨在使过程足够稳定以恢复正常执行。
然而,我们仍然面临一个问题,初始函数已被我们自己的新实现完全覆盖。换句话说,该函数的代码不是原始代码,而是由Frida早些时候进行检测的。因此,在我们的代码中,我们必须在使用QBDI执行该函数之前恢复到真正的版本。
修改脚本后,processJniOnLoad()函数如下所示:

初始化
现在让我们编写负责在QBDI上下文中执行该函数的函数,首先,我们需要初始化一个VM,实例化它的相关状态(通用寄存器),并分配一个伪堆栈,该堆栈将在函数执行期间使用。然后,我们必须将QBDI的上下文与当前上下文进行同步,也就是说,将实际CPU寄存器的值放入将要使用的QBDI。现在我们可以决定要检测代码的哪些部分。我们可以显式定义一个任意地址范围,也可以要求DBI检测函数地址所在模块的整个地址空间。为方便起见,在本示例中将使用后者。
回调函数设置
我们必须指定所需的回调函数的种类,接下来,我们要跟踪已执行的每条指令,因此我要放置一条预指令代码回调,这意味着将在位于目标模块中的每个已执行指令之前调用我的函数。
此外,我们还可以添加几个事件回调函数,以便在执行转移到QBDI未检测到的部分代码中或从中返回时通知该事件。当代码与其他模块(例如系统库)(libc.so,libart.so,libbinder.so等)进行交互时,此函数非常有用。请注意,根据您要监视的内容,其他几种回调类型可能会很有帮助。
函数调用
现在我们准备通过QBDI调用目标函数,当然,我们需要传递预期的参数,在我们的例子中是一个指向JavaVM对象的指针和一个空指针。然后,我们可以根据使用的调用约定在特定的QBDI寄存器或虚拟堆栈上检索返回值。这个值必须从我们之前编写的本机替换函数中被转发和返回。否则,应用程序很可能会因为对JNI版本的检查不满意而停止运行,JNI_OnLoad()应该返回JNI版本。
我们可以选择使用QBDI的CPU恢复真正的CPU上下文。
- const qbdi = require("/path/to/frida-qbdi");qbdi.import();function qbdiExec(ctx, funcPtr, funcSym, args, postSync) {
- var vm = new QBDI(); // create a QBDI VM
- var state = vm.getGPRState();
- var stack = vm.allocateVirtualStack(state, 0x10000); // allocate a virtual stack
- state.synchronizeContext(ctx, SyncDirection.FRIDA_TO_QBDI); // set up QBDI's context
- vm.addInstrumentedModuleFromAddr(funcPtr);
- var icbk = vm.newInstCallback(function (vm, gpr, fpr, data) {
- var inst = vm.getInstAnalysis();
- console.log("0x" + inst.address.toString(16) + " " + inst.disassembly);
- return VMAction.CONTINUE;
- });
- var iid = vm.addCodeCB(InstPosition.PREINST, icbk); // register pre-instruction callback
- var vcbk = vm.newVMCallback(function (vm, evt, gpr, fpr, data) {
- const module = Process.getModuleByAddress(evt.basicBlockStart);
- const offset = ptr(evt.basicBlockStart - module.base);
- if (evt.event & VMEvent.EXEC_TRANSFER_CALL) {
- console.warn(" -> transfer call to 0x" + evt.basicBlockStart.toString(16) + " (" + module.name + "@" + offset + ")");
- }
- if (evt.event & VMEvent.EXEC_TRANSFER_RETURN) {
- console.warn(" <- transfer return from 0x" + evt.basicBlockStart.toString(16) + " (" + module.name + "@" + offset + ")");
- }
- return VMAction.CONTINUE;
- });
- var vid = vm.addVMEventCB(VMEvent.EXEC_TRANSFER_CALL, vcbk); // register transfer callback
- var vid2 = vm.addVMEventCB(VMEvent.EXEC_TRANSFER_RETURN, vcbk); // register return callback
- const javavm = ptr(args[0]);
- const reserved = ptr(args[1]);
