- 保证缓存和数据库的一致性很简单吗?
- 有哪些方式能保证缓存和数据库的一致性呢?
- 如果发生了缓存和数据库数据不一致的情况怎么办呢?
当我们的系统引入缓存组件之后,性能得到了大幅度提升,但是随之而来的是代码需要引入一定的复杂度,比如缓存的更新策略,写入策略,过期策略等,而其中最可能导致程序员加班的莫过于缓存和数据库的一致性问题了,既:缓存中的数据和数据库中的数据不一致。
一致性问题
说到一致性问题,这算是分布式系统中不可避免的一个痛点,或者说分布式系统天然就自带了数据一致性问题,虽然可以利用很多分布式事务解决方案来做到一致性,但是实际的系统架构设计中,我还是推崇避免分布式事务。缓存和数据库数据的一致性在产生原理上和分布式类似,其实可以把他们两个的关系看做是分布式系统中的两个操作节点。
凡是处于不同物理位置的两个操作,如果操作的是相同数据,都会遇到一致性问题
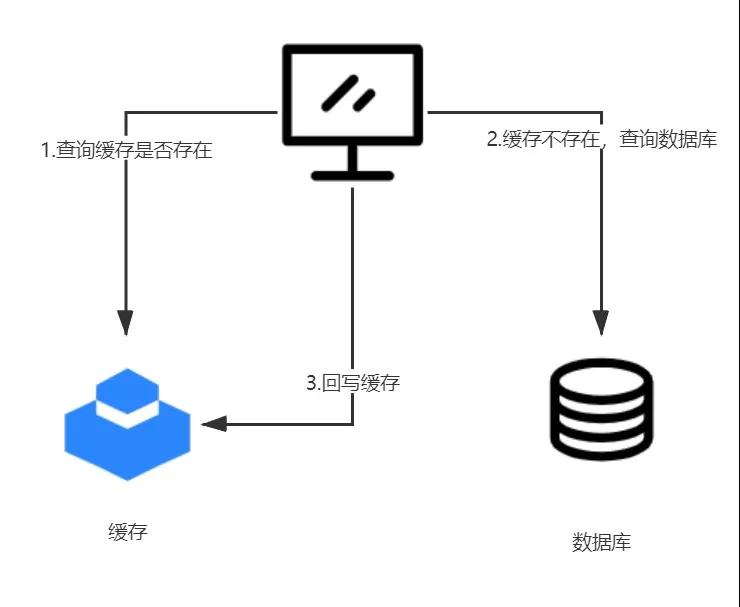
产生数据一致性问题的根本原因是对一个数据的多个操作过程,缓存和数据库数据的一致性也是这个原理,系统中最常见的操作流程是这样的:
- 数据的请求首先查询缓存中是否存在该数据
- 如果数据命中缓存(在缓存中存在)则直接返回数据,如果数据没有命中缓存(缓存中不存在),则去数据库中取数据
- 从数据库中取回数据,然后把数据写入缓存
好图
从图中可以清楚的看到,对数据库的操作和对缓存的操作是两个不同阶段的操作,在任何一个操作过程中都会发生线程安全问题。比如说:
- 当两个线程同时查询缓存的时候,可能会发生两个线程都没有命中缓存的问题
- 如果两个线程都没有命中缓存就会发生同时查询数据库的问题
- 接着就会发生两个线程同时回写缓存的问题
而这还不是最致命的,毕竟两个线程同时查询数据库,同时回写缓存数据在多数情况下缓存数据和数据库数据还能保持一致。最要命的是如果是两个线程都进行更新操作,最常见的更新过程是先更新数据库,然后更新缓存。下面就以最常见的用户积分场景为例,每个用户都有自己的积分,假如发生以下过程:
- 线程A根据业务会把用户id为1的积分更新成100
- 线程B根据业务会把用户id为1的积分更新成200
- 在数据库层面,线程A和线程B肯定不存在并发情况,因为数据库用锁来保证了ACID(假如是mysql等关系型数据库),无论数据库中最终的值是100还是200,我们都假设正确。
- 假设线程B在A之后更新数据库,则数据库中的值为200
- 线程A和线程B在回写缓存过程中,很可能会发生线程A在线程B之后操作缓存的情况(因为网络调用存在不确定性),这个时候缓存内的值会被更新成100,发生了缓存和数据库不一致的情况
通过以上案例可见,解决缓存和数据库数据不一致的根本解决方案是需要把两个操作合并成逻辑上能保证事务的一个操作
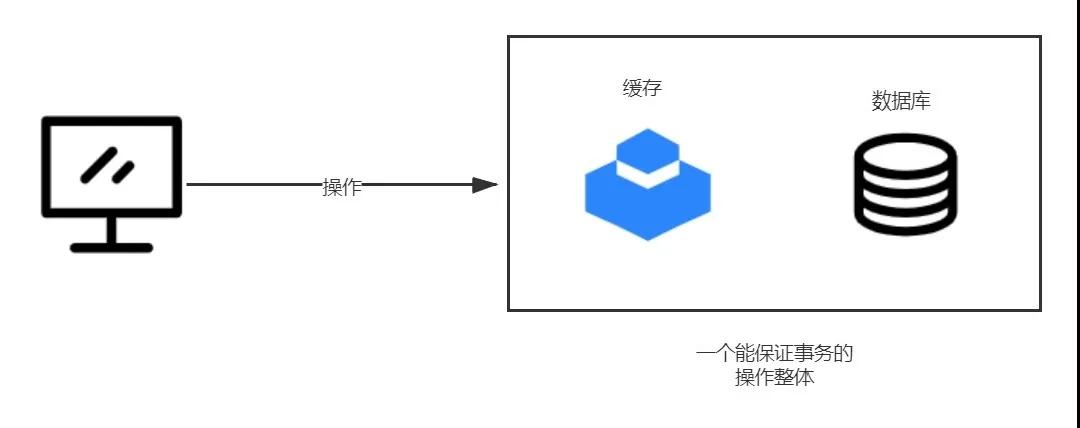
两个操作看做一个操作
分布式锁
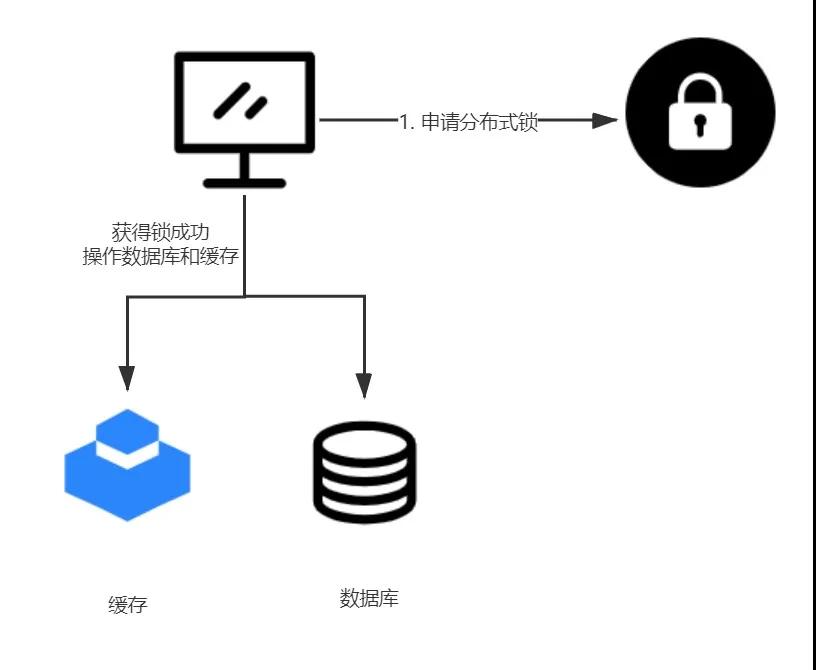
在平时开发中,利用分布式锁可能算是比较常见的解决方案了。利用分布式锁把缓存操作和数据库操作封装为逻辑上的一个操作可以保证数据的一致性,具体流程为:
- 每个想要操作缓存和数据库的线程都必须先申请分布式锁
- 如果成功获得锁,则进行数据库和缓存操作,操作完毕释放锁
- 如果没有获得锁,根据不同业务可以选择阻塞等待或者轮训,或者直接返回的策略
image
利用分布式锁是解决分布式事务的一种方案,但是在一定程度上会降低系统的性能,而且分布式锁的设计要考虑到down机和死锁的意外情况,而最常见的分布式锁就是利用redis,但是也会有不少坑。
删除缓存
相对于分布式锁的方案,而程序员实际中最喜欢使用的还是删除缓存的方式,在一个可能会发生不一致的场景下,我们会以数据库为主,在操作完数据库之后,不去更新缓存,而是删除缓存。这在一定意义上相当于只操作数据库,把需要维护的两个数据源变成了一个数据源。
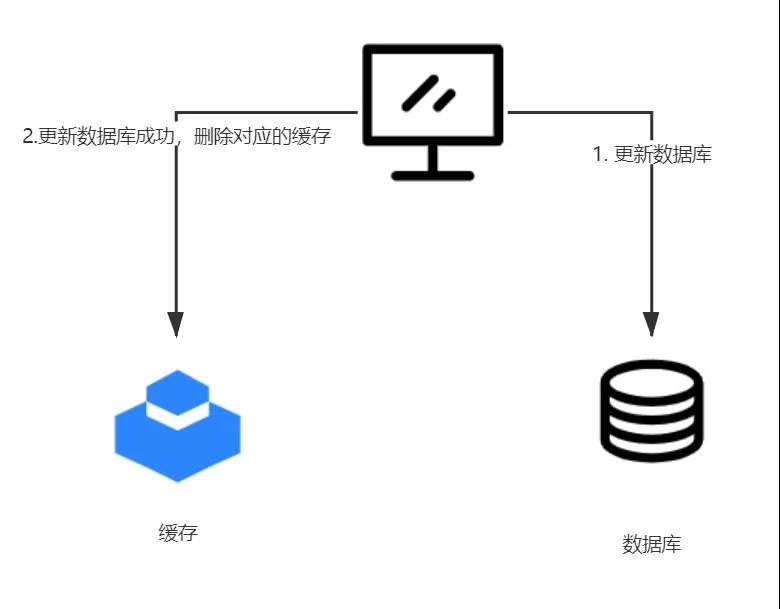
image
这种方式要求必须先操作数据库,后操作缓存,不然的话发生不一致的几率会大很多。为什么这么说呢?因为就算是先操作数据库也会有发生不一致的几率,但是毕竟在整个操作过程中,删除缓存的操作只占整个流程时间的一小部分而已,而且我们可以利用缓存的过期时间来保证数据的最终一致性,所以在一些可以容忍数据短暂不一致的场景下可以采用这种方案的。
删除缓存方案带来的另外一个劣势是:如果同样的数据会被频繁更新,缓存会被频繁删除,当有读请求的时候又会被频繁的从数据库加载,所以这种方案适用于那种对缓存命中率不敏感的系统中。
单线程
发生缓存和数据库不一致的原因在于多个线程的同时操作,如果相同的数据始终只会有一个线程去操作,不一致的情况就会避免了,比如nodejs,可以充分利用nodejs单线程的优势。提到单线程不能不提一下Actor模型,actor模型在对于同样的对象上可以看做是单线程模式。
单线程的模式基本上和分布式锁的方案类似,只不过单线程不需要锁就可以实现操作的顺序化,这也是单线程的优势所在。
其他方案
如果是以缓存为主呢?假如我们的应用程序只和缓存组件通信,至于持久化数据库由专门的程序负责,这样行不行呢?在理论上是可以的
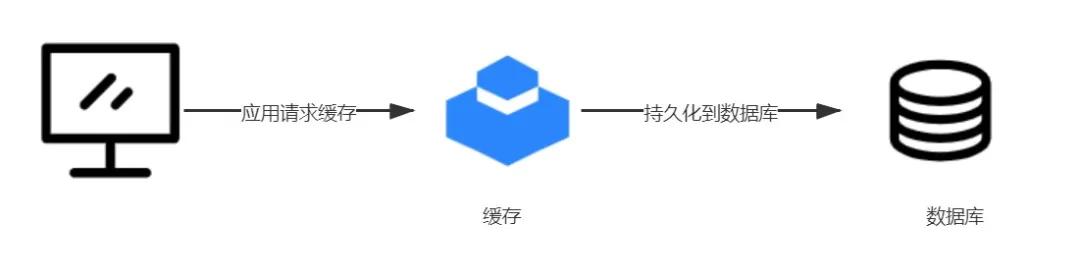
image
- 不过这种方案需要考虑几个方面:
- 数据从缓存持久化到数据采用什么样的解决方案,是同步进行还是异步进行呢?
- 在新数据请求的时候,如果缓存不存在,要采用什么样的方式来填充数据
如果缓存模块挂掉了该怎么办?
以缓存为主的方案的优势是数据优先进入IO速度快的设备,对于那些请求量大,但是可以容忍一定数据丢失的应用非常合适,比如应用log数据的收集系统,这种系统其中一个最大的特点就是可以容忍一定数据的丢失,但是并发的请求数会非常大。所以我们就可以利用缓存设备前置的方案来应对这种应用场景。
本文转载自微信公众号「架构师修行之路」,可以通过以下二维码关注。转载本文请联系架构师修行之路公众号。