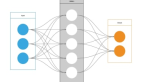
人工神经网络是一种创建人工智能的方法——模仿人类认知能力的程序。人工智能(AI)可以识别一组图像中的猫或狗、玩游戏或学习驾驶汽车。随着人工神经网络的发明,计算机在这些任务上已经变得更好——在某些情况下甚至比人类还要好。
建立一台与我们解决问题的能力相匹配或超越我们能力的机器的梦想早于现代计算机。虚构的AI的故事出现在古老的故事中。我们可以想象,智能机器会以某种方式教给我们一些我们自己不了解的东西。

人类对AI的追求一直持续到今天。为了了解为什么神经网络在现代AI中如此有用,我们首先来看一下早期AI研究人员使用传统方法遇到的一些麻烦。
AI的一些最常见示例出现在计算机和视频游戏中。
在1940年左右第一台计算机发明之后不久,游戏和计算就交织在一起。早期的程序员通过编写可以与人类玩家玩简单棋盘游戏的程序,证明了早期计算机的功能。
在棋盘游戏中,玩家根据游戏规则轮流向游戏目标前进。任何玩家(无论是人还是计算机)的目标都是最大限度地提高获胜的机会。如果您要设计AI玩可以与人类玩家抗衡的棋盘游戏,那么AI必须具备哪些能力?
- 从一个给定的状态生成一个合理的移动方式。
- 对一系列合理的动作进行排序,然后决定走哪一步。
- 测试这一举动是否符合条件,然后结束游戏。
设计具有游戏性的AI的最大挑战是开发一种对不同动作进行排名的算法。特定举动的排名不仅在于提高您的优势有多大,而且还对您的对手造成了多大破坏。
为了说明这一点,请查看下面的井字游戏,该游戏的目标是将标记(X或O)放置在网格上,以便您可以通过棋盘上的三个标记画一条直线。
这是游戏中棋盘的状态:
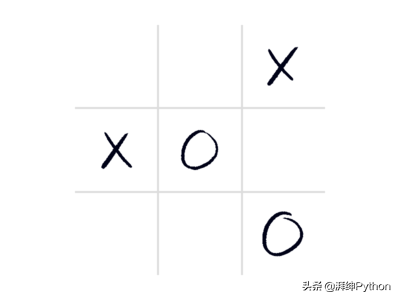
轮到X了,确定X的最佳移动,假设X或O在随后的移动中均未出错,哪个玩家将获胜?O?X?
在游戏中开始的时候进行场景预测是比较难的。
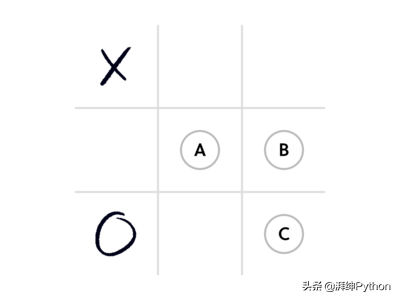
轮到X了,接下来选择那个可以确保X获胜?
假设:X在所有的后续移动中都处于正确的选择,并且O也是同样尽可能地阻止X获胜。
如果要设计一个可以从错误中吸取经验的AI,那么设计一个可以玩井字游戏的AI实际上比编写一个可以解决最后一个问题中所有不同情况的程序要容易得多。
在1960年左右,一位名叫Donald Michie的AI研究人员提出了一个革命性的想法。他着手设计一种可以从零开始学习井字游戏策略的AI。在他看来,即使AI不能很好的进行游戏,但学会以未知的方式玩游戏,比直接用游戏逻辑对其编程要好。如果他的方法适用于井字游戏,则可以扩展到更复杂的游戏。
Michie下定了决心,他的发明被广泛认为是迈向人工神经网络发展的重要一步。当时,计算机是稀有且昂贵的,所以他从他拥有很多东西的地方构建了自己的AI(Matchbox AI)。
以下是Michie的Matchbox AI的工作原理:
在井字游戏中一共有304种不同的游戏状态(将X,O和空白位置放在不同的3*3的棋盘中),一个玩家从开始到最终移动可能遇到的情况。

Matchbox AI在每种状态下都有一个Matchbox(火柴盒),因此它可以学习在任何可能遇到的情况下要做出的动作。每个Matchbox在其外部都有对应的棋盘状态,因此人类玩家可以提供帮助AI将其标记放到棋盘上。
完成所有这些设置工作后,就该开始教Matchbox AI玩游戏了。学习游戏的不是Matchbox,而是里面的东西...
每个Matchbox包含一组珠子。这些珠子可以是不同的颜色,并且每种不同的颜色对应于网格上的空点之一。
当AI放置X的时候,请遵循以下步骤:
- 找到与当前棋盘状态相对应的Matchbox 。
- 从盒子中随机选一个珠子。
- 将珠子的颜色匹配到棋盘的空白点上,然后在上面放置AI的标记。

在游戏的中间,这是您在框内找到的对应于当前棋盘状态的内容:
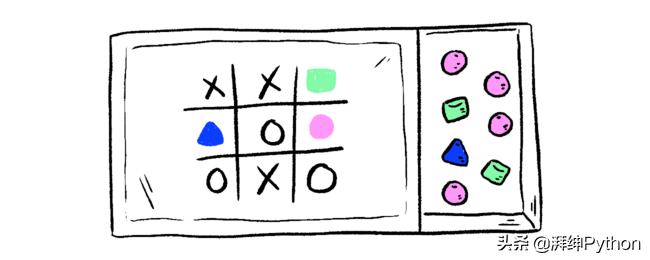
每种颜色的珠子数量不必相等。如果您从盒子中随机选择一个珠子,那么AI最有可能做出哪一步?(对应棋盘上那个颜色的标记)答案当然是粉色。
根据Matchbox中每种颜色的珠子数量,可以调整某些动作的可能性。
例如,如果确定与粉红色相对应的位置会导致游戏失败,那么对盒子中的小珠进行哪些调整将降低 AI选粉红色的可能性?去掉2个粉色的珠子或者添加2个绿色的珠子?
以下是Matchbox AI制定策略的方式:
- 如果您增加利于获胜的珠子,而去掉影响获胜的珠子,那么Matchbox AI 可能会逐渐学会并成为强大的对手。
- 在Matchbox AI第一次玩游戏之前,每个Matchbox都包含相同数量的每种珠子颜色,因此对于每种棋盘状态,每一种走法的可能性都是相等的——即使是坏的走法。
- 在第一轮中,Matchbox AI会做出一些错误的选择,这样人类玩家就会有连续获胜几轮游戏。现在通过调整Matchbox中的珠子数量来帮助Matchbox AI从错误中吸取教训。
- 既然您赢了,那么AI产生的效果就不好了,因此从Matchbox中随机抽取的每个珠子都将被丢弃。
假设在之后的10局游戏中,Matchbox都以失败告终,那在以后的游戏中Matchbox AI获胜或者平局的可能性会有什么变化呢?
起初,Matchbox AI大多会输,但如果他最终赢了,珠子将被重新调整,以便在以后的游戏中更有可能出现这种情况。在游戏中取出的珠子将被重新放入盒子中,而且还需要另外增加两个珠子。
当然,在井字游戏中,两个玩家都有可能无法将珠子连成一条线,那么游戏将以平局结束。
游戏以平局结束后我们将盒子中增加一个珠子,由于平局要比输了有用,但比赢了又差点所以我们只加一个珠子。
在这些规则下,Matchbox AI开始输掉每场比赛,但在大约100场以后,许多明显对赢得游戏有影响的珠子都已被消除了。随着AI的经验积累,它所玩的大多数游戏都以平局告终,甚至当人类对手犯错时,它有时也会获胜。(事实证明,井字游戏并不是一个非常有趣的游戏,因为熟练的玩家总是可以强制平局)。最终,Matchbox AI永远不会输,并且在每一轮结束时总是会获得珠子。
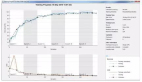
在Matchbox中对应开局的珠子的数量可以很好地衡量Matchbox AI在游戏中的学习程度,因为每一场游戏都会从Matchbox中抽取珠子。可以在下图中发现,在最初的下降之后,Matchbox中的珠子开始稳步增加,这意味着AI没有再输掉游戏了。
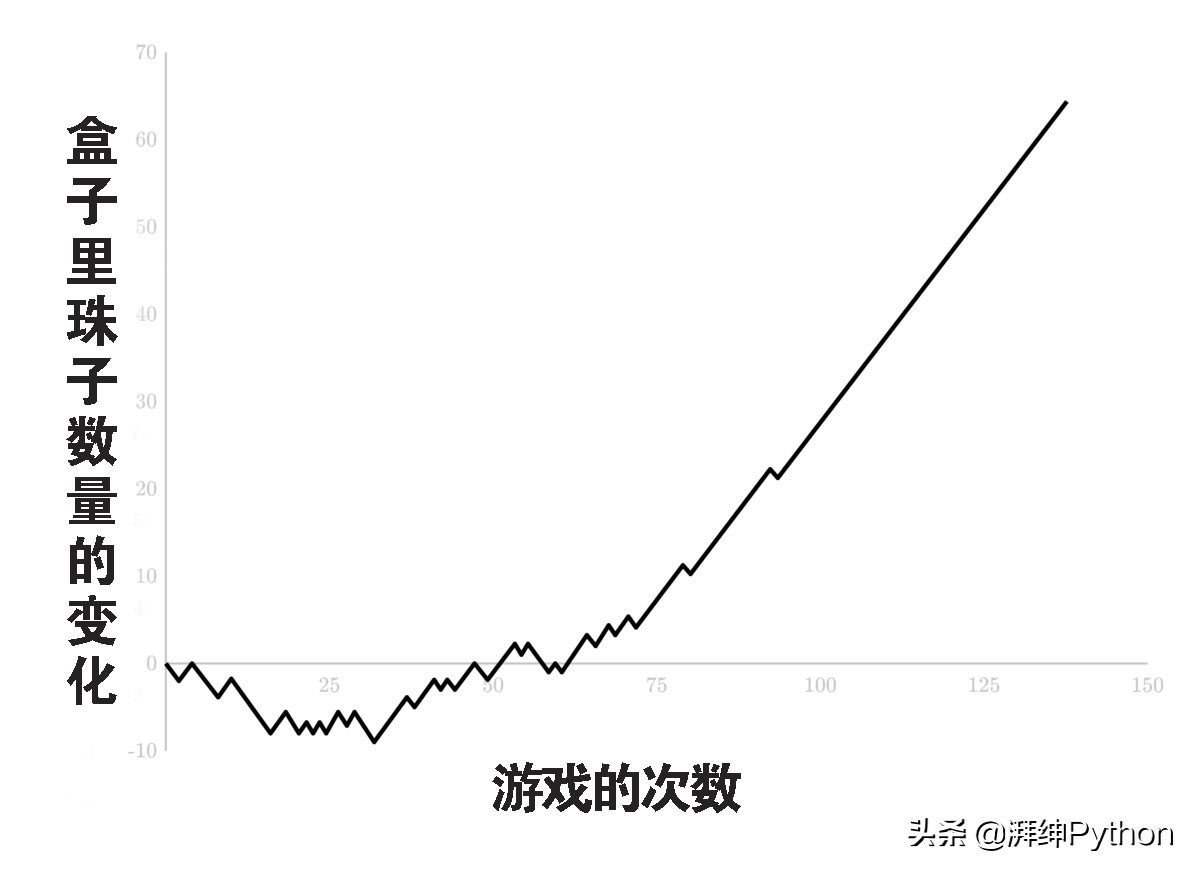
这种构建人工智能的简单策略——强化策略。每当实体学习时,这一原理的某种形式就会起作用——甚至是你自己的大脑。

像井字游戏一样,国际象棋是一种在网格上玩的策略游戏,棋盘对双方玩家都是相同的,并且不存在机会元素(例如,移动不是由掷骰子决定的)。
Matchbox AI在几百场比赛中学会了井字游戏。但如果我们开发了一种通过相同的学习算法学习象棋的Matchbox AI,并且每秒完成一次正确的移动,那么Matchbox AI大概需要多长时间才能下完国际象棋?是输、平还是赢?
在比井字游戏更复杂的游戏中,一场游戏的不同玩法的数量可能令人难以置信。Matchbox AI将需要大量的时间学习国际象棋,并且需要的时间可能是一个天文数字。
然而今天,计算机每秒可以执行数十亿条单独的指令,像国际象棋这样的游戏的人工智能现在触手可及。电脑还可以告诉你照片中的人是谁,扫描x光检查癌症迹象,并撰写人类可读的新闻摘要。这些任务的可能性空间相当于国际象棋中棋盘状态的数量,甚至更大。计算机能做什么和人类能做什么之间的差距正在缩小。