通过我们对各种容器网络模型的实现原理已经有了基本的认识,然而真正将容器技术发扬光大的是Kubernetes容器编排平台。Kubernetes通过整合规模庞大的容器实例形成集群,这些容器实例可能运行在异构的底层网络环境中,如何保证这些容器间的互通是实际生产环境中首要考虑的问题之一。
Kubernetes网络基本要求
Kubernetes对容器技术做了更多的抽象,其中最重要的一点是提出pod的概念,pod是Kubernetes资源调度的基本单元,我们可以简单地认为pod是容器的一种延伸扩展,从网络的角度来看,pod必须满足以下条件:
- 每一个Pod都有一个独特的IP地址,所有pod都在一个可以直接连通的、扁平的网络空间中
- 同一个pod内的所有容器共享同一个netns网络命名空间
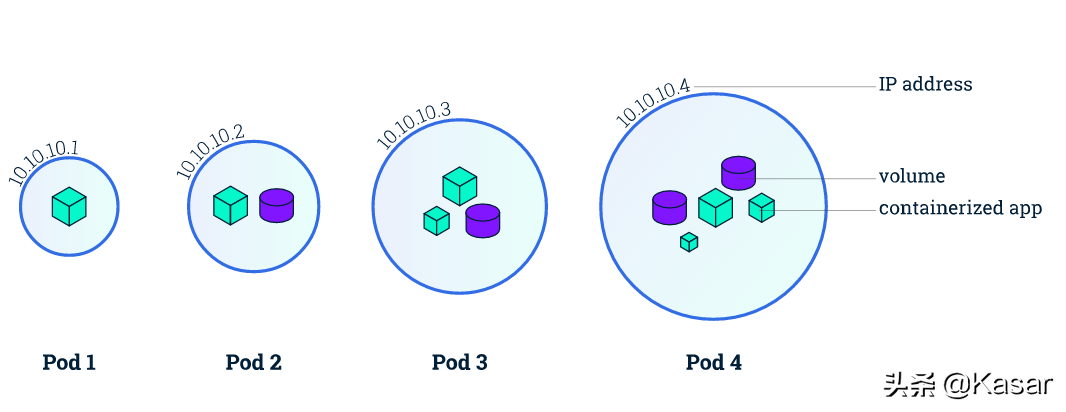
基于这样的基本要求,我们可以知道:
- 同一个pod内的所有容器之间共享端口,可直接通过localhost+端口来访问
- 由于每个pod有单独的IP,所以不需要考虑容器端口与主机端口映射以及端口冲突问题
事实上,Kubernetes进一步确定了对一个合格集群网络的基本要求:
- 任意两个pod之间其实是可以直接通信的,无需显式地使用NAT进行地址的转换;
- 任意集群节点node与任意pod之间是可以直接通信的,无需使用明显的地址转换,反之亦然;
