













在本系列文章中,我们将为读者分享关于内核代码模糊测试方面的见解。
简介
对于长期关注Linux内核开发或系统调用模糊测试的读者来说,很可能早就对trinity(地址:https://lwn.net/Articles/536173/)和syzkaller(地址:https://lwn.net/Articles/677764/)并不陌生了。近年来,安全研究人员已经利用这两个工具发现了许多内核漏洞。实际上,它们的工作原理非常简单:向内核随机抛出一些系统调用,以期某些调用会导致内核崩溃,或触发内核代码中可检测的漏洞(例如缓冲区溢出漏洞)。
尽管这些Fuzzer能够对系统调用自身(以及通过系统调用可访问的代码)进行有效的模糊测试;但是,对于在用户空间和内核之间的边界上发生的事情,这两款工具却鞭长莫及。实际上,这个边界处发生的事情比我们想象的更为复杂:这里的代码是用汇编语言编写的,在内核可以安全地开始执行其C代码之前,必须对各种体系结构状态(CPU状态)进行安全检查,或者说是“消毒”。
本文将同读者一起,探索如何为x86平台上的Linux内核入口代码编写Fuzzer工具。
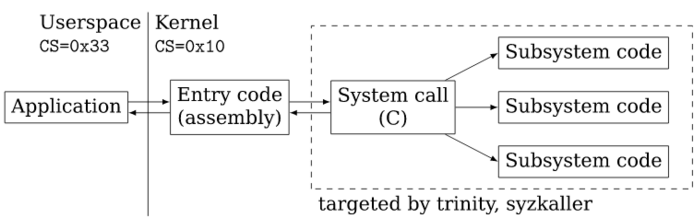
在继续之前,不妨先简单了解一下64位内核涉及的主要两个文件:
· entry_64.S:64位进程的入口代码。
· entry_64_compat.S:32位进程的入口代码。
总的来说,入口代码大约有1700行汇编代码(其中包括注释),所以,阅读这些代码的工作量并不算小,同时,这也只是整个内核代码中很小的一部分。
memset()示例
首先,我想给出一个从用户空间进入内核时,内核需要进行验证的CPU状态的具体例子。
在x86平台上,memset()通常是由rep stos指令实现的,因为在连续的字节范围内进行写操作方面,该指令已经被CPU/微码进行了高度的优化。从概念上讲,这是一个硬件循环,它重复(rep)一个存储操作(stos)若干次;目标地址由%RDI寄存器指定,迭代次数由%RCX寄存器给出。例如,您可以使用内联汇编实现memset(),具体如下所示:
- static inline void memset(void *dest, int value, size_t count)
- {
- asm volatile ("rep stosb" // 4
- : "+D" (dest), "+c" (count) // 1, 2
- : "a" (value) // 3
- : "cc", "memory"); // 5
- }
对于上述内联汇编代码来说,其作用就是告诉GCC:
1. 将变量dest保存到%rdi寄存器中(+表示该值可能会被内联汇编代码所修改);
2. 将变量count保存到%rcx寄存器中;
3. 将变量value保存到%eax寄存器中(无论我们将其放入%rax、%eax、%ax还是%al寄存器中,这都是无关紧要的,因为rep stosb指令只使用与%al寄存器中的值相对应的低位字节);
4. 将rep stosb指令插入到汇编代码中;
5. 重载任何可能依赖于条件码(“cc”,即x86平台上的%rflags寄存器)或内存的值。
作为参考,你也可以考察一下memset()在x86平台上的主流实现代码。
重要的是,在%rflags寄存器中含有一个很少使用的位,叫做DF位(即方向标志位)。这个标志位决定了每写入一个字节后,rep stos会令%rdi的值递增或递减。当DF位被设为0时,受影响的内存范围是从%rdi到(%rdi + %rcx);而当DF位被设为1时,受影响的内存范围是从(%rdi - %rcx)到%rdi!由于它对memset()的最终结果有重大的影响,所以,我们最好确保DF位总是被设为0。
实际上,按照x86_64 SysV ABI的要求,在进入函数以及从函数返回时,DF位必须始终为0(具体见第15页):
“必须在进入函数以及从函数返回时清除%rFLAGS寄存器中的方向标志DF(将方向设置为“forward”)。其他用户标志在标准调用序列中没有指定的角色,并且在不同的调用中不予保留。”
实际上,这是内核在内部高度依赖的一种约定;如果在调用memset()时以某种方式将DF标志设置为1,它将错误地覆盖某些内存。因此,内核进入代码的任务之一,就是确保在进入任何内核C代码之前,DF标志始终为0。我们可以用一条指令cld(即清除方向标志指令)来实现这一点,内核的许多入口路径就是这么做的,具体请参考paranoid_entry()或error_entry()的实现代码。
fuzzer
如您所见,哪怕是CPU状态的一个标志位,都对内核有着巨大的影响。接下来,我们将枚举入口代码需要处理的所有CPU状态变量:
· 标志寄存器 (%rflags)
· 堆栈指针 (%rsp)
· 段寄存器 (%cs, %fs, %gs)
· 调试寄存器 (%dr0到%dr3, %dr7)
到目前为止,我们一直回避的问题是,从用户空间进入内核有许多不同的方式,而不仅仅是系统调用(也不仅仅是系统调用的一种机制)。这些方式包括:
· int指令
· sysenter指令
· syscall指令
· INT3/INTO/INT1指令
· 被零除
