那相信大家也能感受到,其实用多线程是很麻烦的,包括线程的创建、销毁和调度等等,而且我们平时工作时好像也并没有这样来 new 一个线程,其实是因为很多框架的底层都用到了线程池。
线程池是帮助我们管理线程的工具,它维护了多个线程,可以降低资源的消耗,提高系统的性能。
并且通过使用线程池,我们开发人员可以更好的把精力放在任务代码上,而不去管线程是如何执行的,实现任务提交和执行的解藕。
本文将从是何、为何、如何的角度来讲解线程池:
- 线程池是什么
- 为什么要用线程池
- 怎么用线程池
线程池 Thread Pool
线程池是一种池化的技术,类似的还有数据库连接池、HTTP 连接池等等。
池化的思想主要是为了减少每次获取和结束资源的消耗,提高对资源的利用率。
比如在一些偏远地区打水不方便的,大家会每段时间把水打过来存在池子里,这样平时用的时候就直接来取就好了。
线程池同理,正是因为每次创建、销毁线程需要占用太多系统资源,所以我们建这么一个池子来统一管理线程。用的时候从池子里拿,不用了就放回来,也不用你销毁,是不是方便了很多?
Java 中的线程池是由 juc 即 java.util.concurrent 包来实现的,最主要的就是 ThreadPoolExecutor 这个类。具体怎么用我们下文再说。
线程池的好处
在多线程的第一篇文章中我们说过,进程会申请资源,拿来给线程用,所以线程是很占用系统资源的,那么我们用线程池来统一管理线程就能够很好的解决这种资源管理问题。
比如因为不需要创建、销毁线程,每次需要用的时候我就去拿,用完了之后再放回去,所以节省了很多资源开销,可以提高系统的运行速度。
而统一的管理和调度,可以合理分配内部资源,根据系统的当前情况调整线程的数量。
那总结来说有以下 3 个好处:
- 降低资源消耗:通过重复利用现有的线程来执行任务,避免多次创建和销毁线程。
- 提高相应速度:因为省去了创建线程这个步骤,所以在拿到任务时,可以立刻开始执行。
- 提供附加功能:线程池的可拓展性使得我们可以自己加入新的功能,比如说定时、延时来执行某些线程。
说了这么多,终于到了今天的重点,我们来看下究竟怎么用线程池吧~
线程池的实现
Java 给我们提供了 Executor 接口来使用线程池。
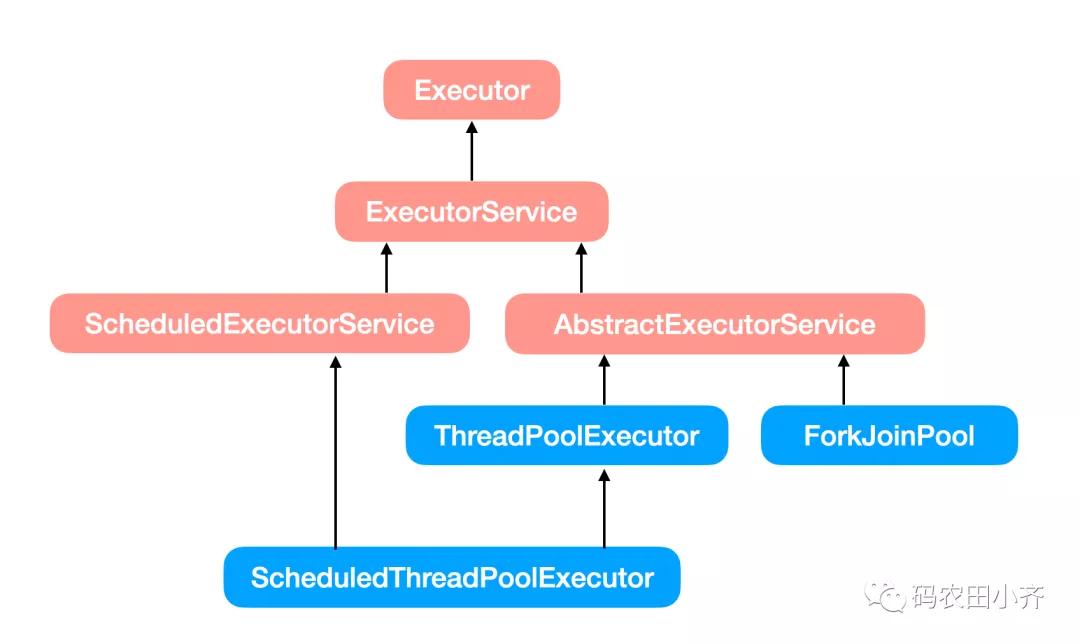
Executor
我们常用的线程池有这两大类:
- ThreadPoolExecutor
- ScheduledThreadPoolExecutor
它俩的区别呢,就是第一个是普通的,第二个是可以定时执行的。
当然还有其他线程池,比如 JDK 1.7 才出现的 ForkJoinPool ,可以把大任务分割成小任务来执行,最后再大一统。
那么任务提交到一个线程池之后,它会经历一个怎样的过程呢?
