本文转载自公众号“读芯术”(ID:AI_Discovery)。
本文将讨论目标检测的基本方法(穷尽搜索、R-CNN、Fast R-CNN和Faster R-CNN),并尝试理解每个模型的技术细节。为了让经验水平各不相同的读者都能够理解,文章不会使用任何公式来进行讲解。

检测螺母和螺栓-克里斯·耶茨(Unsplash)
开启目标检测的第一步
这是只鸟还是架飞机?—— 图像分类
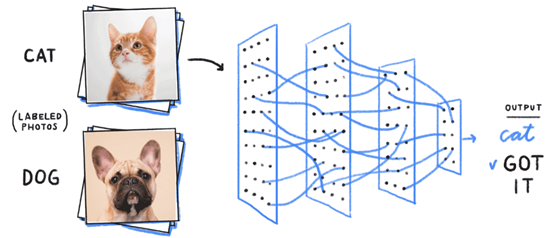
目标检测(或识别)基于图像分类。图像分类是通过上图所示的像素网格,将图像分类为一个类类别。目标识别是对图像中的对象进行识别和分类的过程,如下图所示:

为了使模型能够学习图像中对象的类别和位置,目标必须是一个五维标签(类别,x, y,宽度,长度)。
对象检测方法的内部工作
一种费机器(奢侈计算)的方法:穷举搜索
最简单的目标检测方法是对图像的各个子部分使用图像分类器,让我们来逐个考虑:
- 首先,选择想要执行目标检测的图像。

- 然后将该图像分割成不同的部分,或者说“区域”,如下图所示:

- 把每个区域看作一个单独的图像。
- 使用经典的图像分类器对每幅图像进行分类。
- 最后,将检测到目标的区域的所有图像与预测标签结合。

这种方法存在一个问题,对象可能具有的不同纵横比和空间位置,这可能导致对大量区域进行不必要的昂贵计算。它在计算时间方面存在太大的瓶颈,从而无法用于解决实际问题。
1. 区域提议方法和选择性搜索
最近有种方法是将问题分解为两个任务:首先检测感兴趣的区域,然后进行图像分类以确定每个对象的类别。
第一步通常是使用区域提议方法。这些方法输出可能包含感兴趣对象的边界框。如果在一个区域提议中正确地检测到目标对象,那么分类器也应该检测到了它。这就是为什么对这些方法而言,快速和高回应率非常重要。重要的是这两个方法不仅要是快速的,还要有着很高的回应率。
这两个方法还使用了一种聪明的体系结构,其中目标检测和分类任务的图像预处理部分相同,从而使其比简单地连接两个算法更快。选择性搜索是最常用的区域提议方法之一。
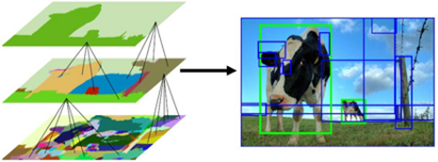
它的第一步是应用图像分割,如下所示:

从图像分割输出中,选择性搜索将依次进行:
- 从分割部分创建边界框,然后将其添加到区域建议列表中。
- 根据四种相似度:颜色,纹理,大小和形状,将几个相邻的小片段合并为较大的片段。
- 返回到第一步,直到该部分覆盖了整个图像。
层次分组
在了解了选择性搜索的工作原理后,接着看一些使用该法最常见的目标检测算法。
2. 第一目标检测算法:R-CNN
Ross Girshick等人提出了区域CNN(R-CNN),允许选择性搜索与CNN结合使用。实际上,对于每个区域方案(如本文中的2000),一个正向传播会通过CNN生成一个输出向量。这个向量将被输入到one-vs-all分类器中。每个类别一个分类器,例如一个分类器设置为如果图像是狗,则标签=1,否则为0,另一个分类器设置为如果图像是猫,标签= 1,否则为0,以此类推。R-CNN使用的分类算法是SVM。
但如何将该地区标记为提议呢?当然,如果该区域完全匹配真值,可以将其标为1,如果给定的对象根本不存在,这个对象可以被标为0。
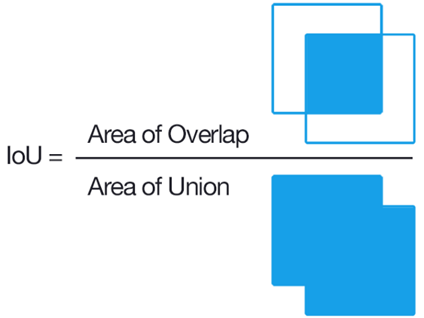
如果图像中存在对象的一部分怎么办?应该把这个区域标记为0还是1?为了确保训练分类器的区域是在预测一幅图像时可以实际获得的区域(不仅仅是那些完美匹配的区域),来看看选择性搜索和真值预测的框的并集(IoU)。
IoU是一个度量,用预测的框和真值框的重叠面积除以它们的并集面积来表示。它奖励成功的像素检测,惩罚误报,以防止算法选择整个图像。
回到R-CNN方法,如果IoU低于给定的阈值(0.3),那么相对应的标签将是0。
在对所有区域建议运行分类器后,R-CNN提出使用一个特定类的边界框(bbox)回归量来优化边界框。bbox回归量可以微调边界框的边界位置。例如,如果选择性搜索已经检测到一只狗,但只选择了它的一半,而意识到狗有四条腿的bbox回归量,将确保狗的整个身体被选中。
也多亏了新的bbox回归预测,我们可以使用非最大抑制(NMS)舍弃重叠建议。这里的想法是识别并删除相同对象的重叠框。NMS根据分类分数对每个类的建议进行排序,并计算具有最高概率分数的预测框与所有其他预测框(于同一类)的IoU。如果IoU高于给定的阈值(例如0.5),它就会放弃这些建议。然后对下一个最佳概率重复这一步。