· 调试异常
· 断点异常
· 溢出异常
· 操作码无效
· 一般保护故障
· 页面错误
· 浮点异常
· 外部硬件中断
· 不可屏蔽中断
Fuzzer的目标应该是测试CPU状态和用户空间/内核转换的所有可能组合。在理想的情况下,我们会进行穷举搜索,但是如果您考虑寄存器值和入口方法的所有可能组合,搜索空间就太大了。因此,我们将通过两个主要的策略来提高我们发现bug的机会。
1. 关注那些我们怀疑更有可能导致有趣/不寻常事情发生的值/案例。为此,需要查看x86文档(维基百科、英特尔手册等)以及入口代码本身。例如,入口代码记录了几个处理器勘误表案例,我们可以直接使用它们来确定已知的边缘案例。
2. 压缩我们认为没有影响的那些类型的值。例如,在挑选要加载到寄存器的随机值时,重要的是要尝试不同类型的指针(例如,内核空间、用户空间、非规范、映射、非映射等类型的指针),而不是尝试所有可能的值。
值得一提的是,内核已经为x86代码提供了一个优秀回归测试套件,它位于tools/testing/selftests/x86/目录下,主要开发者为Andy Lutomirski。它提供了进入/离开内核的各种方法的测试用例,我们可以从中汲取灵感。
高层架构
我们这里要开发的fuzzer,实际上是一个供内核运行的用户空间程序,用以完成相应的模糊测试工作。由于我们需要非常精确地控制一些用于触发向内核过渡的指令,所以,我们实际上不会直接用C语言来编写这些代码;相反,我们将在运行时动态地生成x86机器代码,然后执行它。为了简单起见,也为了避免在设置好所需的CPU状态后恢复到一个干净的状态(如果可以的话),我们将在一个子进程中执行生成的机器代码,并且能够在进入内核后将其丢弃。
下面,我们从一个基本的fork循环开始入手。
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- #include
- static void *mem;
- static void emit_code();
- typedef void (*generated_code_fn)(void);
- int main(int argc, char *argv[])
- {
- mem = mmap(NULL, PAGE_SIZE,
- // prot
- PROT_READ | PROT_WRITE | PROT_EXEC,
- // flags
- MAP_PRIVATE | MAP_ANONYMOUS | MAP_32BIT,
- // fd, offset
- -1, 0);
- if (mem == MAP_FAILED)
- error(EXIT_FAILURE, errno, "mmap()");
- while (1) {
- emit_code();
- pid_t child = fork();
- if (child == -1)
- error(EXIT_FAILURE, errno, "fork()");
- if (child == 0) {
- // we're the child; call our newly generated function
- ((generated_code_fn) mem)();
- exit(EXIT_SUCCESS);
- }
- // we're the parent; wait for the child to exit
- while (1) {
- int status;
- if (waitpid(child, &status, 0) == -1) {
- if (errno == EINTR)
- continue;
- error(EXIT_FAILURE, errno, "waitpid()");
- }
- break;
- }
- }
- return 0;
- }
然后,我们还将实现一个非常简单的emit_code(),到目前为止,只创建了一个包含单个retq指令的函数:
- static void emit_code()
- {
- uint8_t *out = (uint8_t *) mem;
- // retq
- *out++ = 0xc3;
- }
如果您仔细阅读代码,很可能会感到奇怪:为什么要使用MAP_32BIT标志创建映射呢?这是因为我们希望fuzzer在32位兼容模式下运行时进入内核,所以,首先需要能在有效的32位地址下运行。
进行系统调用
在x86平台上,系统调用的历史有点混乱。首先,存在这样一个事实,即系统调用最初是在32位系统上发展起来的,当时使用的是相对较慢的int指令。后来,英特尔和AMD公司分别开发了自己的快速系统调用机制(分别使用全新且互不兼容的sysenter和syscall指令)。更糟的是,64位系统需要同时处理32位进程(使用任何32位系统调用机制)、64位进程以及(可能的)第三种操作模式即x32,其中代码像像通常那样是64位的(并且可以访问64位寄存器),然而,指针却是32位的——之所以这么做,据说是为了节省内存。由于它们在进入内核模式时保存/修改的CPU状态各不相同,因此,这些不同的系统调用机制中的大多数在内核的入口码中采用的路径也是各不相同的。这也是入口代码很难理解的原因之一!