执行过程
线程池在内部实际上采用了生产者消费者模型(还不清楚这个模型的在文章开头有改文章的链接)将线程和任务解藕,从而使线程池同时管理任务和线程。
当任务提交到线程池里之后,需要经过以下流程:
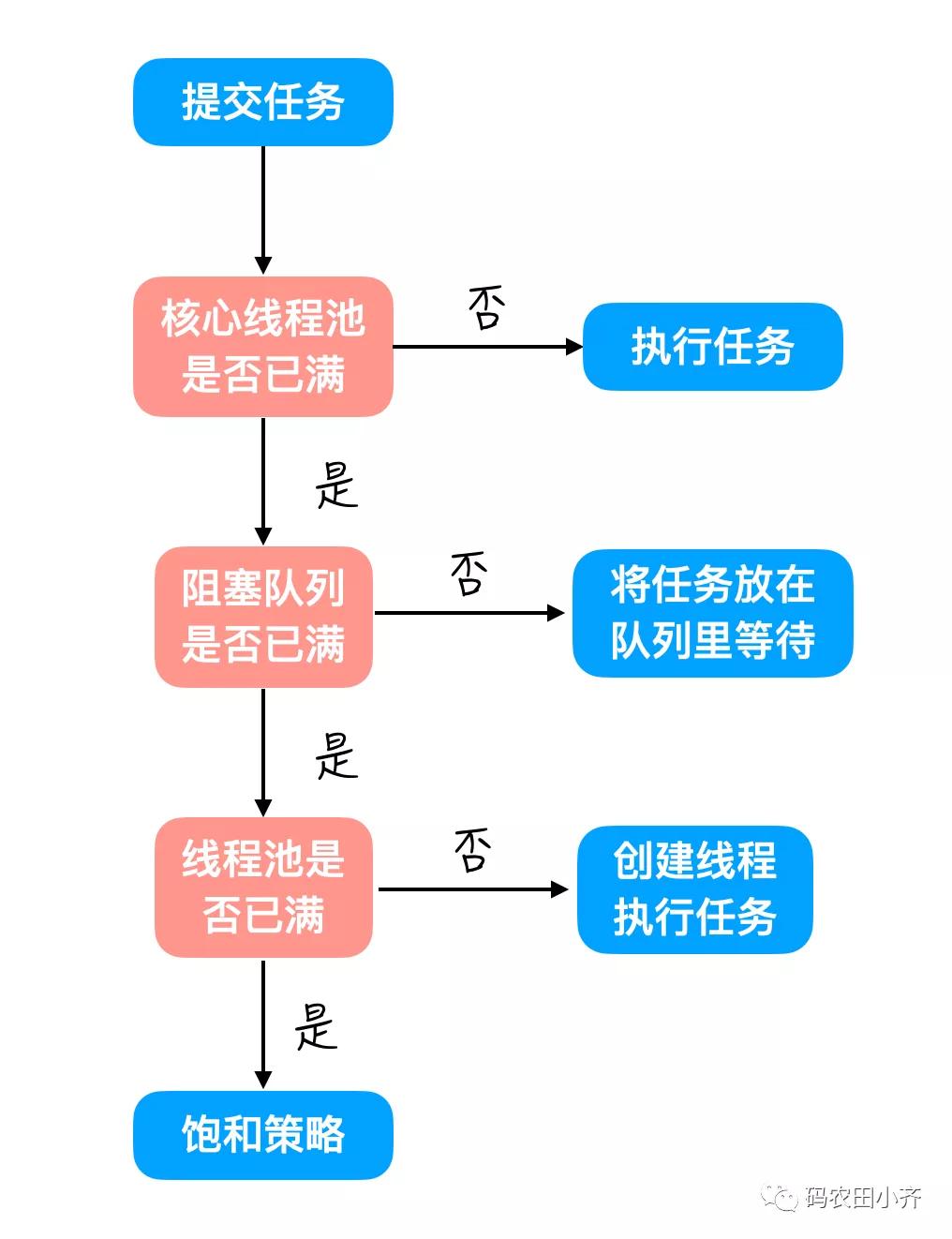
执行过程
- 首先它检查核心线程池是否已满。这个核心线程池,就是不管用户量多少线程池始终维护的线程的池子。比如说线程池的总容量最多能装 100 个线程,核心线程池我们设置为 50,那么就无论用户量有多少,都保持 50 个线程活着。这个数字当然是根据具体的业务需求来决定的。
- 阻塞队列,就是 BlockingQueue ,在生产者消费者这节里提到过。
- 最后判断线程池是否已满,就是判断是不是已经有 100 个线程了,而不是 50 个。
- 如果已经满了,所以不能继续创建线程了,就需要按照饱和策略或者叫做拒绝策略来处理。这个饱和策略我们下文再讲。
ThreadPoolExecutor
我们主要说下 ThreadPoolExecutor ,它是最常用的线程池。

ThreadPoolExecutor Structure
这里我们可以看到,这个类里有 4 个构造方法,点进去仔细看,其实前三个都 call 了最后一个,所以我们只需要看最后一个就好。
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
...
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
这里我们来仔细看下这几个参数:
1.corePoolSize:这个就是上文提到过的核心线程池的大小,在核心里的线程是永远不会失业的。
- corePoolSize the number of threads to keep in the pool, even if they are idle, unless {@code allowCoreThreadTimeOut} is set
2.maximumPoolSize:线程池的最大容量。
- maximumPoolSize the maximum number of threads to allow in the pool
3.keepAliveTime:存活时间。这个时间指的是,当线程池中的线程数量大于核心线程数,这些线程闲着之后,多久销毁它们。
- keepAliveTime when the number of threads is greater than the core, this is the maximum time that excess idle threads will wait for new tasks before terminating.
4.unit:对应上面存活时间的时间单位。
- unit the time unit for the {@code keepAliveTime} argument
5.workQueue:这是一个阻塞队列,其实线程池也是生产者消费者模型的一种,任务 - 相当于生产者,线程 - 相当于消费者,所以这个阻塞队列是用来协调生产和消费的进度的。
- workQueue the queue to use for holding tasks before they are executed.
6.threadFactory:这里用到了工程模式,用来创建线程的。
- threadFactory the factory to use when the executor creates a new thread
7.handler:这个就是拒绝策略。
- handler the handler to use when execution is blocked because the thread bounds and queue capacities are reached
所以我们可以通过自己传入这 7 个参数构造线程池,当然了,贴心的 Java 也给我们包装好了几类线程池可以很方便的拿来使用。
- newCachedThreadPool
- newFixedThreadPool
- newSingleThreadExecutor
我们具体来看每个的含义和用法。
newCachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
- 1.
- 2.
- 3.
- 4.
- 5.
这里我们可以看到,
- 核心线程池数量为 0,也就是它不会永久保留任何线程;
- 最大容量是 Integer.MAX_VALUE;
- 每个线程的存活时间是 60 秒,也就是如果 1 分钟没有用这个线程就被回收了;
- 最后用到了同步队列。
它的适用场景在源码里有说:
- These pools will typically improve the performance of programs that execute many short-lived asynchronous tasks.
来看怎么用:
public class newCacheThreadPool {
public static void main(String[] args) {
// 创建一个线程池
ExecutorService executorService = Executors.newCachedThreadPool();
// 向线程池提交任务
for (int i = 0; i < 50; i++) {
executorService.execute(new Task());//线程池执行任务
}
executorService.shutdown();
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
执行结果:

newCached 结果
可以很清楚的看到,线程 1、2、3、5、6 都很快重用了。
newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
- 1.
- 2.
- 3.
- 4.
- 5.
这个线程池的特点是:
- 线程池中的线程数量是固定的,也是我们创建线程池时需要穿入的参数;
- 超出这个数量的线程就需要在队列中等待。
它的适用场景是:
- Creates a thread pool that reuses a fixed number of threads operating off a shared unbounded queue.
public class FixedThreadPool {
public static void main(String[] args) {
ExecutorService executorService = Executors.newFixedThreadPool(10);
for (int i = 0; i < 200; i++) {
executorService.execute(new Task());
}
executorService.shutdown();
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
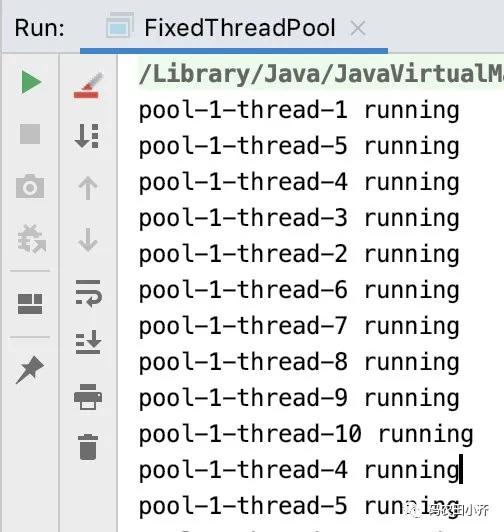
newFixed 结果
这里我限制了线程池里最多有 10 个线程,哪怕有 200 个任务需要执行,也只有 1-10 这 10 个线程可以运行。
newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
这个线程池顾名思义,里面只有 1 个线程。
适用场景是:
- Creates an Executor that uses a single worker thread operating off an unbounded queue.
我们来看下效果。
public class SingleThreadPool {
public static void main(String[] args) {
ExecutorService executorService = Executors.newSingleThreadExecutor();
for (int i = 0; i < 100; i++) {
executorService.execute(new Task());
}
executorService.shutdown();
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
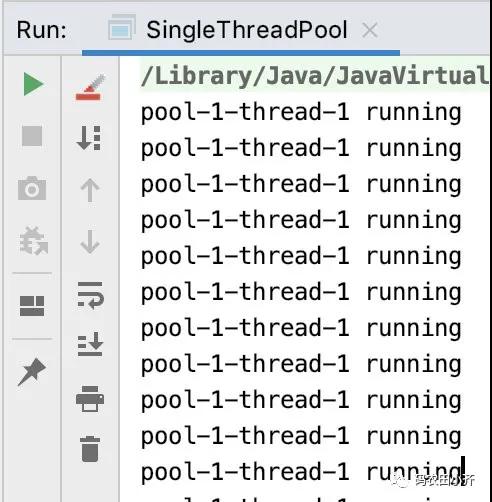
newSingle 结果
这里在出结果的时候我能够明显的感觉到有些卡顿,这在前两个例子里是没有的,毕竟这里只有一个线程在运行嘛。
小结
所以在使用线程池时,其实都是调用的 ThreadPoolExecutor 这个类,只不过传递的不同参数。
这里要特别注意两个参数:
- 一是 workQueue 的选择,这个就是阻塞队列的选择,如果要说还得这么一大篇文章,之后有机会再写吧。
- 二是 handler 的设置。
那我们发现,在上面的 3 个具体线程池里,其实都没有设定 handler,这是因为它们都使用了 defaultHandler。
/**
* The default rejected execution handler
*/
private static final RejectedExecutionHandler defaultHandler =
new AbortPolicy();
- 1.
- 2.
- 3.
- 4.
- 5.
在 ThreadPoolExecutor 里有 4 种拒绝策略,这 4 种策略都是 implements 了 RejectedExecutionHandler:
- AbortPolicy 表示拒绝任务并抛出一个异常 RejectedExecutionException。这个我称之为“正式拒绝”,比如你面完了最后一轮面试,最终接到 HR 的拒信。
- DiscardPolicy 拒绝任务但不吭声。这个就是“默拒”,比如大部分公司拒简历的时候都是默拒。
- DiscardOldestPolicy 顾名思义,就是把老的任务丢掉,执行新任务。
- CallerRunsPolicy 直接调用线程处理该任务,就是 VIP 嘛。
所以这 3 种线程池都使用的默认策略也就是第一种,光明正大的拒绝。
好了以上就是本文的所有内容了。当然线程池还有很多知识点,比如 execute() 和 submit() 方法,线程池的生命周期等等。
但随着阅读量的逐渐走低,齐姐意识到了这似乎有什么误会,所以这篇文章是多线程系列的最后一篇了。
本文已收录至我的 Github 上:https://github.com/xiaoqi6666/NYCSDE,点击阅读原文直达,这个 Github 汇总了我所有的文章和资料,之后也会一直更新和维护,还希望大家帮忙点个 Star,你们的支持和认可,就是我创作的最大动力!
本文转载自微信公众号「码农田小齐」,可以通过以下二维码关注。转载本文请联系码农田小齐公众号。