综上所述,R-CNN遵循以下步骤:
- 根据选择性搜索创建区域建议(即,对图像中可能包含对象的部分进行预测)。
- 将这些地区带入到pre-trained模型,然后运用支持向量机分类子图像。通过预先训练的模型运行这些区域,然后通过SVM(支持向量机)对子图像进行分类。
- 通过边界框预测来运行正向预测,从而获得更好的边界框精度。
- 在预测过程中使用NMS去除重叠的建议。
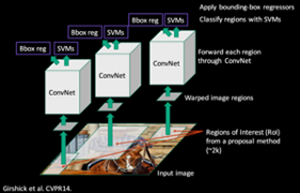
R-CNN 网络
不过,R-CNN也有一些问题:
- 该方法仍然需要分类所有地区建议,可能导致达到计算瓶颈——不可能将其用于实时用例。
- 在选择性搜索阶段不会学习,可能导致针对某些类型的数据集会提出糟糕的区域建议。
3. 小小的改进:Fast R-CNN(快速R-CNN)
Fast R-CNN,顾名思义,比R-CNN快。它基于R-CNN,但有两点不同:
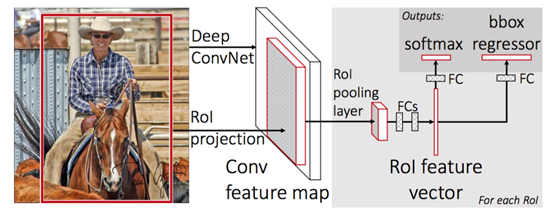
- 不再向CNN提供对每个地区的提议,通过对CNN提供整幅图像来生成一个卷积特性映射(使用一个过滤器将矢量的像素转换成另一个矢量,能得到一个卷积特性映射)。接下来,建议区域被识别与选择性搜索,然后利用区域兴趣池(RoI pooling)层将它们重塑成固定大小,从而能够作为全连接层的输入。
- Fast-RCNN使用更快,精度更高的softmax层而不是SVM来进行区域建议分类。
以下是该网络的架构:
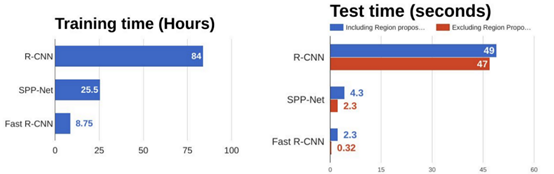
如下所示,Fast R-CNN在训练和测试方面比R-CNN要快得多。但是,受选择性搜索方法的影响,该方法仍然存在瓶颈。
4. R-CNN能有多快?——Faster R-CNN(更快的R-CNN)
虽然Fast R-CNN比R-CNN快得多,但其瓶颈仍然是选择性搜索,因为它非常耗时。因此,任少卿等人设计了更快R-CNN来解决这个问题,并提出用一个非常小的卷积网络区域提议网Region Proposal network(RPN)代替选择性搜索来寻找感兴趣的区域。
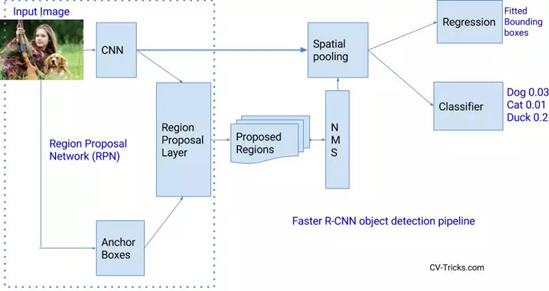
简而言之,RPN是一个直接寻找区域建议的小型网络。一种简单的方法是创建一个深度学习模型,输出x_min、y_min、x_max和x_max来获得一个区域建议的边界框(如果我们想要2000个区域,那么就需要8000个输出)。然而,有两个基本问题:
- 图像的大小和比例可能各不相同,所以很难创建一个能正确地预测原始坐标的模型。
- 在预测中有一些坐标排序约束(x_min < x_max, y_min < y_max)。
为了克服这个问题,我们将使用锚:锚是在图像上预设好不同比例和比例的框。(锚点是预定义的框,它们具有不同的比例,并在整个图像上缩放。)
例如,对于给定的中心点,通常从三组大小(例如,64px, 128px, 256px)和三种不同的宽高比(1/1,1/2,2/1)开始。在本例中,对于图像的给定像素(方框的中心),最终会有9个不同的方框。
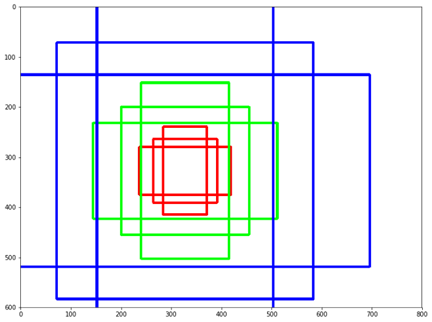
锚-比例和缩放
那么一张图片总共有多少个锚点呢?