有关在x86上进行系统调用的更深入的介绍,可以参阅LWN网站上的优秀文章,比如:
· Anatomy of a system call, part 1
· Anatomy of a system call, part 2
熟悉系统调用的一个好方法是,亲自动手通过GNU汇编器来制作汇编代码片段的原型,然后供fuzzer使用。例如,像下面那样,对内核执行一次read(STDIN_FILENO, NULL, 0)调用:
- .text
- .global main
- main:
- movl $0, %eax # SYS_read/__NR_read
- movl $0, %edi # fd = STDIN_FILENO
- movl $0, %esi # buf = NULL
- movl $0, %edx # count = 0
- syscall
- movl $0, %eax
- retq
从这段代码中可以看到,当使用syscall指令时,系统调用号本身通过%rax寄存器传递,而参数则通过%rdi、%rsi、%rdx等寄存器进行传递。据我所知,Linux x86 SysCall ABI在入口代码本身的entry_syscall_64()中是有“正式”记录的(我们在这里使用的是%eXX寄存器,而不是%rXX寄存器,因为这里的机器代码比较短;将%eXX设置为0时,将清除%rXX的高32位)。
我们可以使用gcc read.S命令来构建上述代码(假设上述汇编代码保存在名为read.S的文件中),并可以使用strace检查它是否正确:
- $ strace ./a.out
- execve("./a.out", ["./a.out"], [/* 53 vars */]) = 0
- [...]
- read(0, NULL, 0) = 0
- exit_group(0) = ?
- +++ exited with 0 +++
要获得汇编后机器代码的字节内容,我们可以先使用gcc-c read.s进行编译,然后使用objdump -d read.o获取相应的内容:
- 0000000000000000
- 0: b8 00 00 00 00 mov $0x0,%eax
- 5: bf 00 00 00 00 mov $0x0,%edi
- a: be 00 00 00 00 mov $0x0,%esi
- f: ba 00 00 00 00 mov $0x0,%edx
- 14: 0f 05 syscall
- 16: b8 00 00 00 00 mov $0x0,%eax
- 1b: c3 retq
要将这个字节序列添加到我们的JIT汇编函数中,我们可以使用下列代码:
- // mov $0, %eax
- *out++ = 0xb8;
- *out++ = 0x00;
- *out++ = 0x00;
- *out++ = 0x00;
- *out++ = 0x00;
- [...]
- // syscall
- *out++ = 0x0f;
- *out++ = 0x05;
重新回到memset()和方向标志位
现在,对于上面的memset()示例来说,编写测试所需的大部分代码都已经准备就绪了。为了设置df位,我们可以在进行系统调用之前执行std指令(该指令用于设置方向标志):
- // std
- *out++ = 0xfd;
既然我们要写一个fuzzer,那么,自然需要给这个标志位随机赋值。如果我们使用的编程语言是C++的话,可以通过如下所示的代码来初始化PRNG:
- #include
- static std::default_random_engine rnd;
- int main(...)
- {
- std::random_device rdev;
- rnd = std::default_random_engine(rdev());
- ...
- }
然后,我们可以在进行系统调用之前,使用类似下面的方式来设置(或清除)该标志位:
- switch (std::uniform_int_distribution
- case 0:
- // cld
- *out++ = 0xfc;
- break;
- case 1:
- // std
- *out++ = 0xfd;
- break;
- }
同样,这些字节只是用于手工拼装一个短测试程序,然后查看objdump的输出结果。
注意:在子进程中生成随机数的时候,我们要格外小心;因为我们不希望所有的子进程都生成相同的数字!这就是为什么我们实际上在父进程中生成代码,并在子进程中简单地执行它们的原因。
本文翻译自:https://blogs.oracle.com/linux/fuzzing-the-linux-kernel-x86-entry-code%2C-part-1-of-3如若转载,请注明原文地址:












