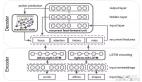
对于运维的日常工作来说,服务器监控是必须且最基础的一项内容。在企业基础设施运维过程中,管理员必须能够掌握所有服务器的运行状况,以便及时发现问题,尽可能减少故障的发生。通常我们会借助一些监控的软件来获取每个服务器的基础指标并进行集中的查看、分析、监控。
市面上开源、收费的服务器监控系统非常多,例如老牌的zabbix、nagios、NewRelic、CollectD等,近期开始流行的Telegraf、Prometheus。各类系统都有其出彩的点,例如Zabbix强大的生态、NewRelic的服务、Prometheus的云原生友好等。服务器监控相对中间件、业务监控更加基础,关注点主要集中在监控的易用性、稳定性、实时性、报警丰富度、报表使用便捷度等。
本期为大家介绍如何使用阿里云SLS来快速构建一套完整的服务器/主机基础指标实时监控方案。
SLS时序存储简介
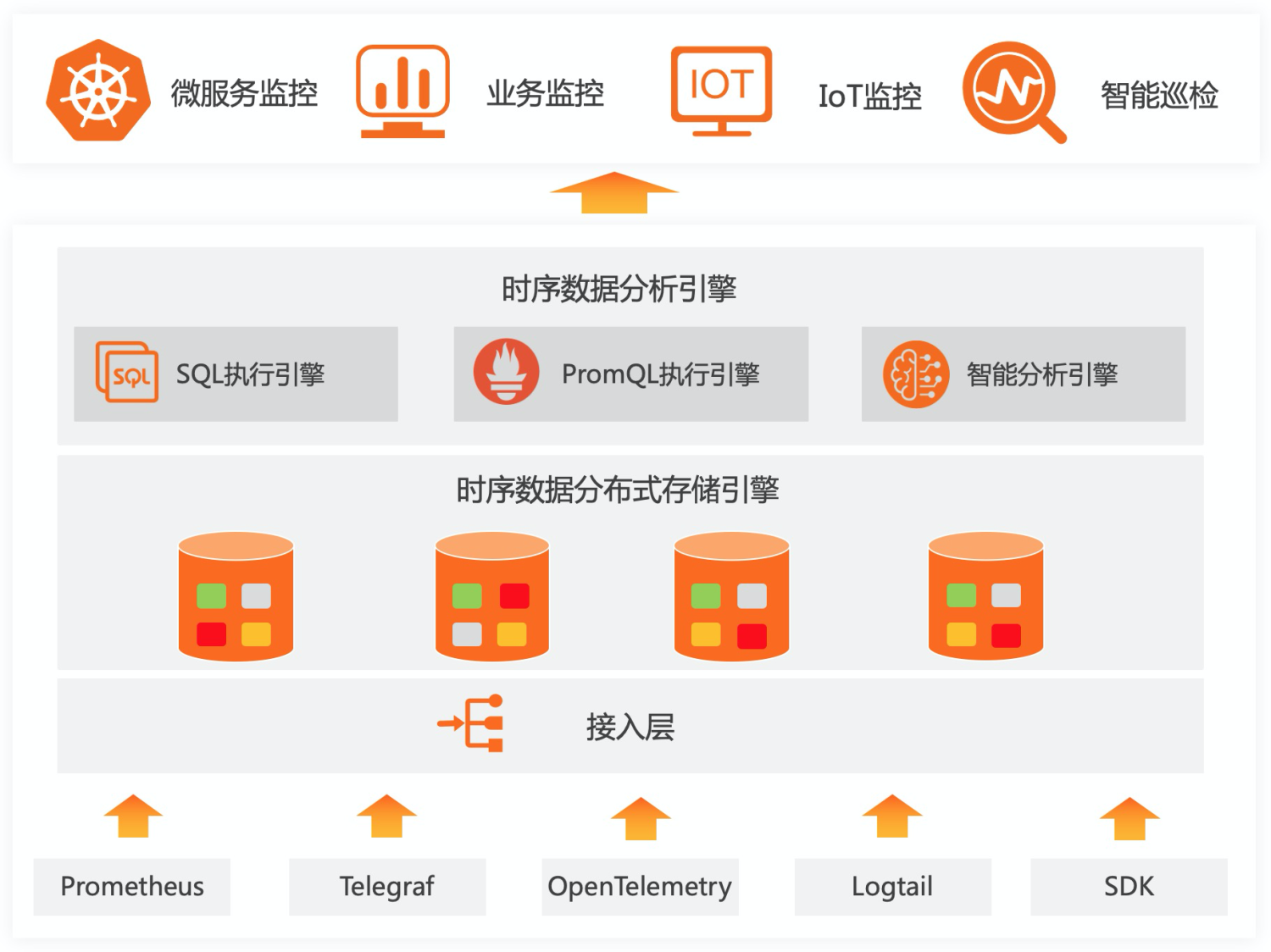
SLS的日志存储引擎在2016年对外发布,目前承接阿里内部以及众多企业的日志数据存储,每天有数十PB的日志类数据写入。其中有很大一部分属于时序类数据或者用来计算时序指标,为了让用户能够一站式完成整个DevOps生命周期的数据接入、清洗、加工、提取、存储、可视化、监控、问题分析等过程,我们专门推出了时序存储的功能,与日志存储一道为大家解决各类机器数据的存储问题。
SLS时序存储从设计之初就是为了解决阿里内部与众多头部企业客户的时序存储需求,并借助于阿里内部多年的技术积累,使之可以适应绝大部分企业级时序监控/分析诉求。SLS时序存储的特点主要有:
- 丰富上下游:数据接入上SLS支持众多采集方式,包括各类开源Agent以及阿里云内部的监控数据通道;同时存储的时序数据支持对接各类的流计算、离线计算引擎,数据完全开放;
- 高性能:SLS存储计算分离架构充分发挥集群能力,尤其在大量数据下端对端的速度提升显著;
- 免运维:SLS的时序存储完全是服务化,无需用户自己去运维实例,而且所有数据都是3副本高可靠存储,不用担心数据的可靠性问题;
- 开源友好:SLS的时序存储原生支持Prometheus的写入和查询,并支持SQL92的分析方法,可以原生对接Grafana等可视化方案;
- 智能:SLS提供了各种AIOps算法,例如多周期估算、预测、异常检测、时序分类等各类时序算法,可以基于这些算法快速构建适应于公司业务的智能报警、诊断平台。
服务器监控方案概述
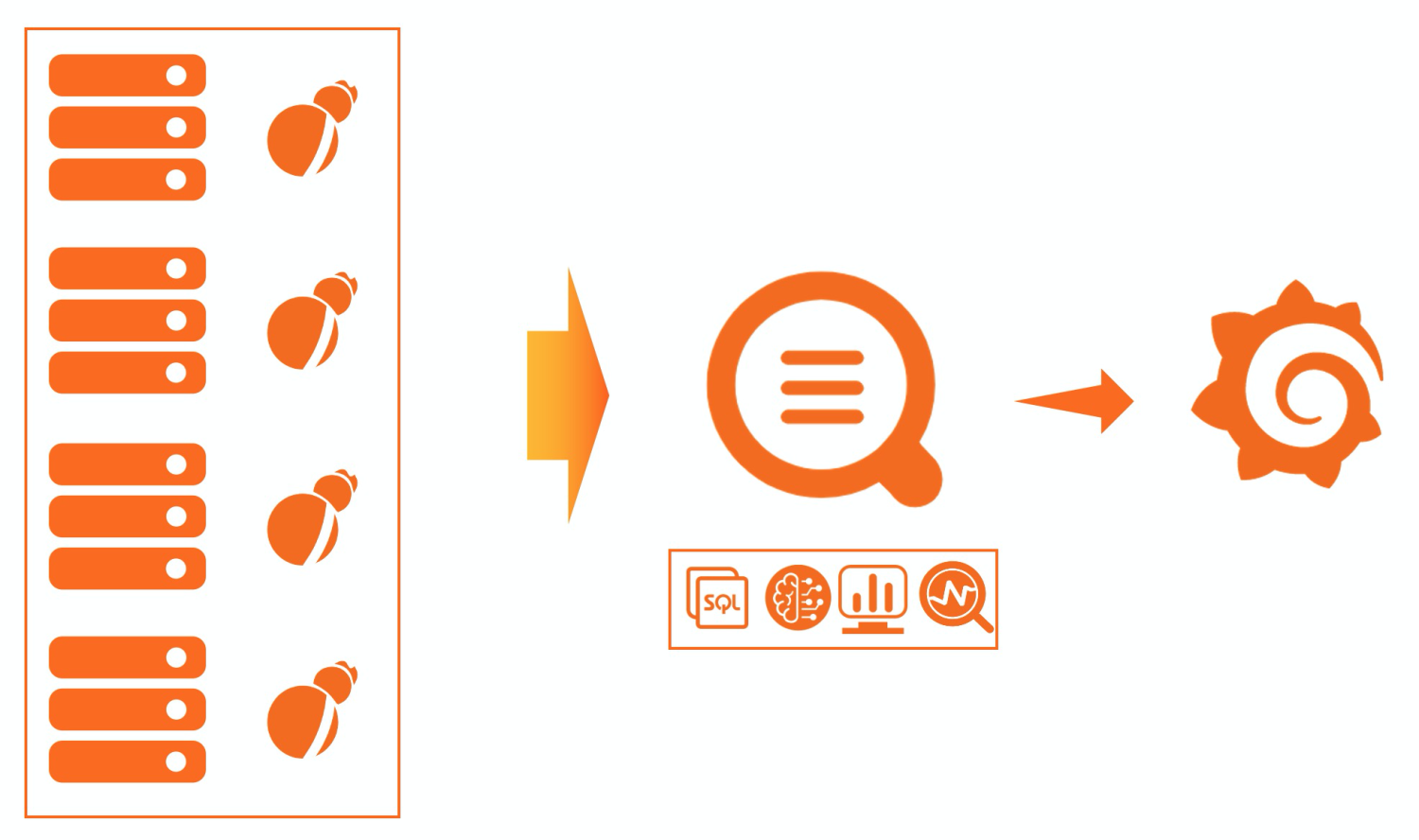
