













本文转载自微信公众号「相遇Linux」,作者JeffXie。转载本文请联系相遇Linux公众号。
Linux块设备多队列机制在Linux3.13中引入,刚开始引入多队列时是多队列和单队列并存。
想研究多队列,当然还是以原始patch的方式研究最靠谱了。
patch原始代码:
git://git.kernel.org/pub/scm/linux/kernel/git/axboe/linux-block.git
分支:linux-block/v3.10-blk-mq
首先过目一下多队列架构:
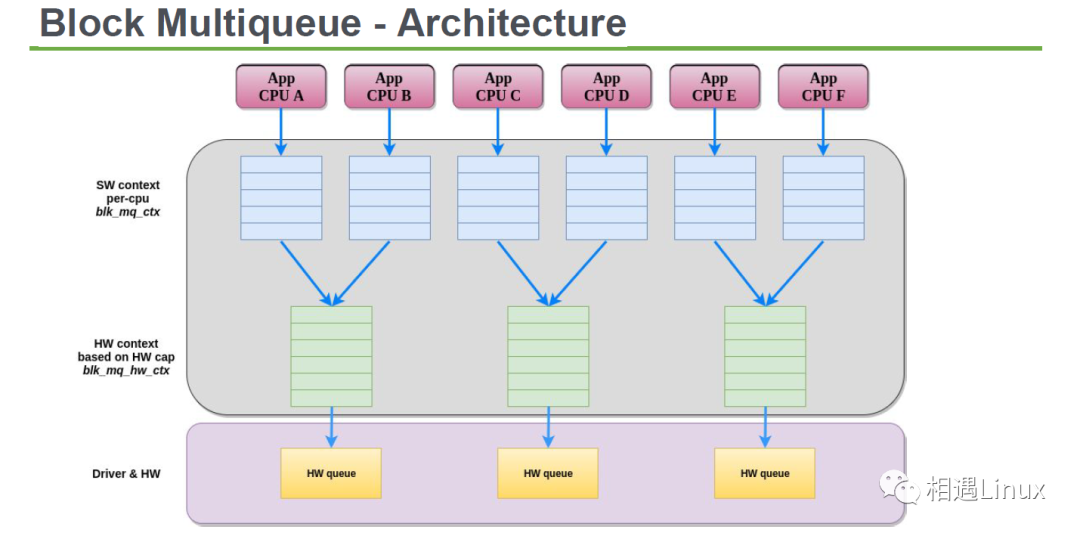
以读IO为例,单队列和多队列相同的执行路径:
- read_pages()
- {
- ...
- blk_start_plug() /* 进程准备蓄流 */
- mapping->a_ops->readpages() /* 蓄流 */
- blk_finish_plug() /* 进程开始泄流 */
- ...
- }
- io_schedule() 进程蓄流之后等待io完成
- (在blk_mq_make_request()函数中request的数目大于或者等于16
- request_count >= BLK_MAX_REQUEST_COUNT
- 不需要调用io_schedule(),直接泄流到块设备驱动)
mapping->a_ops->readpages() 会一直调用q->make_request_fn()
- generic_make_request()
- q->make_request_fn() 调用blk_queue_bio()或者
- 多队列blk_queue_make_request()
- __elv_add_request()
为什么引入多队列:多队列相对与单队列来说,每个cpu上都有一个软队列(使用blk_mq_ctx结构表示)避免插入request的时候使用spinlock锁,而且如今的高速存储设备,比如支持nvme的ssd(小弟刚买了一块,速度确实快),访问延迟非常小,而且本身硬件就支持多队列,(引入的多队列使用每个硬件队列
单队列插入request时会使用request_queue上的全局spinlock锁
- blk_queue_bio()
- {
- ...
- spin_lock_irq(q->queue_lock);
- elv_merge()
- spin_lock_irq(q->queue_lock);
- ...
- }
单队列泄流到块设备驱动时也是使用request_queue上的全局spinlock锁:
- struct request_queue *blk_alloc_queue_node()
- INIT_DELAYED_WORK(&q->delay_work, blk_delay_work);
- blk_delay_work()
- __blk_run_queue()
- q->request_fn(q);
__blk_run_queue()函数必须在队列锁中,也就是spin_lock_irq(q->queue_lock);
- 281 * __blk_run_queue - run a single device queue
- 282 * @q: The queue to run
- 283 *
- 284 * Description:
- 285 * See @blk_run_queue. This variant must be called with the queue lock
- 286 * held and interrupts disabled.
- 287 */
- 288 void __blk_run_queue(struct request_queue *q)
- 289 {
- 290 if (unlikely(blk_queue_stopped(q)))
- 291 return;
- 292
- 293 __blk_run_queue_uncond(q);
- 294 }
多队列插入request时没有使用spinlock锁:
- blk_mq_insert_requests()
- __blk_mq_insert_request()
- struct blk_mq_ctx *ctx = rq->mq_ctx; (每cpu上的blk_mq_ctx)
- list_add_tail(&rq->queuelist, &ctx->rq_list)
多队列泄流到块设备驱动也没有使用spinlock锁:
- static int blk_mq_init_hw_queues()
- INIT_DELAYED_WORK(&hctx->delayed_work, blk_mq_work_fn);
- 708 static void blk_mq_work_fn(struct work_struct *work)
- 709 {
- 710 struct blk_mq_hw_ctx *hctx;
- 711
- 712 hctx = container_of(work, struct blk_mq_hw_ctx, delayed_work.work);
- 713 __blk_mq_run_hw_queue(hctx);
- 714 }
- __blk_mq_run_hw_queue()
- 没有spinlock锁
- q->mq_ops->queue_rq(hctx, rq); 执行多队列上的->queue_rq()回调函数
从下图可以看出系统使用多队列之后的性能提升:
(我自己没测试过性能,凭客观想象应该与下列图相符:) )



