- 任意pod看到自己的IP跟别人看见它所用的IP是一样的,中间不能经过地址转换;
也就是说,必须同时满足以上三点的网络模型才能适用于kubernetes,事实上,在早期的Kubernetes中,并没有什么网络标准,只是提出了以上基本要求,只有满足这些要求的网络才可以部署Kubernetes,基于这样的底层网络假设,Kubernetes设计了pod-deployment-service的经典三层服务访问机制。直到1.1发布,Kubernetes才开始采用全新的CNI(Container Network Interface)网络标准。
CNI
其实,我们在前面介绍容器网络的时候,就提到了CNI网络规范,CNI相对于CNM(Container Network Model)对开发者的约束更少,更开放,不依赖于Docker。事实上,CNI规范确实非常简单,详见:https://github.com/containernetworking/cni/blob/master/SPEC.md
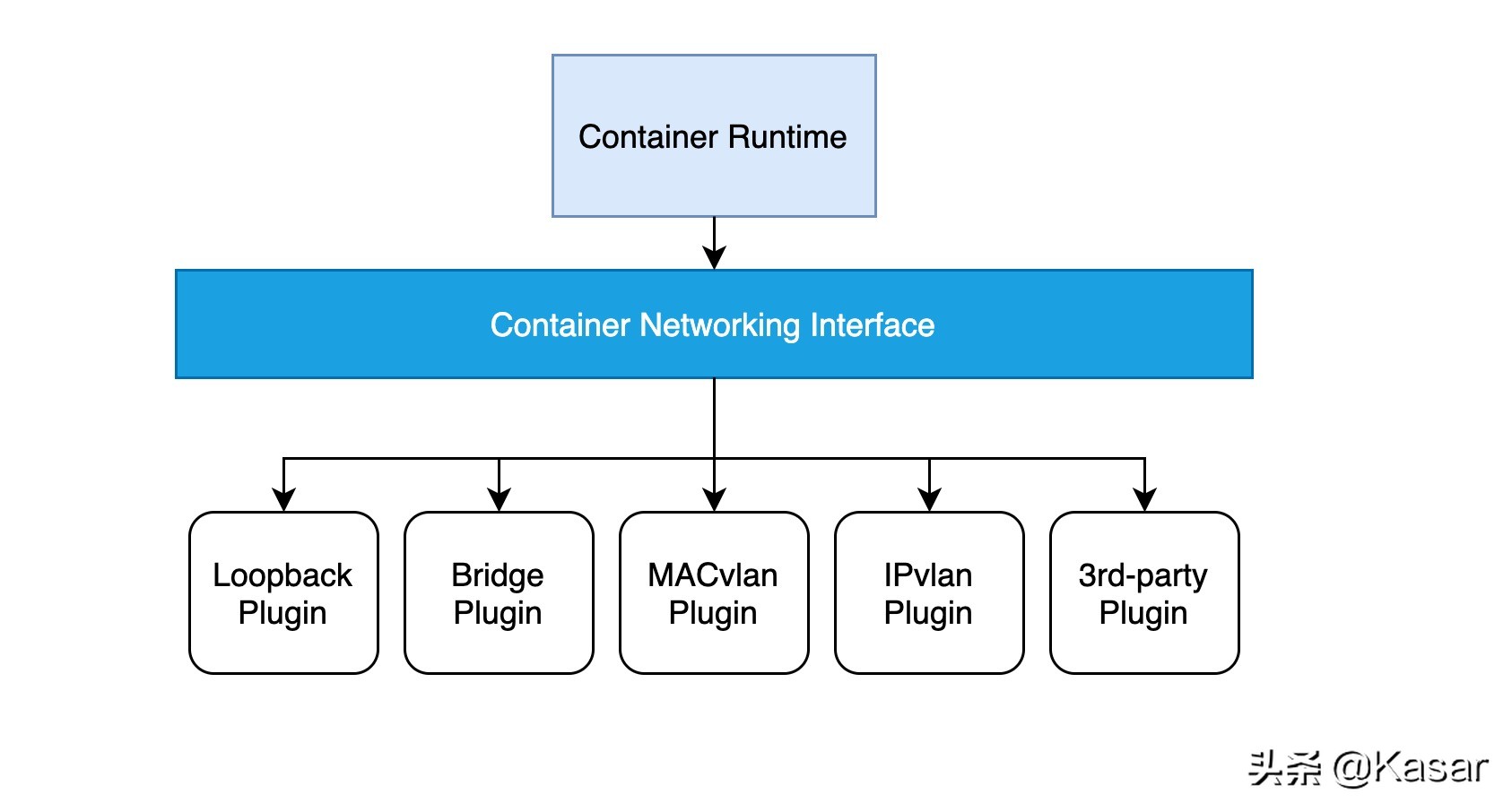
实现一个CNI网络插件只需要一个配置文件和一个可执行的文件:
- 配置文件描述插件的版本、名称、描述等基本信息
- 可执行文件会被上层的容器管理平台调用,一个CNI可执行文件自需要实现将容器加入到网络的ADD操作以及将容器从网络中删除的DEL操作(以及一个可选的VERSION查看版本操作)
Kubernetes使用CNI网络插件的基本工作流程:
- kubelet先创建pause容器生成对应的netns网络命名空间
- 根据配置调用具体的CNI插件,可以配置成CNI插件链来进行链式调用
- 当CNI插件被调用时,它根据环境变量以及命令行参数来获得网络命名空间netns、容器的网络设备等必要信息,然后执行ADD操作
- CNI插件给pause容器配置正确的网络,pod中其他的容器都是用pause容器的网络
如果不清楚什么是pause容器,它在pod中处于什么样的位置,请查看之前的笔记:https://morven.life/notes/from-container-to-pod/
pod网络模型
要了解kubernetes网络模型的实现原理,我们就要从单个pod入手,事实上,一旦熟悉了单个pod的网络模型,就会发现kubernetes网络模型基本遵循和容器网络模型一样的原理。
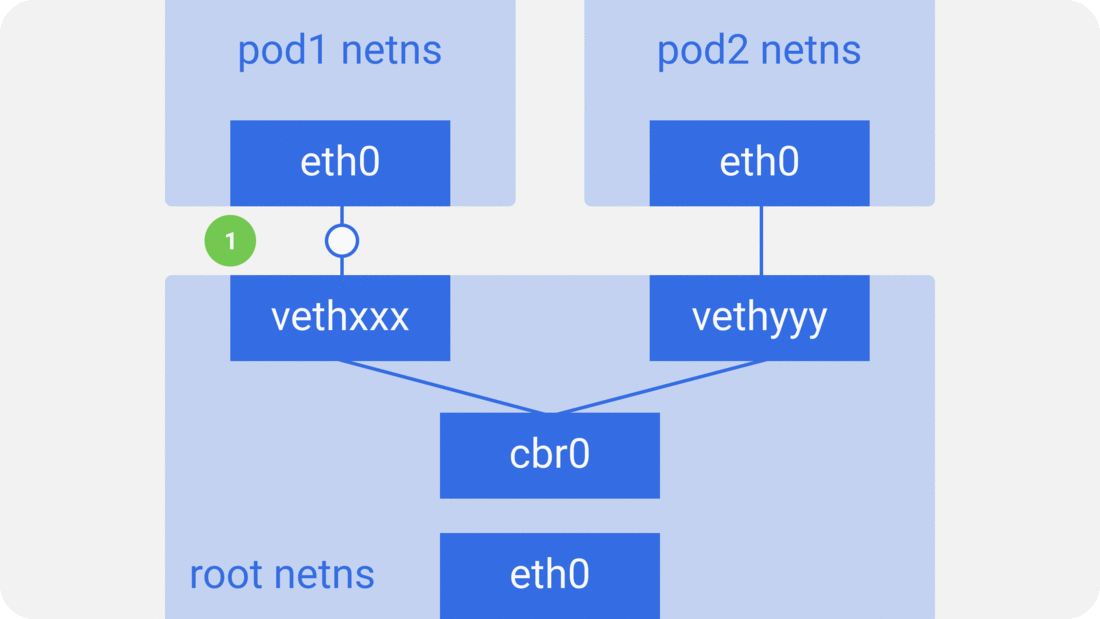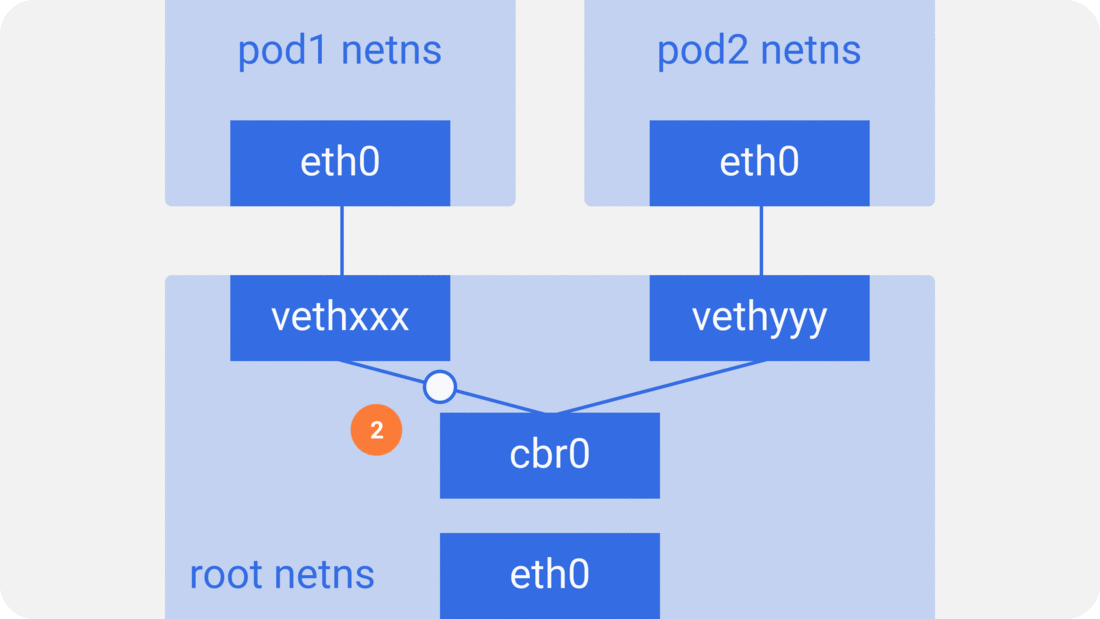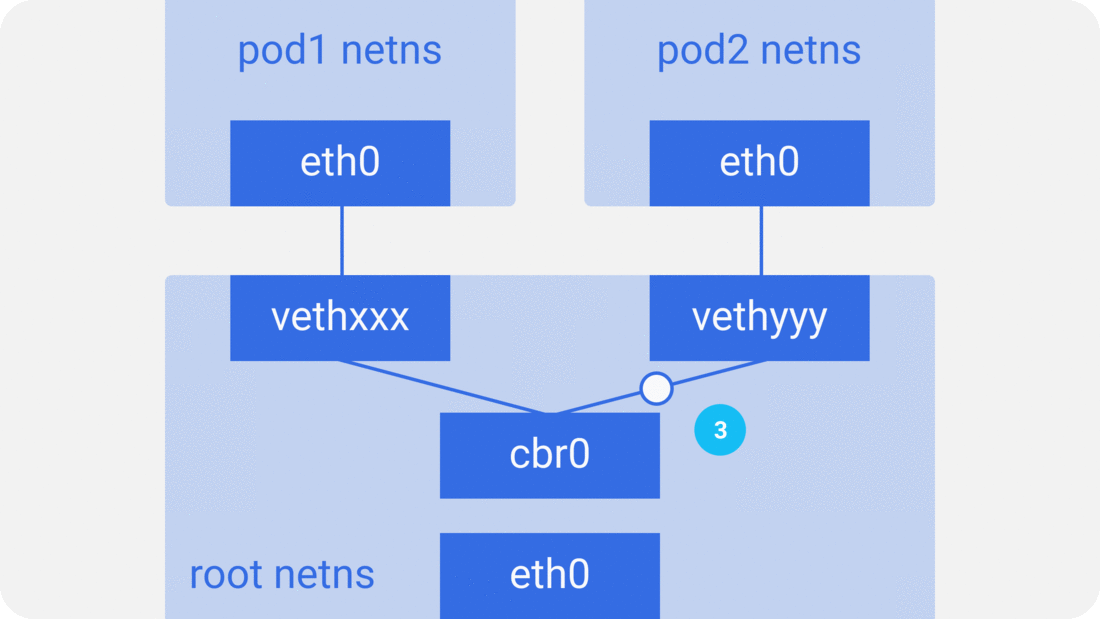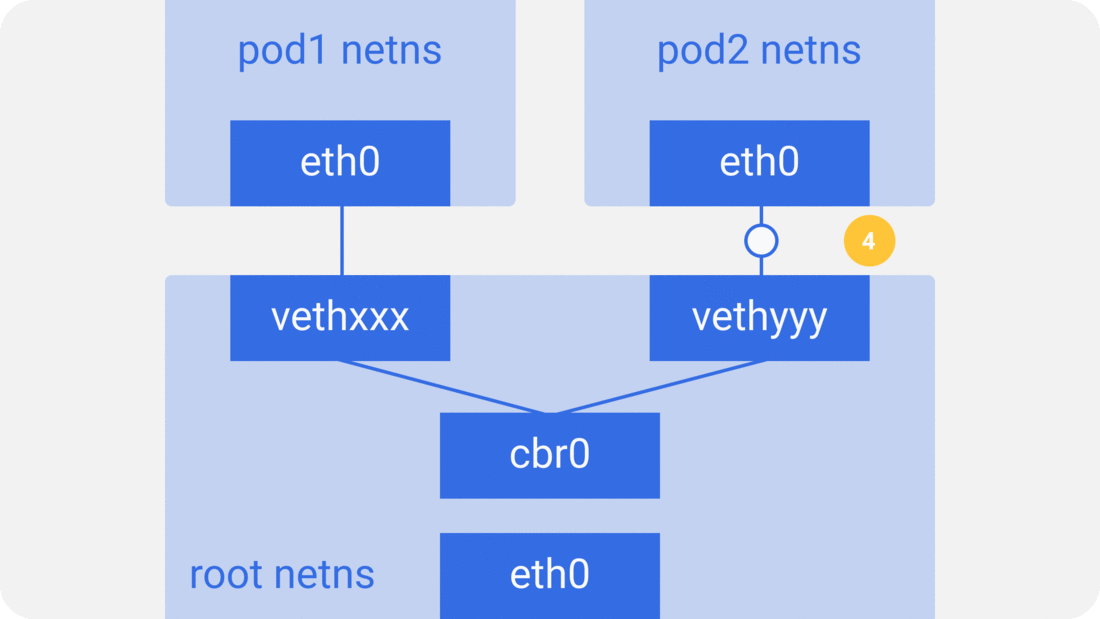
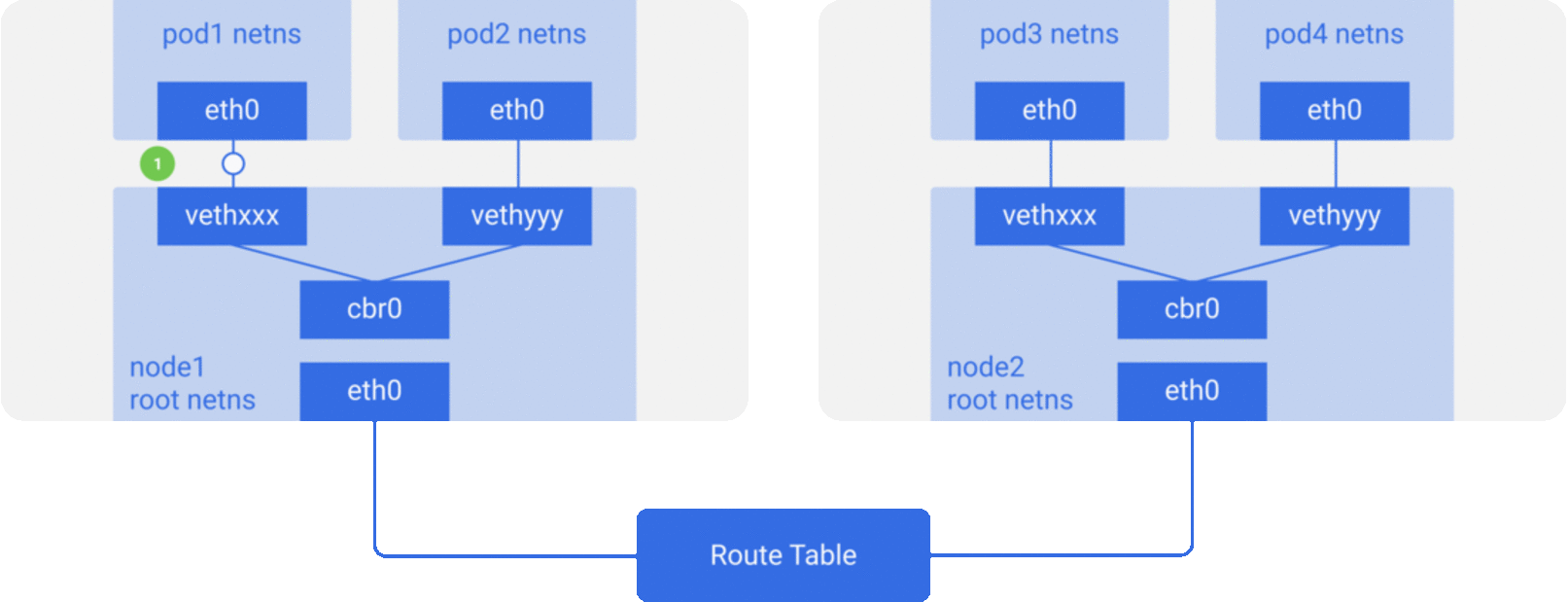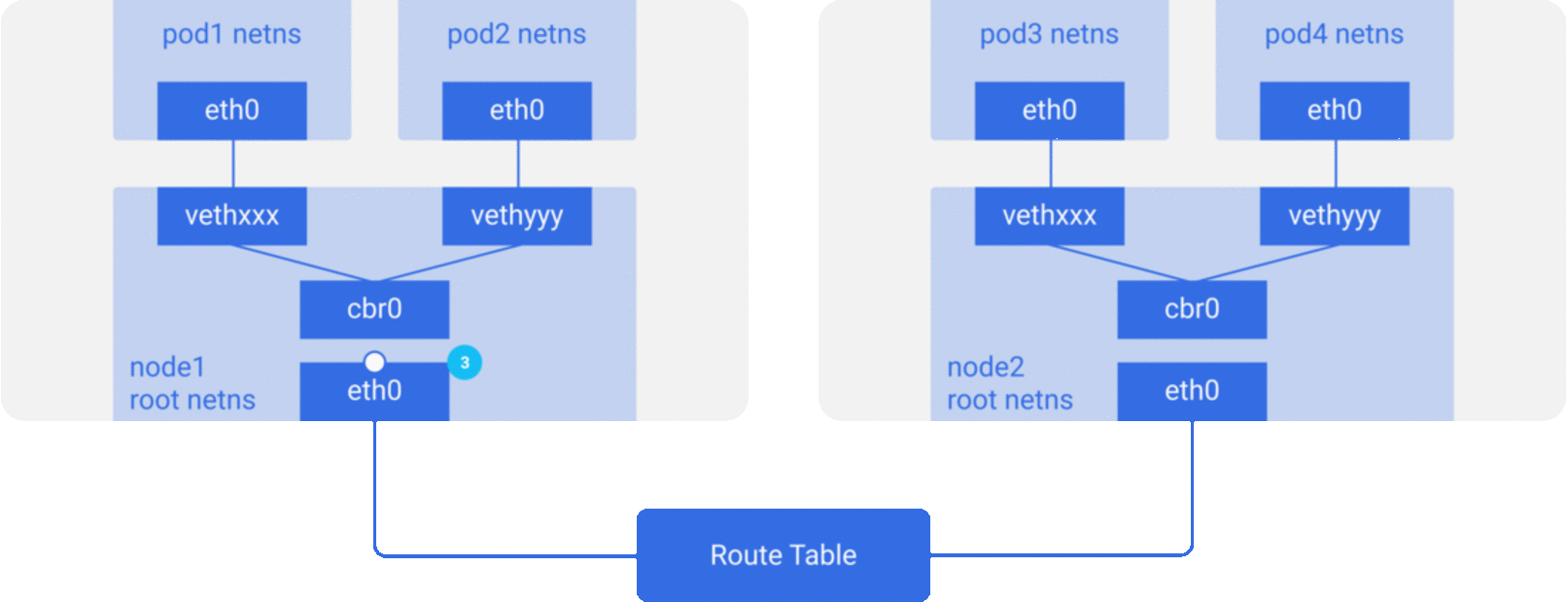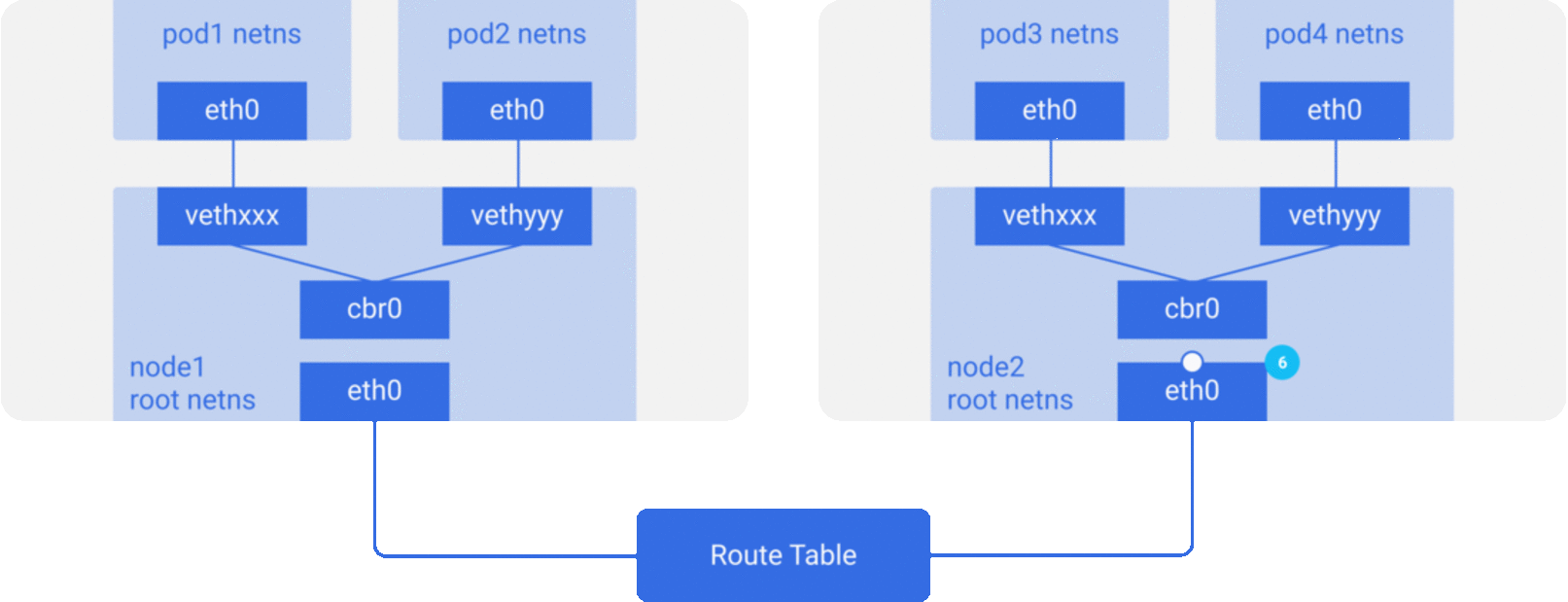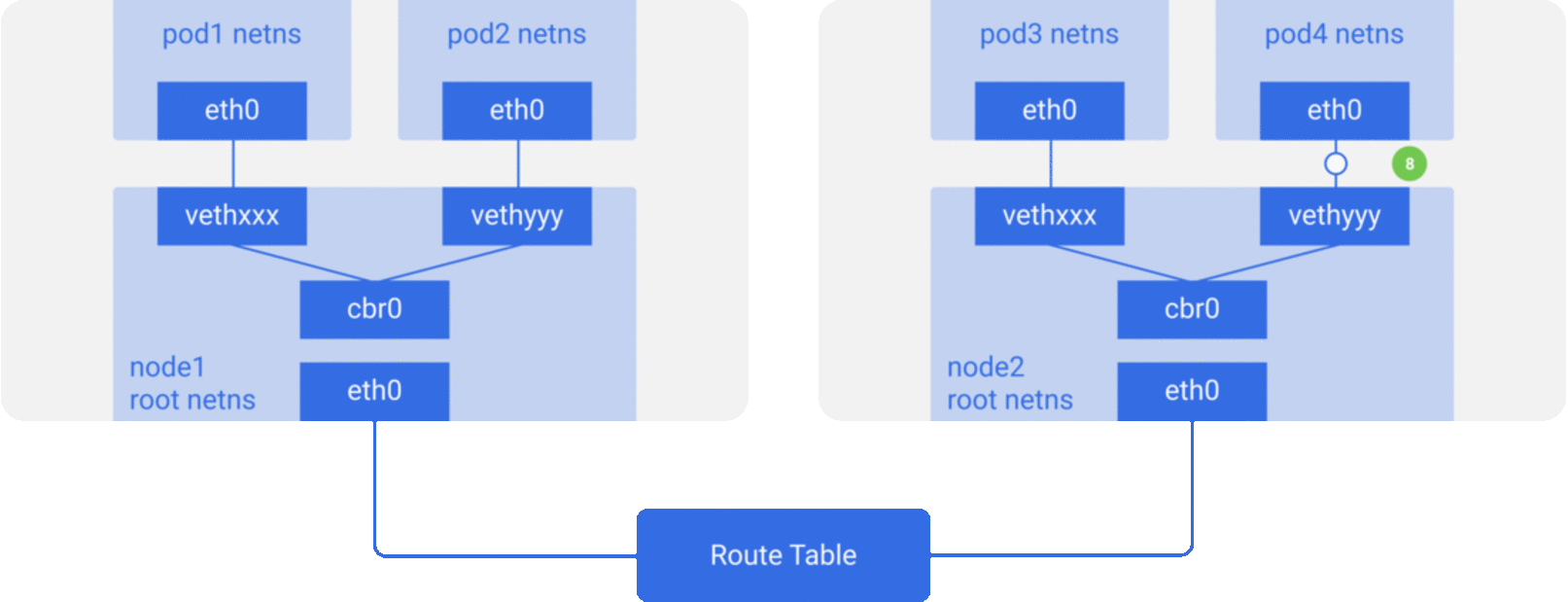
通过前面的笔记从docker容器到pod,我们知道pod启动的时候先创建pause容器生成对应的netns网络命名空间,然后其他容器共享pause容器创建的网络命名空间。而对于单个容器的网络模型我们之前也介绍过,主要就是通过docker0网桥设备与veth设备对连接不同的容器网络命名空间,由此,我们可以得到如下图所示的单个pod网络模型的创建过程:
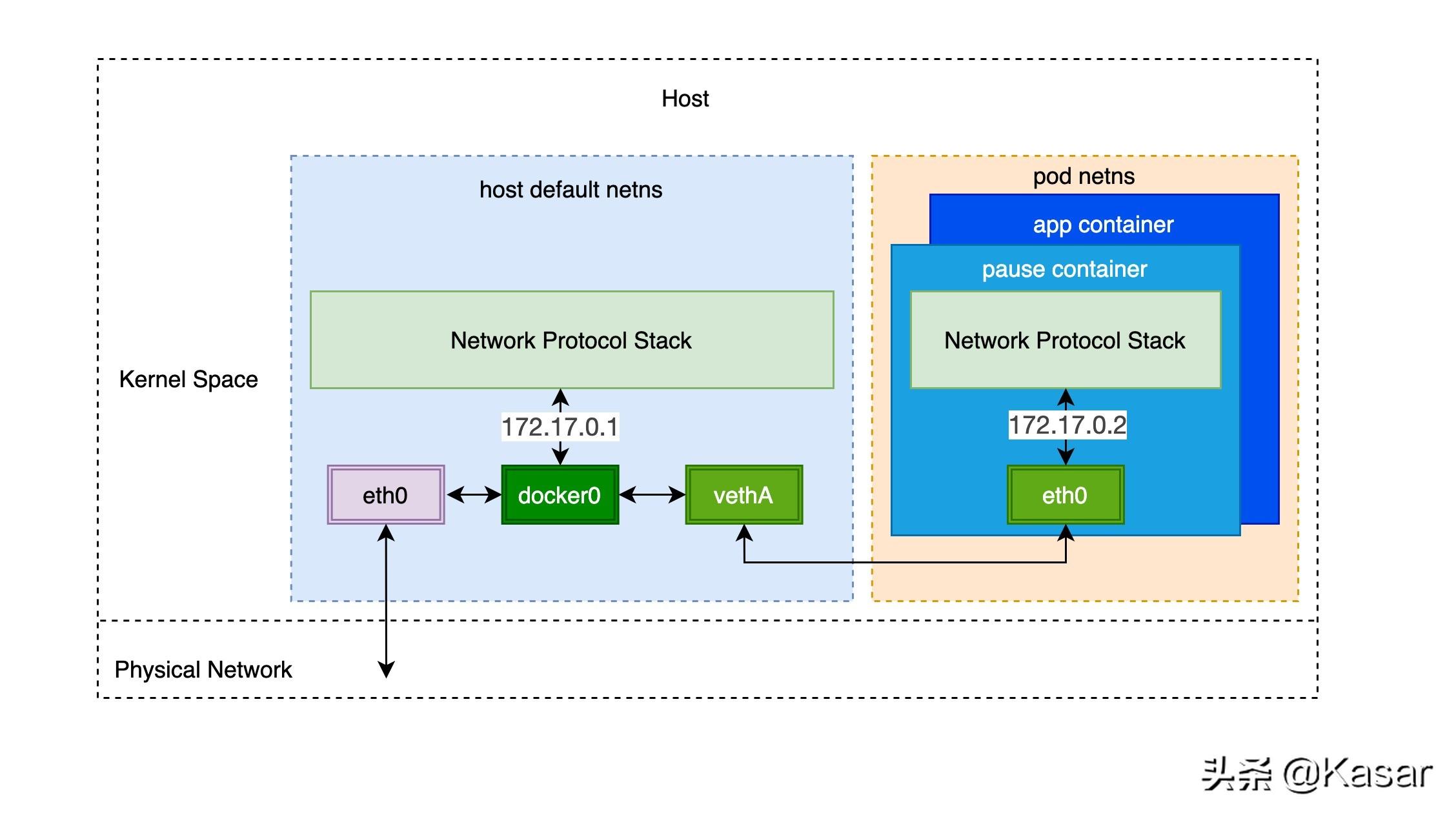
可以看到,同一个pod里面的其他容器共享pause容器创建的网络命名空间,也就是说,所有的容器共享相同的网络设备,路由表设置,服务端口等信息,仿佛是在同一台机器上运行的不同进程,所以这些容器之间可以直接通过localhost与对应的端口通信;对于集群外部的请求,则通过docker0网桥设备充当的网关,同时通过iptables做地址转换。我们会发现,这其实就是对当个容器的bridge网络模型的扩展。
主流kubernetes网络方案
上一小节我们知道单个pod的网络模型是容器网络模型的扩展,但是pod与pod之间的是怎么相互通信的呢?这其实与容器之间相互通信非常类似,也分为同一个主机上的pod之间与跨主机的pod之间两种。
如容器网络模型一样,对于统一主机上的pod之间,通过docker0网桥设备直接二层(数据链路层)网络上通过MAC地址直接通信:
而跨主机的pod之间的相互通信也主要有以下两个思路:
- 修改底层网络设备配置,加入容器网络IP地址的管理,修改路由器网关等,该方式主要和SDN(Software define networking)结合。
- 完全不修改底层网络设备配置,复用原有的underlay平面网络,解决容器跨主机通信,主要有如下两种方式:隧道传输(Overlay): 将容器的数据包封装到原主机网络的三层或者四层数据包中,然后使用主机网络的IP或者TCP/UDP传输到目标主机,目标主机拆包后再转发给目标容器。Overlay隧道传输常见方案包括Vxlan、ipip等,目前使用Overlay隧道传输技术的主流容器网络有Flannel等;
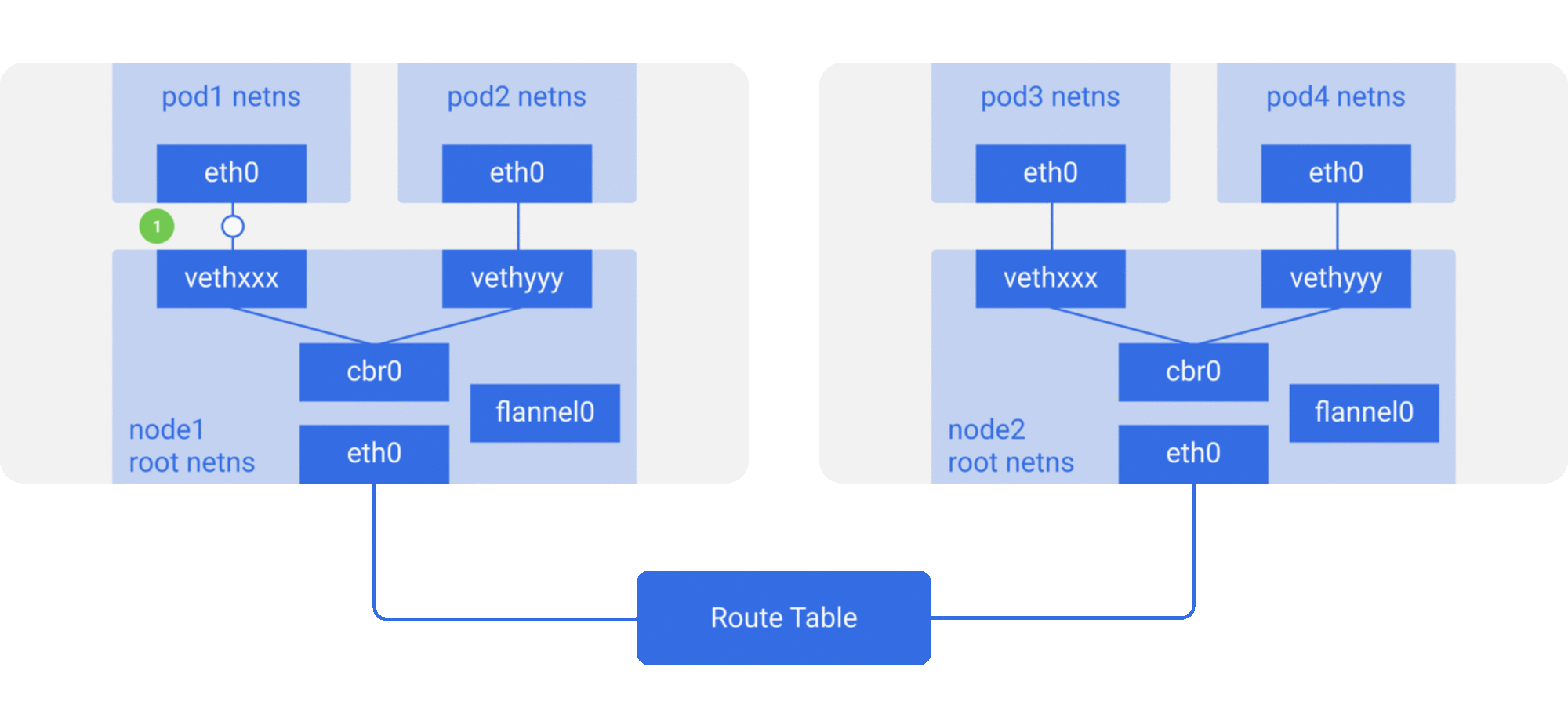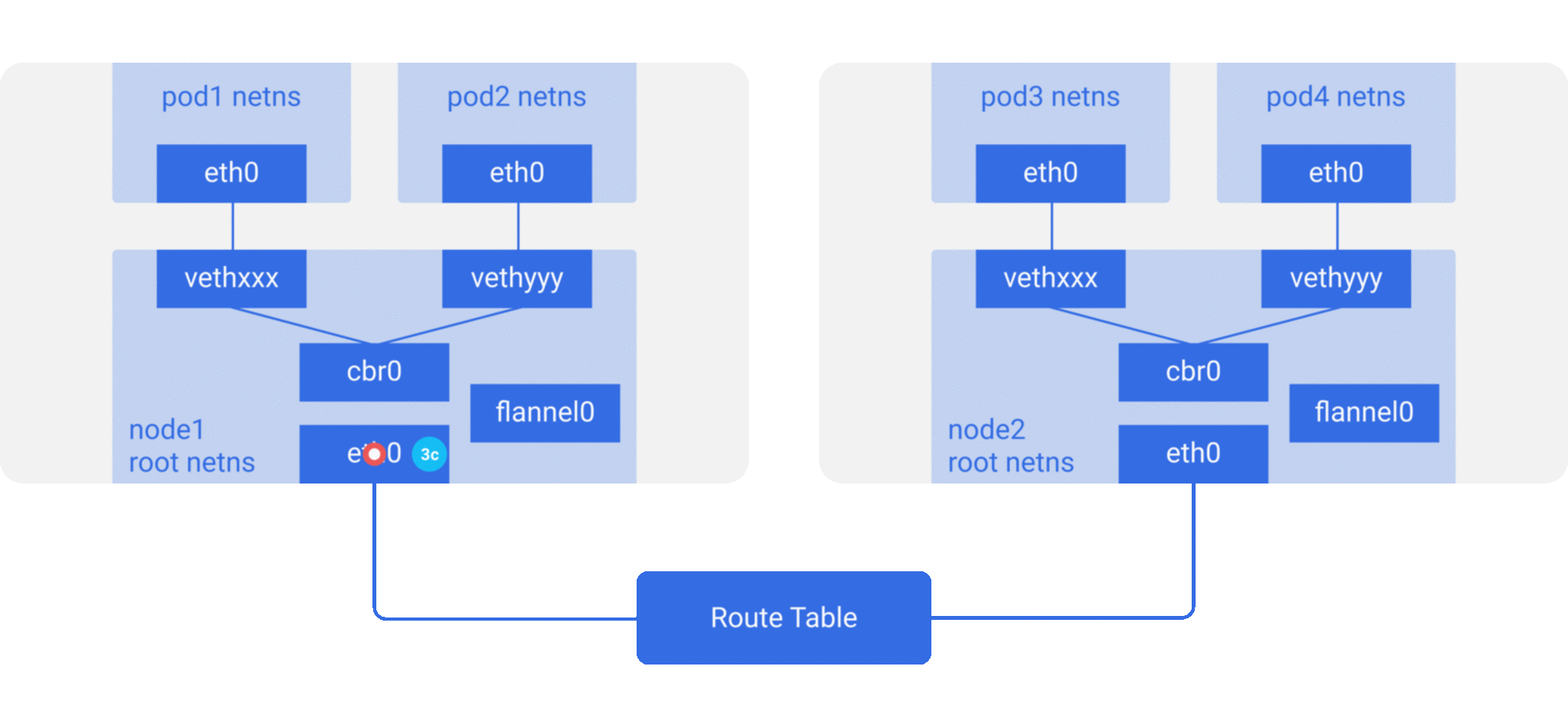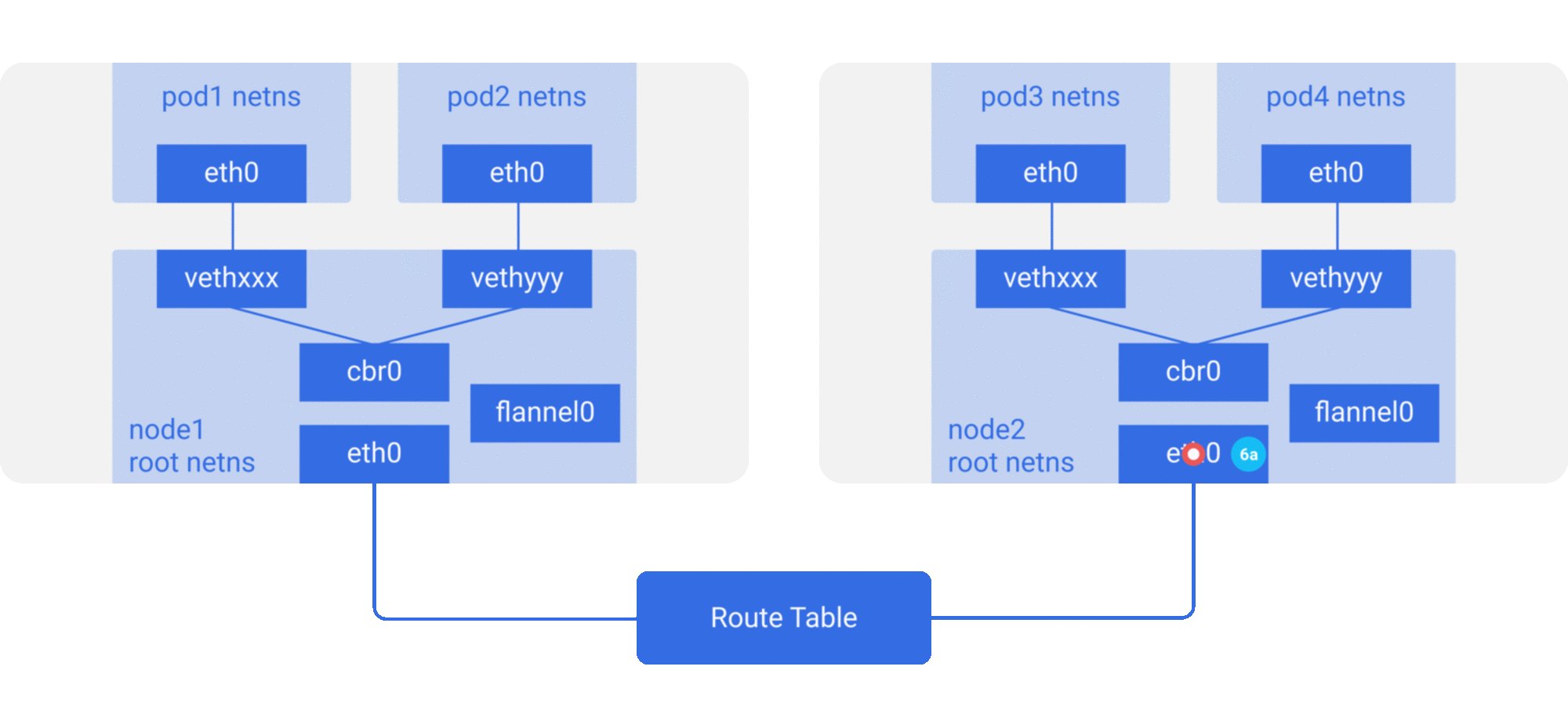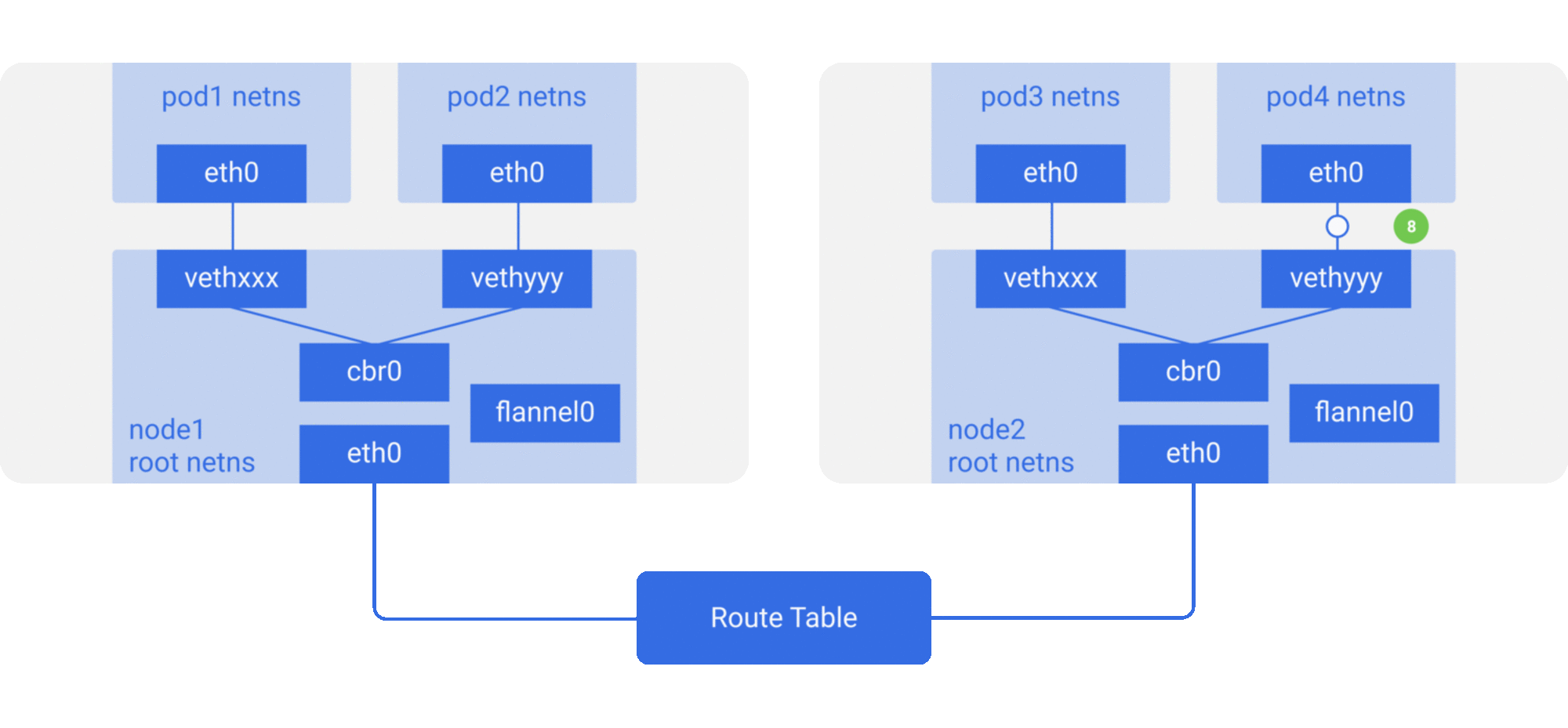
修改主机路由:把容器网络加到主机路由表中,把主机网络设备当作容器网关,通过路由规则转发到指定的主机,实现容器的三层互通。目前通过路由技术实现容器跨主机通信的网络如Flannel host-gw、Calico等;
下面简单介绍几种主流的方案:
- Flannel是目前使用最为普遍的方案,提供了多种网络backend,它支持多种数据路径,也适合于overlay/underlay等多种场景。对于overlay的数据包封装,可以使用用户态的UDP,内核态的Vxlan(性能相对较好),甚至在集群规模不大,且处于同一个二层域时可以采用host-gw的方式修改主机路由表;
- Weave工作模式与Flannel很相似的,它最早只提供了UDP(称为sleeve模式)的网络方式,后来又加上了fastpass方式(基于VxLAN),不过Weave消除了Flannel中用来存储网络地址的额外组件,自己集成了高可用的数据存储功能;
- Calico主要是采用了修改主机路由,节点之间采用BGP的协议去进行路由的同步。但是现实中的网络并不总是支持BGP路由的,因此Calico也支持内核中的IPIP模式,使用overlay的方式来传输数据;
下表是几种主流Kubernetes网络方案的对比:
- | A | Overlay-Network | Host-RouteTable | NetworkPolicy Support | Decentralized IP Allocation | | – | — | — | — | — | | Flannel | UDP/VXLAN | Host-GW | N | N | | Weave | UDP/VXLAN | N/A | Y | Y | | Calico | IPIP | BGP | Y | N |
策略控制(Network Policy)
Network Policy)是Kubernetes提供的基于策略的网络控制,用于隔离应用并提高安全性。它使用Kubernetes中常用的标签选择器模拟传统的分段网络,并通过策略控制它们之间的东西流量以及与外部交流的南北流量。
- Note: 确保使用的网络插件支持策略控制(Network Policy),比如Flannel就没有实现Network Policy;
下面的例子是配置一个典型的Network Policy的实例:
- apiVersion: networking.k8s.io/v1
- kind: NetworkPolicy
- metadata:
- name: test-network-policy
- namespace: default
- spec:
- podSelector:
- matchLabels:
- role: db
- policyTypes:
- - Ingress - Egress ingress:
- - from:
- - ipBlock:
- cidr: 172.17.0.0/16
- except:
- - 172.17.1.0/24
- - namespaceSelector:
- matchLabels:
- project: myproject
- - podSelector:
- matchLabels:
- role: frontend
- ports:
- - protocol: TCP
- port: 6379
- egress:
- - to:
- - ipBlock:
- cidr: 10.0.0.0/24
- ports:
- - protocol: TCP
- port: 5978
它使用标签选择器namespaceSelector与posSelector控制pod之间的流量,流量的行为模式主要由以下三个对象决定:
- 控制对象:通过spec.podSelector筛选
- 流量方向:ingress控制入pod流量,egress控制出pod流量
- 流量特征:对端-IP-协议-端口
通过使用Network Policy可以实现对进出流的精确控制,它采用各种选择器(标签或namespace),找到一组满足条件的pod,或者找到相当于通信的两端,然后通过流量的特征描述来决定它们之间是不是可以连通,可以理解为一个白名单的机制。