SLS的主机监控方案非常简单,只需要安装一个Logtail就可以采集各个主机的基础指标,服务端都是云化,无需运维,默认SLS提供了可视化的仪表盘,也可以通过Grafana来进行更加专业的可视化。
目前Logtail采集了主机常用的基础指标,包括CPU、内存、网络、磁盘等,其中对较为关键的指标都做了可视化,便于直接查看。
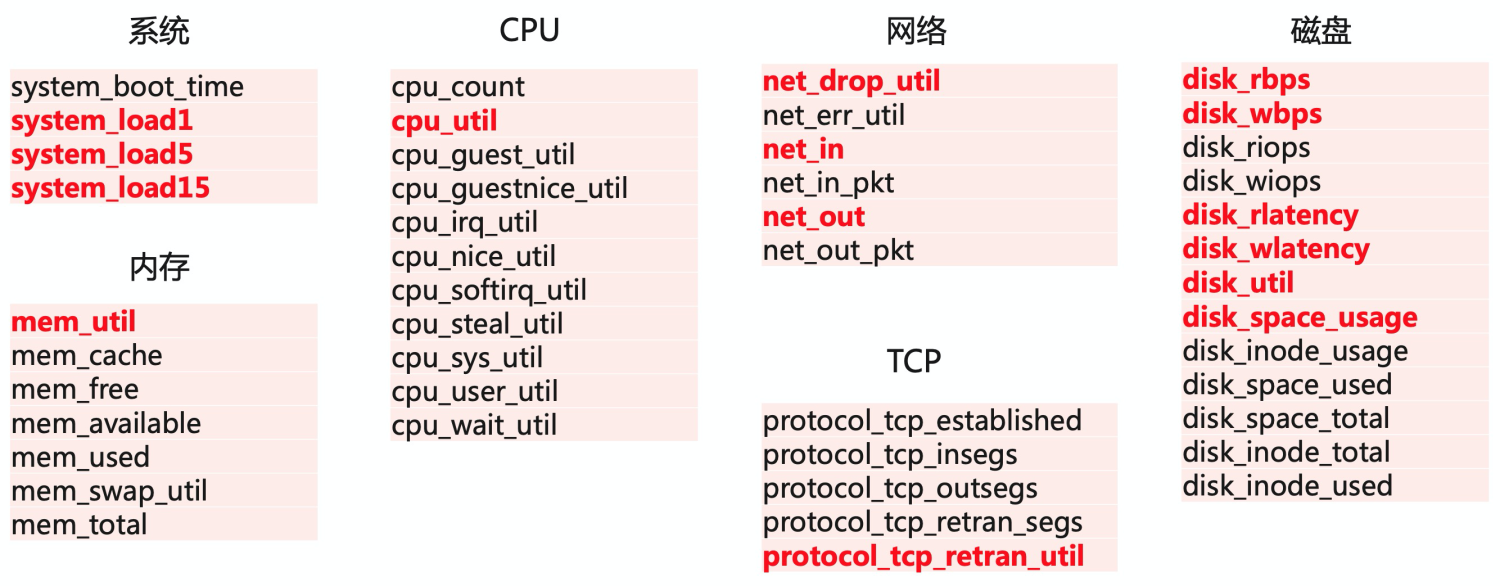
数据接入
数据接入的流程非常简单,只需要在SLS控制台上操作即可完成(对于非阿里云的服务器,需要在服务器上额外执行2条命令),具体接入的方法可参见:采集主机监控数据。
接入过程中最核心的就是给每台主机的Logtail增加一个采集配置,Logtail的采集配置可以完全云化管理,无需登录每台服务器手动配置。
{
"inputs": [