- console.log("[+] Executing " + funcSym + "(" + javavm + ", " + reserved + ") through QBDI...");
- vm.call(funcPtr, [javavm, reserved]);
- var retVal = state.getRegister(0); // x86 so return value is stored on $eax
- console.log("[+] " + funcSym + "() returned " + retVal);
- if (postSync) {
- state.synchronizeContext(ctx, SyncDirection.QBDI_TO_FRIDA);
- }
- return retVal;}
最终,此脚本必须使用frida-compile进行编译,以便正确包含包含QBDI绑定的frida-qbdi.js。官方文档页对编译过程进行了详细说明。
生成一个覆盖文件
具有包含已执行的所有指令的跟踪是很有必要的,但对于反向工程来说并不方便。事实上,我们不能一眼就分辨出整个执行过程中的路径。为了正确地呈现捕获的轨迹,在反汇编器中集成可能是一个好主意。这样,人们就可以准确地看到全部的路径。然而,大多数反汇编器本身并没有提供这样的选项。对我们来说幸运的是,各种插件都提供了这样的选项。在本例中,我们使用Lighthouse和Dragondance分别用于IDA Pro和Ghidra。这些插件可以通过导入drcov格式的代码覆盖文件来轻松配置,DynamioRIO使用这种格式存储关于代码覆盖率的信息。
drcov格式非常简单:除了标头字段外,还必须指定描述进程的内存布局的模块表,为每个模块分配一个惟一的ID。此后,就有了所谓的基本块表。该表包含执行期间已命中的每个基本块,一个基本块由三个属性定义:它的开始(相对)地址,它的大小和它所属模块的ID。
由于我们能够在每个基本块的开头放置一个回调,因此我们可以确定这些值,从而生成我们自己的文件。现在,我们需要检索基地址和所有已执行的基本块的大小,而不是按指令规模工作。实际上,我们必须定义一个类型为BASIC_BLOCK_NEW 的QBDI事件回调函数,该函数负责收集此类信息。每当QBDI将要执行一个新的基本程序块时,我们的函数都会被调用,到目前为止尚不知道。在本示例中,我们不仅要打印有关此基本块的一些有趣的值,还要创建一个代码覆盖率文件,以后可以在反汇编器中将其导入。但是,在Frida脚本的上下文中,我们无法操作文件。结果,我们必须停止使用frida命令行实用程序,并直接依赖于Frida提供的消息传递系统从底层Python脚本运行我们的JS脚本。这样做使我们能够在JS和Python端之间进行通信,然后对所需的文件系统执行所有操作。
- var vcbk = vm.newVMCallback(function (vm, evt, gpr, fpr, data) {
- const module = Process.getModuleByAddress(evt.basicBlockStart);
- const base_addr = ptr(evt.basicBlockStart - module.base); // address must be relative to the module's start
- const size = evt.basicBlockEnd - evt.basicBlockStart;
- send({"bb": 1}, getBBInfo(base_addr, size, module)); // send the newly discovered basic block to the Python side
- return VMAction.CONTINUE;});var vid = vm.addVMEventCB(VMEvent.BASIC_BLOCK_NEW, vcbk);
请注意,getBBInfo()函数仅在发送消息之前先序列化有关基本块的信息。显然,Python端必须处理此类消息,将与执行相关的内容保留在内存中,并最终以上述正确的格式相应地生成代码覆盖文件。如果一切顺利,由于其相应的代码覆盖插件,可以将输出文件加载到IDA Pro或Ghidra中。所有已执行的基本块都将突出显示,现在我们可以更清楚地遵循执行流程,而只关注代码的相关部分。
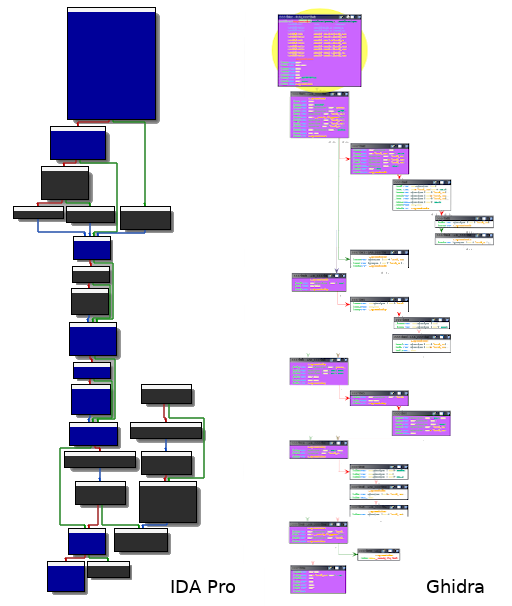
总结
Java/Kotlin逆向工程的易用性使得Android应用程序开发人员可以使用C/ c++来实现某些漏洞层面的操作。因此,本文所讲的方法就是要让逆向工程师逆向的过程变得很困难。因此,将QBDI与Frida一起使用是一个非常好的选择,尤其是在研究那些本机函数时。这种组合确实提供了一种方法,可以弄清一个函数在不同层次上的作用,即函数、基本块和指令规模。此外,还可以利用QBDI的执行传输事件来解析对系统库的外部调用,或者跟踪内存访问,然后了解执行的总体情况。为了有效地协助反向工程师,可以将收集的信息明智地集成到一些现有的面向反向工程的工具中,以完善其静态分析。除了生成执行流程的直观表示之外,从运行时获取此类反馈对于其他与安全相关的目的(如模糊测试)也很有价值。还值得注意的是,如果函数很重要,Frida和QBDI都可以提供C / C ++ API。
本文翻译自:https://blog.quarkslab.com/why-are-frida-and-qbdi-a-great-blend-on-android.html如若转载,请注明原文地址: