












本文转载自微信公众号「后端技术指南针」,作者指南针氪金入口。转载本文请联系后端技术指南针公众号。
1.迷茫的小黑
小黑最近有点郁闷。
手头的工作不是特别喜欢,技术退步有点严重,于是想出去看看机会。
小黑通过朋友内推,前几天去北京CBD附近的一家名叫宇节蹦跶的公司面试,被一些问题三连击直接跪掉了。
大白安抚小黑说:"黑哥,你要知道没有好工作,只有好工人,其实哪儿都差不多,都是打工嘛!"
小黑说:"那咋能一样,工具人么得意思,俺的目标是架构师!"
小黑把大白数落了一顿,毕竟不想当架构师的后端不算好的程序员,然后开始说他碰到的问题,原来事情是这样的:
小黑开场白介绍完自己之后,面试官问他喜欢哪个领域,小黑说分布式存储。
面试官附和道:"确实是个不错的领域,那问你几个存储相关的问题吧!"
小黑窃喜以为问题在自己知识射程范围内,于是面试官抛出了几个问题:
1.在实际工作中用到过哪些NoSQL?
2.NoSQL相比MySQL有什么优缺点?
3.WAL和LSM这些底层机制了解吗?
4.如何设计一个NoSQL。
听完这几个问题,小黑慌得一批,东扯西扯了几句后,面试官也看出小黑关于存储的知识边界了,很有礼貌地不再追问了。
出于友好礼节,问了几个小黑简历上的东西,最后结束了这场面试。
大白听完也有点慌,故作镇定说:"黑哥,你这几个问题都比较典型,周末写一篇文章,给你讲讲这块东西。"
小黑笑道:"哈哈哈,就等你这个呢,老规矩周五放松一下!上周恰烧烤了,这周恰个火锅呗"
害,大白和小黑真是吃喝二人组啊,言归正传,开始NoSQL之旅吧!
2. 大器晚成NoSQL
NoSQL一词最早出现于1998年,受限于当时的技术场景和应用情况,并没有折腾出什么大浪,但是在2009年NoSQL再次被提出,这一次出场有点炸裂,颇有明日之星的赶脚。
一般来说,这事行不行往往和口号有很大关系,像我大白的口号就是:人生实苦,早点退休。
2009年在亚特兰大的一次重要会议上对NoSQL提出了个文雅&响亮的口号:
- select fun, profit from real_world where relational=false;
本质上NoSQL是一类数据库的泛称,具体的可以分为以下几种:
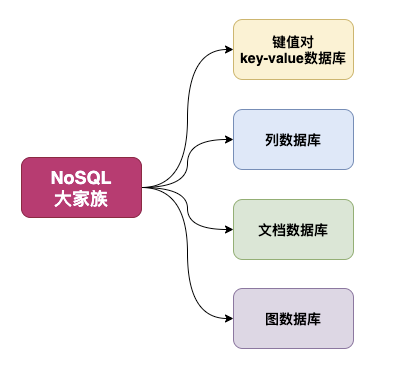
本文只介绍键值对key-value型数据库,先看下NoSQL名字的来源和含义的几种解读吧:
- 解读一
NoSQL 意为"No SQL" 翻译为SQL已死。潜台词是这类数据库没有SQL语句,摒弃了老大哥MySQL的路子,让它退休。
嚯,好家伙,口气不小,事实证明,这种"SQL已死"的自信确实有点扯犊子了。
- 解读二
NoSQL 意为"Not Only SQL",显然没有那么嚣张了,倒添了几分谦虚,不仅仅是SQL,除了继承了老大哥MySQL的一些功能,还增加了新东西,听起来还不错的样子。
- 解读三
NoSQL本质上是非关系型数据库,我们都知道关系型数据库一般缩写为RDS或者RDB,所以有人觉得NoSQL应该称为"No Relational Database",简称"没关系数据库"。
综上,我们更倾向于NoSQL为"Not Only SQL",作为关系型数据库的补充而存在的一种新形式的数据库。
3. 给NoSQL一首歌的时间
工欲善其事 必先利其器,大家都这么忙,必须要给个学习NoSQL的理由。
我们试想几种熟悉的场景(点击查看大图):
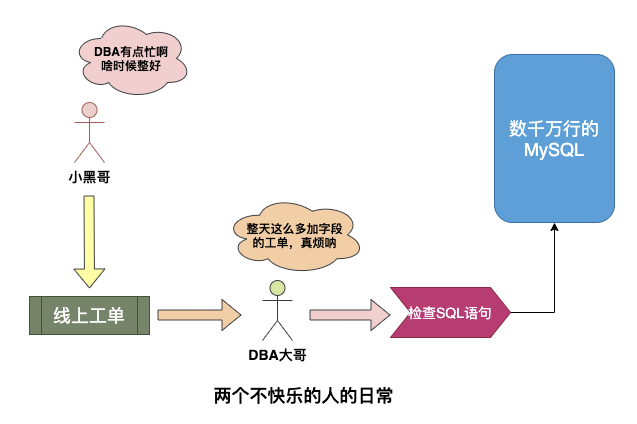
- 场景一
Leader大熊给小黑一个需求,这个需求在几千万行的MySQL中加个字段,由于是生产环境需要找DBA手动执行,好家伙排队大半天才给执行,给小黑气的,太耽误事了太不方便了。
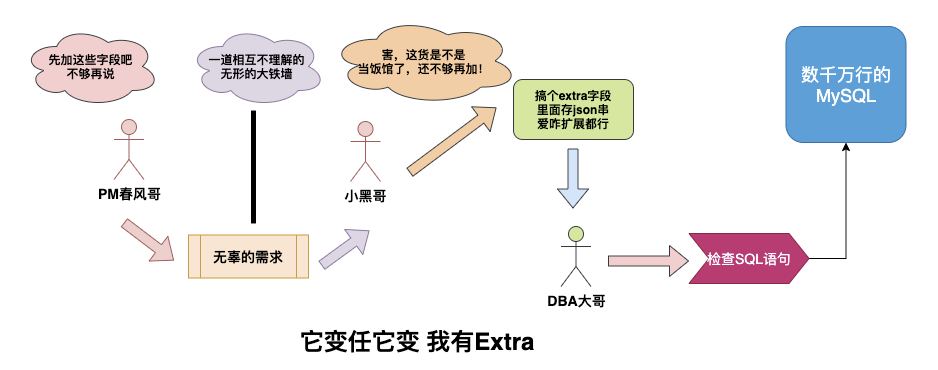
- 场景二
Leader大熊又给了小黑一个需求,让他存储一个数据包,数据包其实是Json的串,里面有很多字段,但是现在也不明确PM要怎么用,字段是否会调整,所以用MySQL存储的话,字段还不能确定,于是小黑加了个extra字段来存储后续的扩展,暂时解决了。
- 场景三
Leader大熊让小黑设计一个并发访问大一些的服务,来完成用户账号体系查询,目前差不多有4亿账号ID,大熊搞了C++服务&存储选择了MySQL,性能怎么也提不上去,真是一筹莫展。
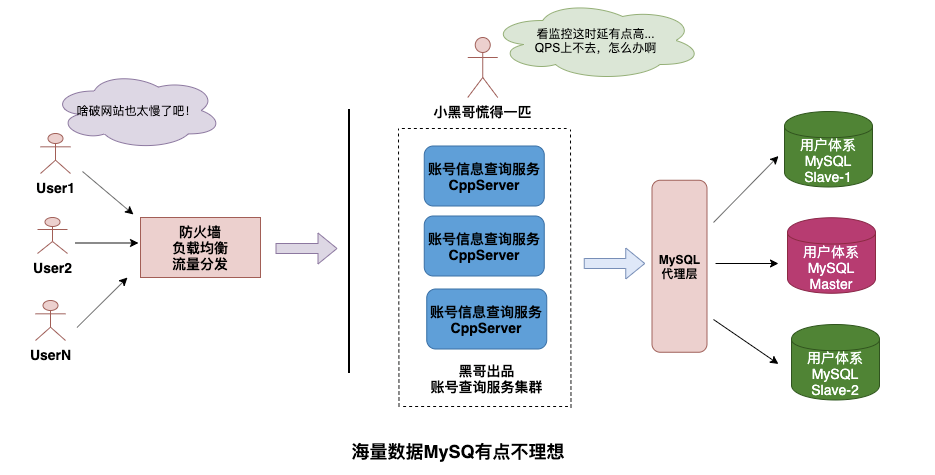
MySQL横行江湖数十载,无人匹敌,尤其在事务、数据一致性、关联查询等场景具有绝对的统治力,确实是数据库蓝波万。
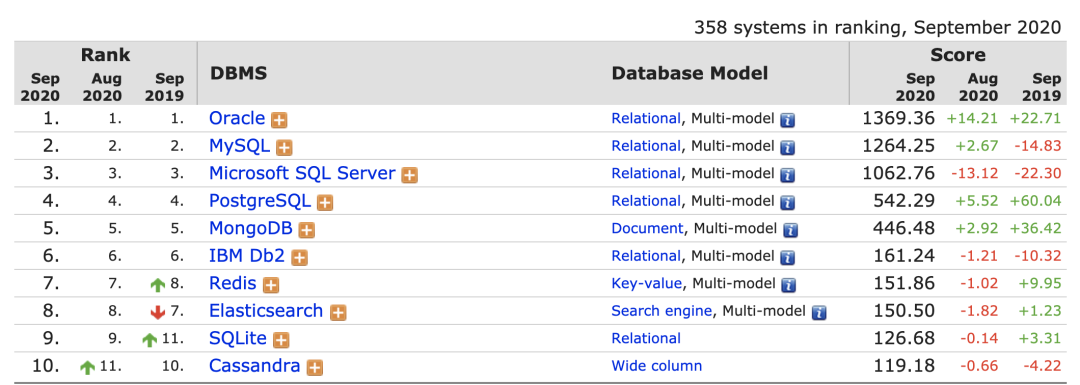
科技进步和新常用新形式的出现也让MySQL有些捉襟见肘,毕竟MySQL不是万金油,要保住地位必须与时俱进才行。
在很多场景中我们并不需要事务、强数据一致性、多表关联等特性,所以我们需要一类更轻快的数据库,它就是NoSQL。
4. MySQL vs NoSQL
我们有必要将MySQL和NoSQL进行一番对比,来加深印象:
- MySQL是高度组织化结构化的数据存储,NoSQL无结构化存储
- MySQL使用结构化查询语句,NoSQL无查询语言
- MySQL需要定义字段和模式,NoSQL自由扩展
- MySQL海量数据时读写性能劣于NoSQL
- MySQL扩展性较差
上面这些好像全是diss老大哥MySQL的,但是并不是说MySQL很弱,相反是MySQL非常强悍。
高并发&高可用&高可扩展的新要求成就了NoSQL,NoSQL之所以可以应对这些新场景,和它的设计思想有很大的关系。
或许可以用葡萄来说明为啥NoSQL更适用于高并发场景。
- NoSQL是一粒一粒的葡萄,存取都非常方便,读写速度快
- MySQL是一串葡萄,每一粒都是相互关联的,存取较为麻烦,读写速度慢
两类数据库的对比就说这么多,我们来看看几款大白在实际工作中用过的NoSQL吧!
5. NoSQL明星项目
开源的NoSQL非常多,大白按照层次挑几个典型的代表来和大家分享一下。
NoSQL可以是单机的,也可以是分布式的,可以根据自己的目的来使用。
今天要介绍的几款数据库:Redis、Pika、SSDB、RocksDB、LevelDB。
其中LevelDB是谷歌开发的,RocksDB是Facebook在LevelDB的基础上增加新特性开发的,Redis则不用多说,SSDB和Pika则是国内开源的类Redis的数据库,也非常棒。
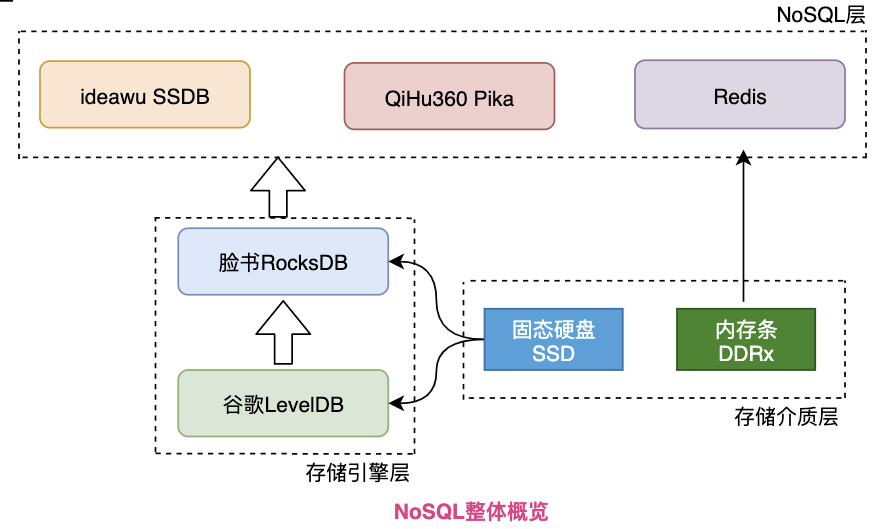
接下来看看这几款数据库的特点、联系、底层原理等有趣的东西。
5.1 谷歌出品LevelDB
LevelDB是谷歌的Sanjay Ghemawat和Jeff Dean使用C++开发的单进程/单机版持久化的key-value数据库,于2011年7月开源,可以说是重磅产品。
LevelDB支持了最基础的key-value操作:Get/Put/Delete,但是并没有封装其他的东西,严格意义上来说只是NoSQL存储引擎。
一般来说,机械磁盘最害怕的就是随机读写,磁盘呼噜噜转起来就意味着读写效率在下降。

LevelDB具有很高的随机写,顺序读/写性能,因此LevelDB很适合应用在写多读少的场景,真让人好奇高性能的随机写怎么做到的。
5.1.1 LSM树
很多数据在逻辑上相近,但是在物理存储上却可能相隔很远,这样就会造成大量的随机读写问题,从而降低性能。
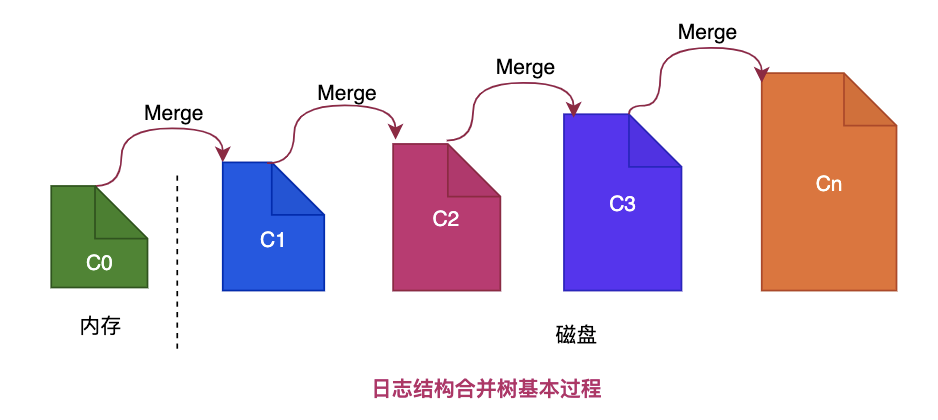
LevelDB实现高性能随机写的秘密武器在于使用LSM树存储结构,LSM树又称为日志结构合并树(Log-Structured Merge-Tree),它并不是具体的数据结构,而是一种设计思想。
LSM树对于每次写入操作,并不是直接将最新的数据驻留在磁盘中,而是将数据先放在内存。
当内存数据达到一定的阈值,再将这部分数据真正刷新到磁盘文件中,从而将磁盘随机写转换为内存顺序写,因而获得了极高的写性能,但是这种机制会降低读的性能,总体来说降低部分读性能来大幅提升写性能是值得的。
5.1.2 LevelDB整体架构
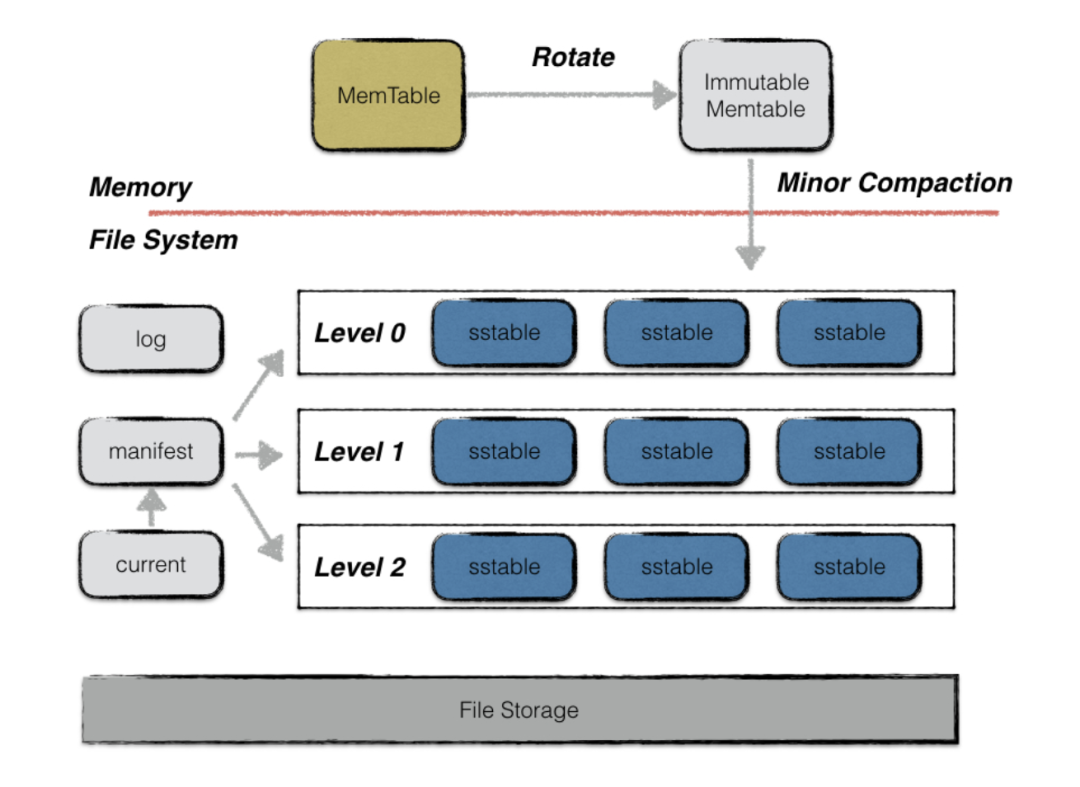
LevelDB 存储结构主要由六个部分组成:
- MemTable:内存数据结构,使用SkipList实现,新的数据修改会首先在这里写入,并且有容量限制。
- Immutable MemTable:待落盘的数据库内存结构,当 MemTable的大小达到设定的阈值时,会变成 Immutable MemTable,只接受读操作,不再接受写操作,后续会Flush到磁盘上。
- SST Files:Sorted String Table Files,磁盘数据存储文件,分为 Level0 到 LevelN 多层,每一层包含多个 SST 文件,文件内数据有序。
- Manifest Files:leveldb元信息清单文件。Manifest记录 SST 文件在不同 Level 的分布,相当于SST文件的索引。
- Current File:当前正在使用的文件清单文件。
LevelDB的读写过程和上述的整体架构关系密切,也是先内存后磁盘,一层层读取搜索数据的。
5.2 脸书出品RocksDB
青出于蓝而胜于蓝。
RocksDB在LevelDB的基础上进行了改进和优化,也成为后续很多NoSQL所选择的存储引擎。
RocksDB仍然是采用C++开发的,并且完全向后兼容了LevelDB的接口,可以说是个平滑升级。
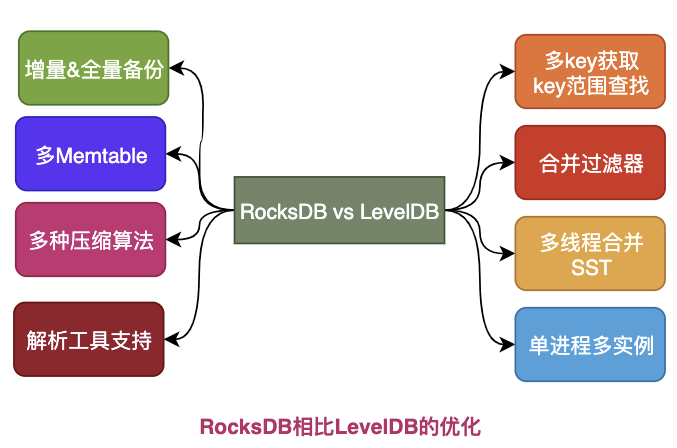
5.2.1 RocksDB提升点
来看看RocksDB做了哪些优化和提升:
- RocksDB支持一次获取多个Key,还支持Key范围查找,LevelDB只能获取单个Key。
- RocksDB支持多线程合并,而LevelDB是单线程合并的,多核时代前者效率更高。
- RocksDB增加了合并时过滤器,对不符合条件的Key进行丢弃。
- RocksDB可采用多种压缩算法,除了LevelDB用的snappy,还有zlib、bzip2。
- RocksDB支持增量备份和全量备份。
RocksDB支持管道式的Memtable,使用多个Memtable,LevelDB只有一个Memtable。
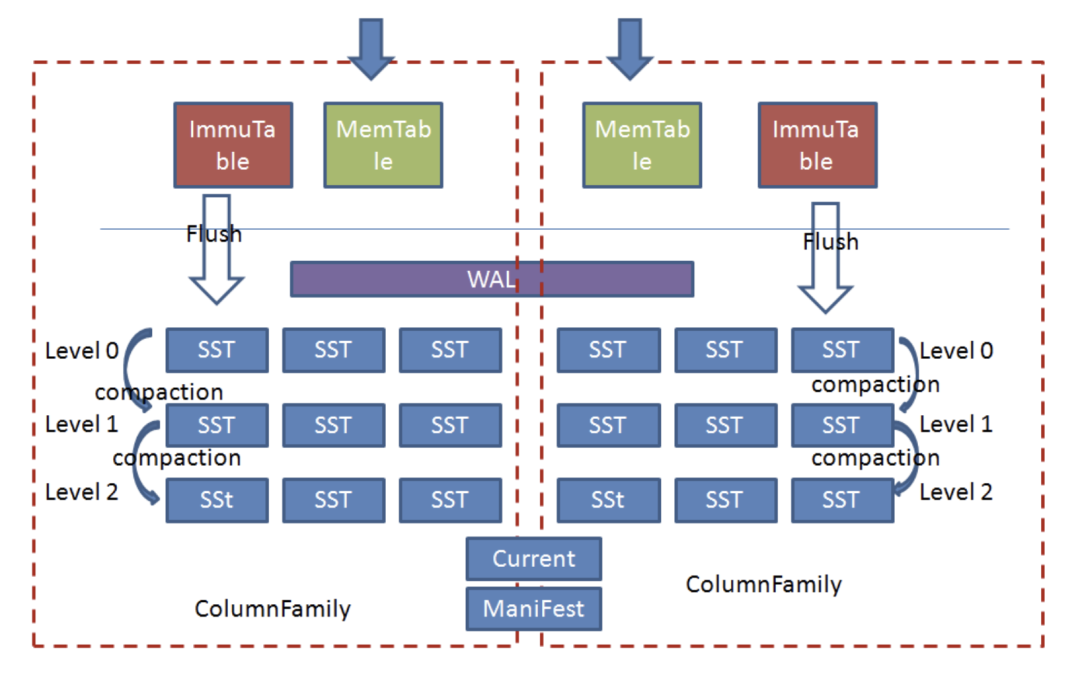
5.2.2 RocksDB整体架构
Rocksdb中引入了Column Family(列族的概念,所谓列族也就是一系列kv组成的数据集,所有的读写操作都需要先指定列族。
每个ColumnFamily有自己的Memtable, SST文件,所有ColumnFamily共享WAL、Current、Manifest文件。
如果说LevelDB是个平民版的NoSQL存储引擎,那么RocksDB绝对是尊享版,所以很多优秀的NoSQL成品都是基于RocksDB来封装上层协议和代理支持完成的。
5.3 ideawu的SSDB
SSDB是基于SSD作为底层存储介质的类Redis数据库。
Redis过于迷人和好用,但是又太昂贵了,所以我们幻想着有一款支持Redis数据结构且容量没限制的数据库。
这种数据库将Redis的数据结构优势和廉价磁盘介质联合起来,着实让人着迷。
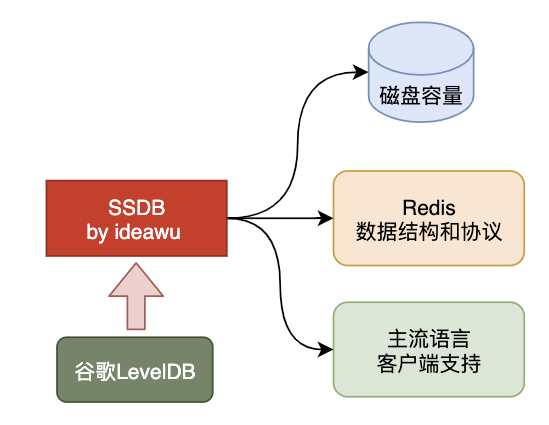
没错,SSDB就是这样一款NoSQL数据库。

目前SSDB的维护者并不是特别多,并且在集群化等方面还存在一些问题,不过也算是非常优秀的开源NoSQL了。
来简单看下SSDB的基本架构:
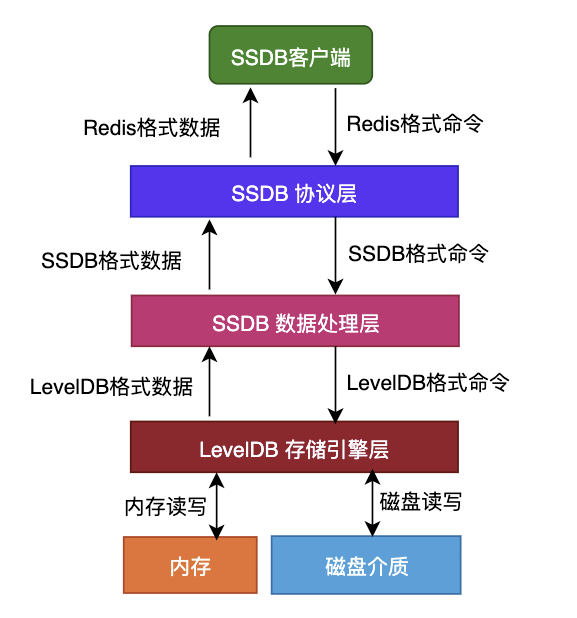
简单来说,SSDB在LevelDB和Redis协议之间做了一层转换,从而实现命令和数据的切换,这就是使用存储引擎之前封装附加部分,从而形成完整的NoSQL。
5.4 360出品Pika
其实SSDB和Pika很有渊源,SSDB的作者曾经在360工作,并且SSDB当时在360的生产环境中使用广泛,Pika数据库是360基于RocksDB开发的集群化高性能NoSQL。
Pika是360DBA团队和基础架构团队使用C++语言联合开发的类Redis存储系统,所以完全支持Redis协议。
Pika是一个可持久化的大容量Redis存储服务,解决Redis由于存储数据量巨大而导致内存不够用的容量瓶颈,并且支持全同步和部分同步。
Pika还提供了迁移工具,实现Redis数据到Pika的平滑迁移,Pika的定位目标并不是取代redis, 而是作为redis的补充,在性能上肯定会低于Redis。
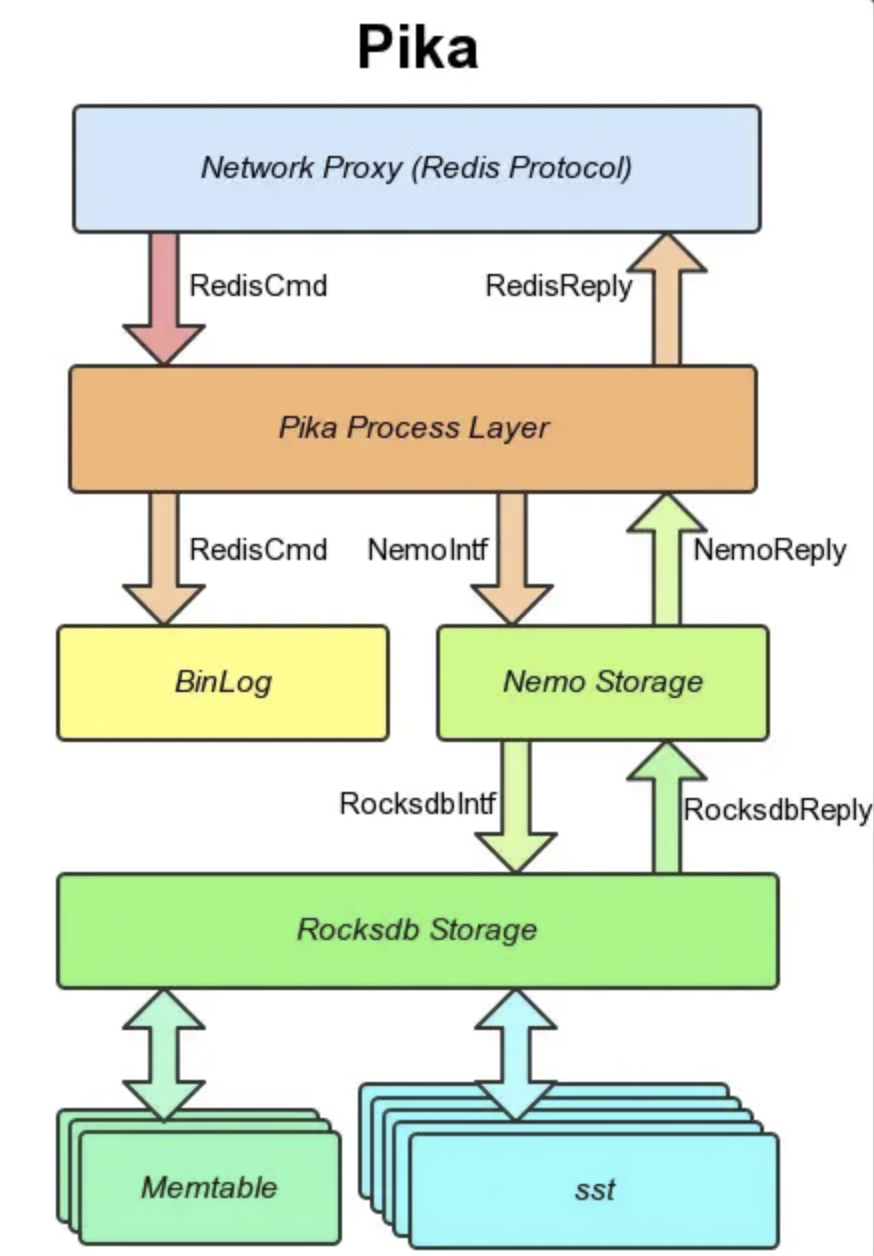
从整体架构可知,Pika是多线程实现的,因此对多核使用效率更高,虽然单线程性能不如Redis,但是多个线程一起上性能也还不错。
Pika目前在360内部使用非常广泛,在一些其他的互联网公司也有使用。
说到底NoSQL是一个实践类的项目,本文也不能讲述太多,否则很空洞,意义不大。
5.5 其他NoSQL
基本上很多互联网公司都会基于LevelDB或者RocksDB开发一款自己的Key-Vaule数据库,有的只支持简单的string结构,有的完全兼容Redis协议和客户端。
大都是解析Redis协议、使用Redis的客户端、增加一层命令解析和数据格式解析层、再有可能有多线程支持&主从化&集群化等。
自己开发一款简单的NoSQL,可以极大提升自己对于NoSQL的理解,在github上有很多这样的项目,可以参考学习下。
6. 本文小结
本文粗浅阐述了NoSQL的一些相关知识点,以及一些笔者实践过的NoSQL。
大致原理本质上差不多,但是要打造一款高性能&高可用的工业级NoSQL是非常困难的。
