{ "detail": {
"IntervalMs": 30000
}, "type": "metric_system_v2"
} ]}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
可视化
在运维可视化领域Grafana是当前大家接受度最高的可视化方案,SLS为主机监控专门增加了2个Dashboard模板,包括一张集群级别的监控大盘和单机的详细指标大盘。这些大盘可以一键导入到Grafana中。
Grafana的配置流程如下:
- 在Grafana中把SLS的时序库作为Prometheus的数据源,设置方式可参考:Grafana可视化配置。
- 导入Grafana模板市场中的SLS模板:主机监控集群指标、主机监控单机指标。
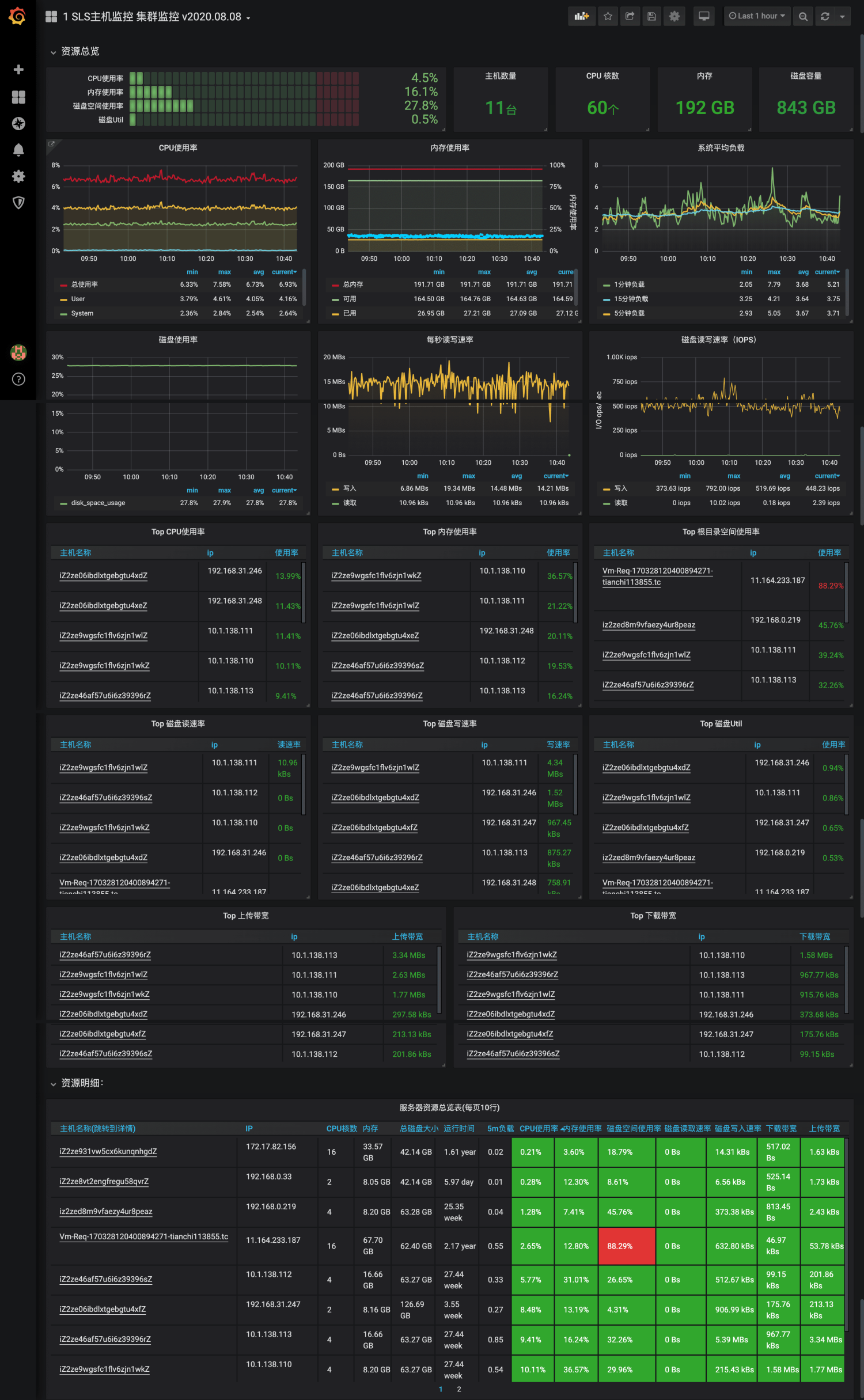
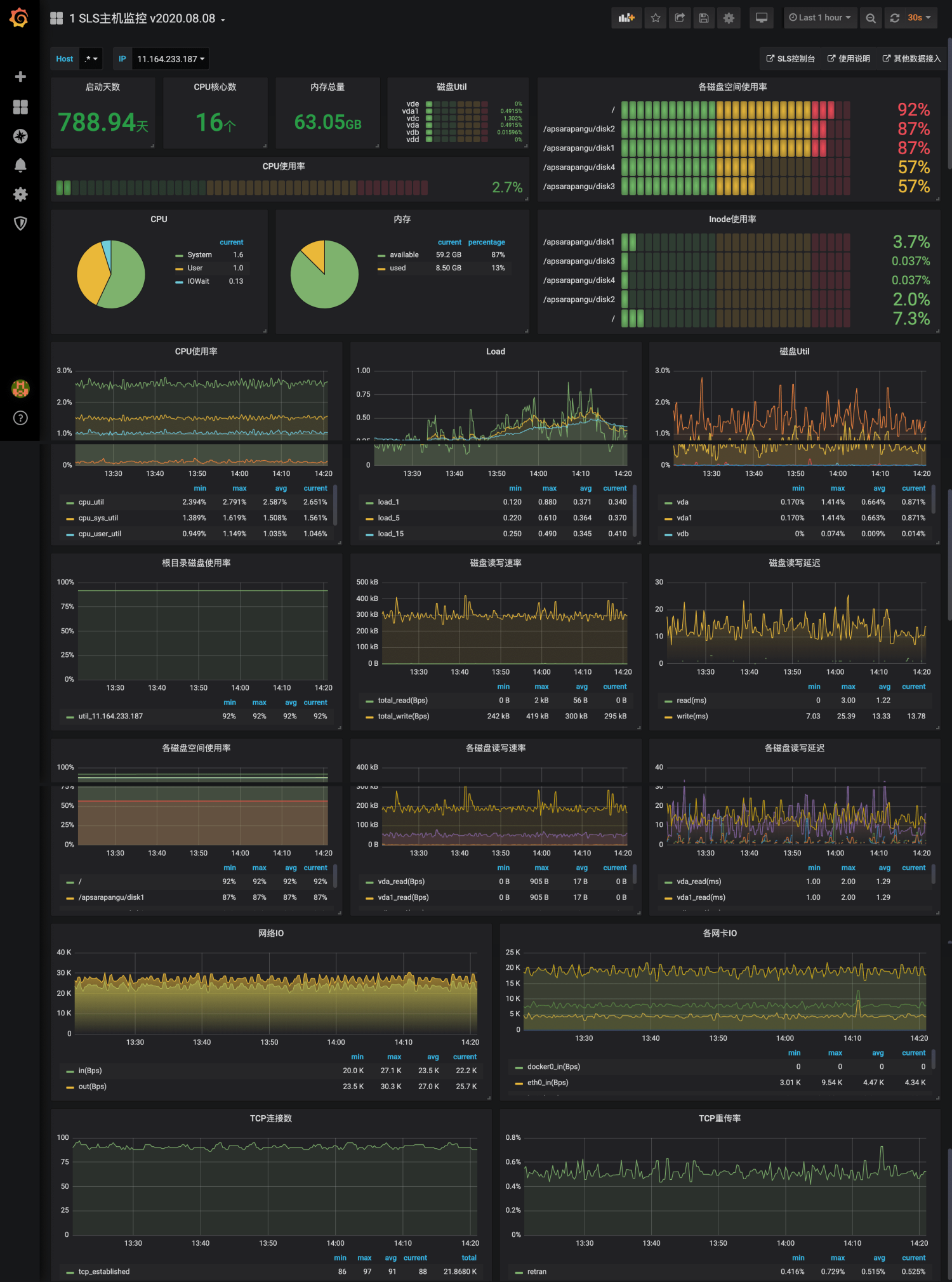
监控数据分析与告警配置
作为一个合格的运维人员,仅仅配置完炫酷的监控仪表盘还不够,还需要对集群设置好足够的告警项并能在需要排查问题的时候利用监控数据分析的语法快速定位问题。这些本质上都是对集群的指标进行一些计算和统计。
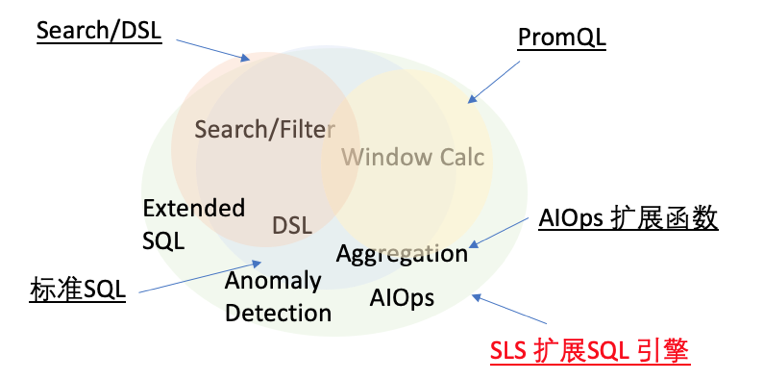
SLS时序数据支持SQL、PromQL以及SQL+PromQL等多种查询方式,PromQL查询语言相对更加简洁,SQL能够实现的语义更加强大。而主机的监控数据相对比较简单,建议使用PromQL或SQL+PromQL的方式。
下面介绍几个在告警、分析中经常会用到的几个统计方式:
- 计算所有机器的某个指标平均值,例如平均CPU
- 查找某个指标最高的N台机器,比如查找内存占用最高的5台机器
- 查找某个指标超过X的机器,比如找到1分钟网络流量超过10M的机器
- 计算某台机器的某个指标相对某个时间点的变化,比如计算某台机器磁盘使用率相比1天前的变化
这些用PromQL实现起来非常容易,可以在Grafana的Explore页面直接调试:
- 平均CPU: avg(cpu_util)
- 查找内存占用最高的5台机器:topk(5, mem_util)
- 找出1分钟网络流量超过10M的机器:(sum_over_time(net_in[1m]) + sum_over_time(net_out[1m])) > (10*1024*1024)
- 计算某台机器磁盘使用率相比1天前的变化:disk_util{hostname="iZ2ze06ibdlxtgebgtu4xdZ"} - disk_util{hostname="iZ2ze06ibdlxtgebgtu4xdZ"} offset 1d
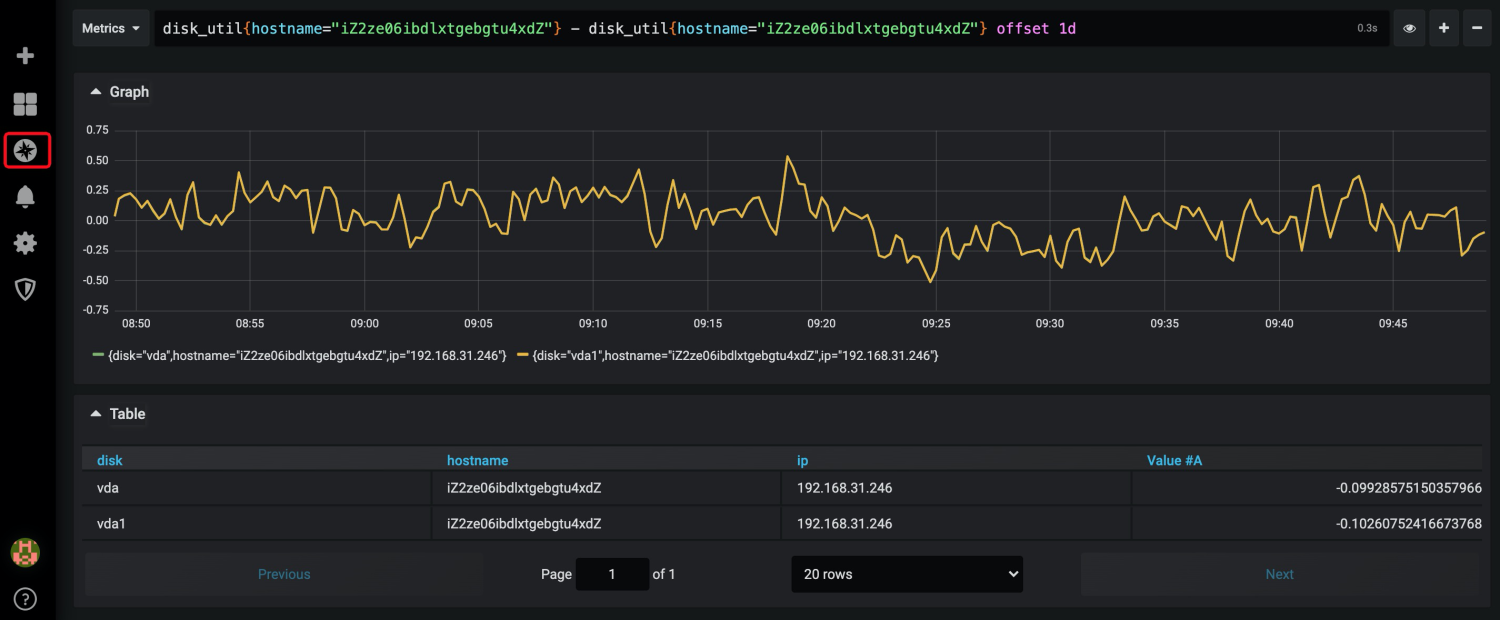
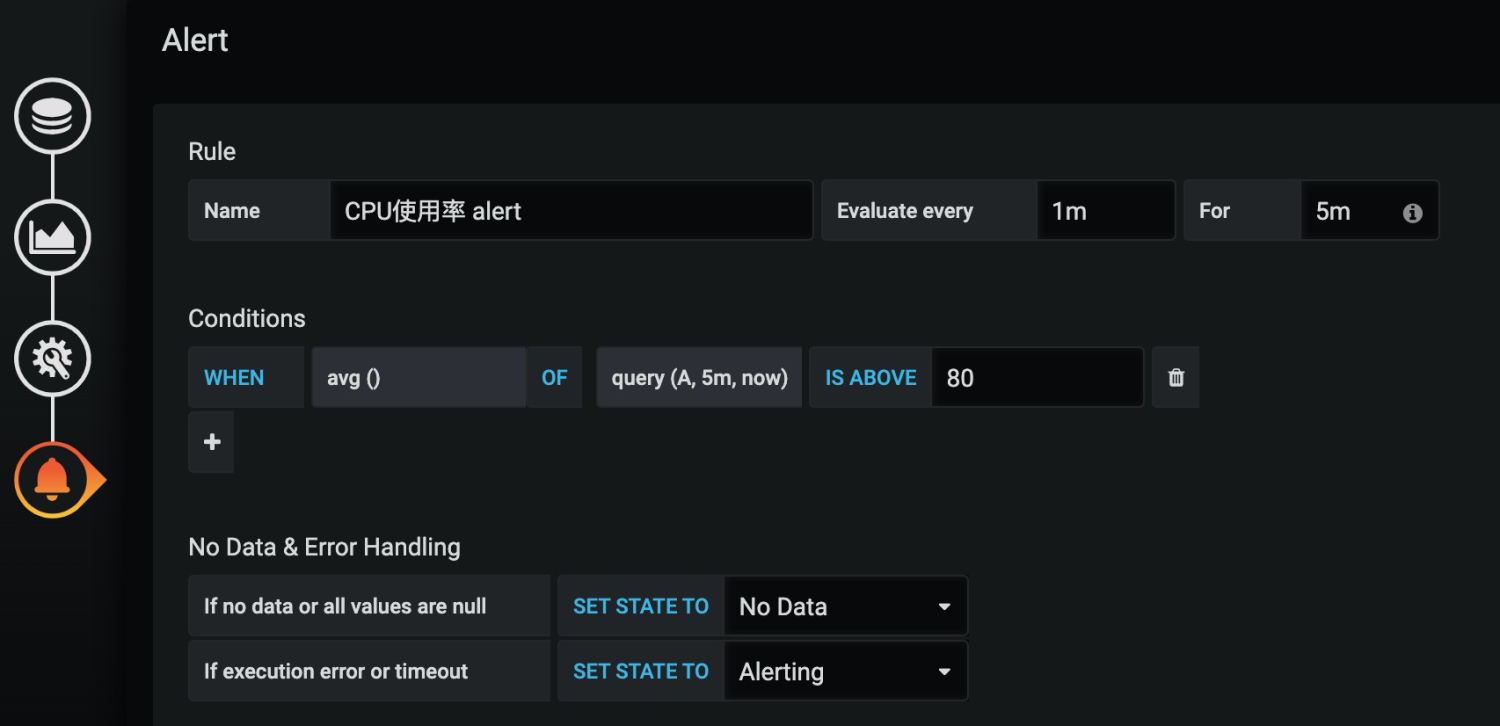
而告警也可以直接在Grafana上配置,可以在集群监控的Dashboard上直接配置告警,例如下面是配置CPU集群平均CPU超限的告警,告警规则是:每分钟计算最近5分钟内的集群CPU平均利用率,如果连续5分钟超过80%则触发告警。
总结
服务的基础指标监控是我们监控运维领域最基础的工作之一,构造公司IT的全方位监控还有很多工作要做,例如中间件监控、云产品监控、应用监控、业务监控等,而这些利用SLS的日志和时序存储功能都可以很容易的实现,其他相关的实现我们会在后续文章中给大家呈现。