












您可以整天训练有监督的机器学习模型,但是除非您评估其性能,否则您永远无法知道模型是否有用。这个详细的讨论回顾了您必须考虑的各种性能指标,并对它们的含义和工作方式提供了直观的解释。
为什么需要评估?
让我从一个非常简单的例子开始。
罗宾和山姆都开始为工科大学准备入学考试。他们俩共享一个房间,并在解决数字问题时付出了相同的努力。他们俩全年学习了几乎相同的时间,并参加了期末考试。令人惊讶的是,罗宾清除了,但萨姆没有清除。当被问到时,我们知道他们的准备策略有一个区别,即“测试系列”。罗宾加入了一个测试系列,他过去通过参加那些考试来测试他的知识和理解力,然后进一步评估他落后的地方。但是山姆很有信心,他只是不断地训练自己。
以相同的方式,如上所述,可以使用许多参数和新技术对机器学习模型进行广泛的训练,但是只要您跳过它的评估,就不能相信它。
混淆矩阵
混淆矩阵 是一个模型的预测和数据点的实际类别标签之间的相关性的矩阵。
假设您正在建立一个模型来检测一个人是否患有糖尿病。进行训练测试拆分后,您获得了长度为100的测试集,其中70个数据点标记为正(1),而30个数据点标记为负(0)。现在,让我为您的测试预测绘制矩阵:
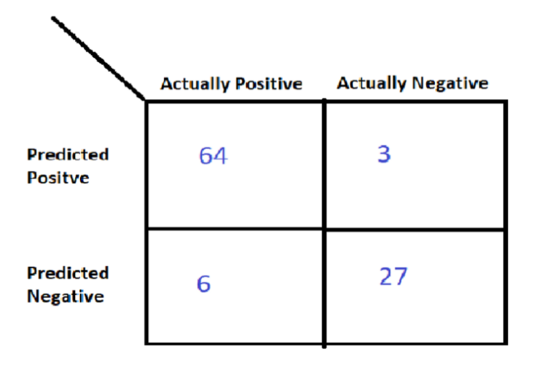
在70个实际的阳性数据点中,您的模型预测64个点为正,6个点为负。在30个实际负点中,它预测3个正点和27个负点。
注意: 在“ 真肯定”,“真否定”,“假肯定”和“假否定”表示法中 ,请注意,第二项(“正”或“负”)表示您的预测,而第一项则表示您预测的是对还是错。
基于上面的矩阵,我们可以定义一些非常重要的比率:
TPR(真正率)=(真正/实际正)
TNR(真负利率)=(真负/实际负)
FPR(误报率)=(误报/实际负)
FNR(假负率)=(假负/实际正数)
对于我们的糖尿病检测模型,我们可以计算以下比率:
TPR = 91.4%
TNR = 90%
FPR = 10%
FNR = 8.6%
如果您希望模型很聪明,那么模型必须正确预测。这意味着您的 “正肯定” 和 “负否定” 应尽可能高 ,同时,您需要将错误 肯定 和 错误否定 应尽可能少的 错误降至最低 。 同样在比率方面,您的 TPR和TNR 应该很高, 而 FPR和FNR 应该非常低 ,
智能模型: TPR↑,TNR↑,FPR↓,FNR↓
愚蠢的模型: TPR,TNR,FPR,FNR的任何其他组合
可能有人争辩说,不可能平等地照顾所有四个比率,因为最终没有一种模型是完美的。那我们该怎么办?
是的,它是真的。因此,这就是为什么我们要建立模型并牢记领域的原因。在某些领域要求我们将特定比率作为主要优先事项,即使以其他比率较差为代价。例如,在癌症诊断中,我们不能不惜一切代价错过任何阳性患者。因此,我们应该将TPR保持在最大值,将FNR保持在接近0的水平。即使我们预测有任何健康的患者被诊断出,也仍然可以,因为他可以进行进一步检查。
准确性
准确度是其字面意思,表示模型的准确度。
准确性=正确的预测/总预测
通过使用混淆矩阵,精度=(TP + TN)/(TP + TN + FP + FN)
准确性是我们可以使用的最简单的性能指标之一。但是让我警告您,准确性有时会导致您对模型产生错误的幻想,因此您应该首先了解所使用的数据集和算法,然后才决定是否使用准确性。
在讨论准确性的失败案例之前,让我为您介绍两种类型的数据集:
-
平衡的: 一个数据集,包含所有标签/类别几乎相等的条目。例如,在1000个数据点中,600个为正,400个为负。
-
不平衡: 一种数据集,其中包含偏向特定标签/类别的条目的分布。例如,在1000个条目中,有990个为正面类别,有10个为负面类别。
非常重要:处理不平衡的测试集时,切勿使用准确性作为度量。
为什么?
假设您有一个不平衡的测试集,其中包含 990(+ ve) 和 10(-ve) 的1000个条目 。最终,您以某种方式最终创建了一个糟糕的模型,该模型总是会因列车不平衡而始终预测“ + ve”。现在,当您预测测试集标签时,它将始终预测为“ + ve”。因此,从1000个测试设定点中,您可以获得1000个“ + ve”预测。然后你的准确性就会来
990/1000 = 99%
哇!惊人!您很高兴看到如此出色的准确性得分。
但是,您应该知道您的模型确实很差,因为它总是预测“ + ve”标签。
非常重要:同样,我们无法比较两个返回概率得分并具有相同准确性的模型。
有某些模型可以像Logistic回归那样给出每个数据点属于特定类的概率。让我们来考虑这种情况:
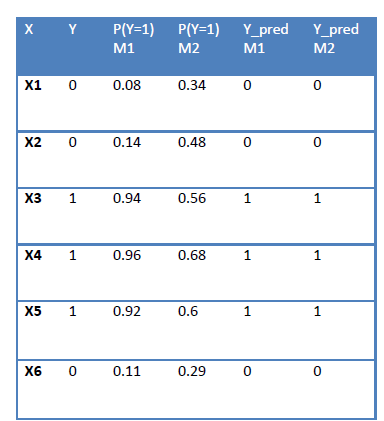
如您所见, 如果P(Y = 1)> 0.5,则预测为类1。 当我们计算M1和M2的精度时,得出的结果相同,但是很明显, M1比M2好得多通过查看概率分数。
Log Loss 处理了这个问题 ,我将在稍后的博客中进行解释。
精度和召回率
精度: 这是真实阳性率(TP)与阳性预测总数的比率。基本上,它告诉我们您的正面预测实际上是正面多少次。
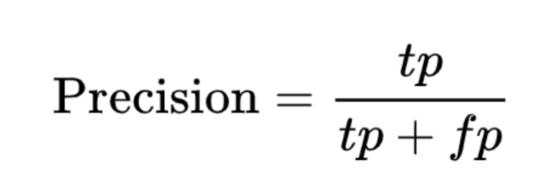
回想一下: 它不过是TPR(上文所述的“真阳性率”)。它告诉我们所有正因素中有多少被预测为正。
F度量: 精确度和查全率的谐波平均值。
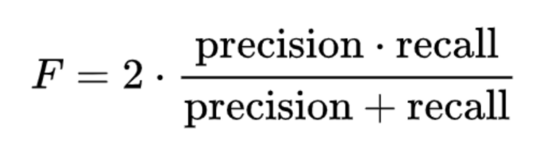
为了理解这一点,让我们看这个例子:当您在百度中查询时,它返回40个页面,但是只有30个相关。但是您的朋友告诉您,该查询共有100个相关页面。所以它的精度是30/40 = 3/4 = 75%,而召回率是30/100 = 30%。因此,在这种情况下,精度是“搜索结果的有用程度”,召回率是“结果的完成程度”。
ROC和AUC
接收器工作特性曲线(ROC):
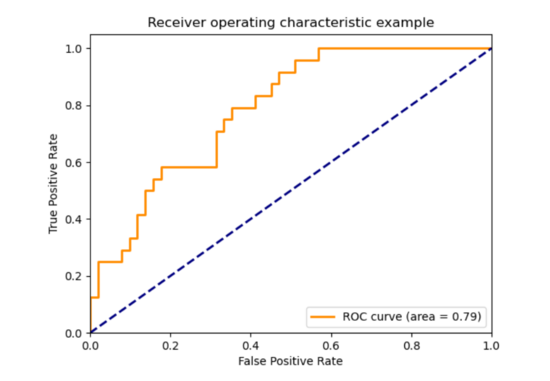
它是 通过从模型给出的概率得分的反向排序列表中获取多个阈值而计算出的 TPR(真正率)和FPR(假正率)之间的关系图 。
现在,我们如何绘制ROC?
为了回答这个问题,让我带您回到上面的表1。仅考虑M1模型。您会看到,对于所有x值,我们都有一个概率得分。在该表中,我们将得分大于0.5的数据点分配为类别1。现在,以概率分数的降序对所有值进行排序,并以等于所有概率分数的阈值一一取值。然后,我们将获得阈值= [0.96,0.94,0.92,0.14,0.11,0.08]。对应于每个阈值,预测类别,并计算TPR和FPR。您将获得6对TPR和FPR。只需绘制它们,您将获得ROC曲线。
注意:由于最大TPR和FPR值为1,因此ROC曲线下的面积(AUC)在0和1之间。
蓝色虚线下方的区域是0.5。AUC = 0表示模型很差,AUC = 1表示模型完美。只要您模型的AUC分数大于0.5。您的模型很有意义,因为即使是随机模型也可以得分0.5 AUC。
非常重要: 即使是从不平衡的数据集生成的哑模型,您也可以获得很高的AUC。因此,在处理不平衡的数据集时请务必小心。
注意: 只要维持顺序,AUC与数值概率分数无关。只要所有模型在根据概率得分排序后给出相同顺序的数据点,所有模型的AUC都将相同。
对数损失
该性能度量检查数据点的概率得分与截止得分的偏差,并分配与偏差成比例的惩罚。
对于二进制分类中的每个数据点,我们使用以下公式计算对数损失:
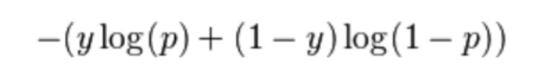
其中p =数据点属于类别1的概率,y是类别标签(0或1)。
假设某些x_1的p_1为0.95,某些x_2的p_2为0.55,并且符合1类条件的截止概率为0.5。然后两者都符合类别1的条件,但是p_2的对数损失将比p_1的对数损失大得多。
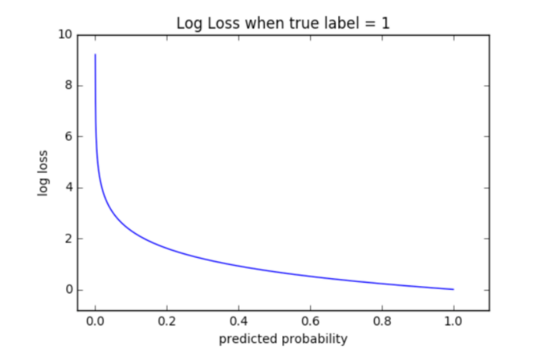
从曲线中可以看到,对数损失的范围是[0,无穷大]。
对于多类别分类中的每个数据点,我们使用以下公式计算对数损失:
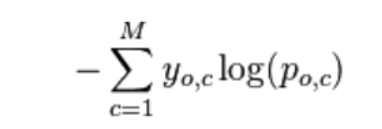
如果x(o,c)属于类别1,则y(o,c)=1。其余概念相同。
测定系数
用 R 2 表示 。 在预测测试集的目标值时,我们会遇到一些误差(e_i),这是预测值与实际值之间的差。
假设我们有一个包含n个条目的测试集。众所周知,所有数据点都有一个目标值,例如[y1,y2,y3…….yn]。让我们将测试数据的预测值设为[f1,f2,f3,……fn]。
通过使用以下公式计算 残差平方 和,即所有误差(e_i)平方的总和, 其中fi是第i个数据点的模型的预测目标值。
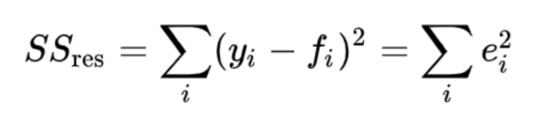
取所有实际目标值的平均值:
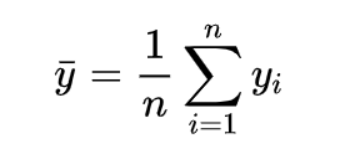
然后计算与测试集目标值的方差成正比的 总平方和 :
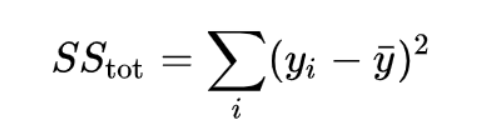
如果同时观察两个平方和的公式,则可以看到唯一的区别是第二项,即y_bar和fi。平方总和在某种程度上给我们一种直觉,即它仅与残差平方和相同,但预测值为[ȳ,ȳ,ȳ,…….ȳ,n次]。是的,您的直觉是正确的。假设有一个非常简单的均值模型,无论输入数据如何,均能每次预测目标值的平均值。
现在我们将R²表示为:
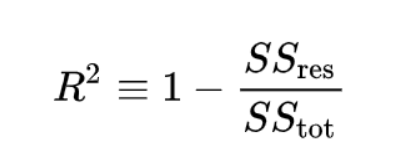
正如您现在所看到的,R²是一种度量,用于将模型与非常简单的均值模型进行比较,该均值模型每次均返回目标值的平均值,而与输入数据无关。比较有4种情况:
情况1:SS_R = 0
(R²= 1)完美的模型,完全没有错误。
情况2:SS_R> SS_T
(R²<0)模型甚至比简单的均值模型差。
情况3:SS_R = SS_T
(R²= 0)模型与简单均值模型相同。
情况4:SS_R <SS_T
(0 <R²<1)模型还可以。
摘要
因此,简而言之,您应该非常了解您的数据集和问题,然后您始终可以创建一个混淆矩阵,并检查其准确性,精度,召回率,并绘制ROC曲线,并根据需要找出AUC。但是,如果您的数据集不平衡,请不要使用准确性作为度量。如果您想对模型进行更深入的评估,以使概率分数也得到权重,请选择对数损失。
请记住,请务必评估您的训练!