我们不打算在原始图像上创建锚点,而是在最后一个卷积层的输出特征图上创建锚点,这一点非常重要。例如,对于一个1000*600的输入图像,由于每个像素有一个锚点,所以有1000 *600*9=5400000个锚点,这是错误的。确实,因为要在特征图谱上创建它们,所以需要考虑子采样比率,即由于卷积层的大步移动,输入和输出维度之间的因子减少。
在示例中,如果我们将这个比率设为16(像在VGG16中那样),那么特征图谱的每个空间位置将有9个锚,因此“只有”大约20000个锚(5400000/ 16^2)。这意味着输出特征中的两个连续像素对应于输入图像中相距16像素的两个点。注意,这个下降采样比率是Faster R-CNN的一个可调参数。
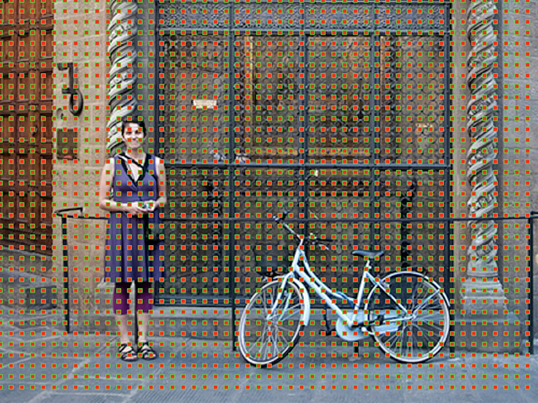
锚点中心
现在剩下的问题是如何从那20000个锚到2000个区域建议(与之前的区域建议数量相同),这是RPN的目标。
5. 如何训练区域建议网络
要实现这一点,需要RPN告知框包含的是对象还是背景,以及对象的精确坐标。输出预测有作为背景的概率,作为前景的概率,以及增量 Dx, Dy, Dw, Dh,它们是锚点和最终建议之间的差异。
(1) 第一,我们将删除跨边界锚(即因为图像边界而被减去的锚点),这给我们留下了约6000张图像。
(2) 如果存在以下两个条件中的任一,我们需要标签锚为正:
- 在所有锚中,该锚具有最高的IoU,并带有真值框。
- 锚点至少有0.7的IoU,并带有真值框。
(3) 如果锚的IoU在所有真值框中小于0.3,需要标签其为负。
(4) 舍弃所有剩下的锚。
(5) 训练二进制分类和边界框回归调整。
最后,关于实施的几点说明:
- 希望正锚和负锚的数量在小批处理中能够平衡。
- 因为想尽量减少损失而使用了多任务损失,这是有意义的——损失有错误预测前景或背景的错误,以及方框的准确性的错误。
- 使用预先训练好的模型中的权值来初始化卷积层。
6. 如何使用区域建议网络
- 所有锚(20000)计入后得到新的边界框和成为所有边界框的前景(即成为对象)的概率。
- 使用non-maximum抑制。
- 建议选择:最后,仅保留按分数排序的前N个建议(当N=2000,回到2000个区域建议)。
像之前的方法一样,最终获得了2000个方案。尽管看起来更复杂,这个预测步骤比以前的方法更快更准确。
下一步是使用RPN代替选择性搜索,创建一个与Fast R-CNN相似的模型(即RoI pooling和一个分类器+bbox回归器)。然而,不像之前那样,把这2000个建议进行裁剪,然后通过一个预先训练好的基础网络进行传递。而是重用现有的卷积特征图。实际上,使用RPN作为提案生成器的一个好处是在RPN和主检测器网络之间共享权值和CNN。
- 使用预先训练好的网络对RPN进行训练,然后进行微调。
- 使用预先训练好的网络对检测器网络进行训练,然后进行微调。使用来自RPN的建议区域。
- 使用来自第二个模型的权重对RPN进行初始化,然后进行微调——这将是最终的RPN模型)。
- 最后,对检测器网络进行微调(RPN权值固定)。CNN的特色图将在两个网络之间共享,请参见下图。
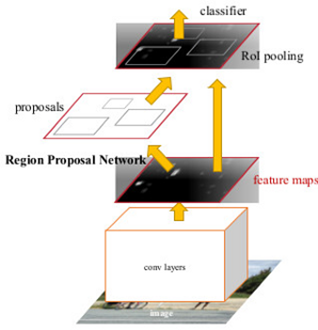
Faster R-CNN网络
综上所述,Faster R-CNN比之前的方法更准确,比Fast-R-CNN快10倍左右,这是一个很大的进步,也是实时评分的开始。
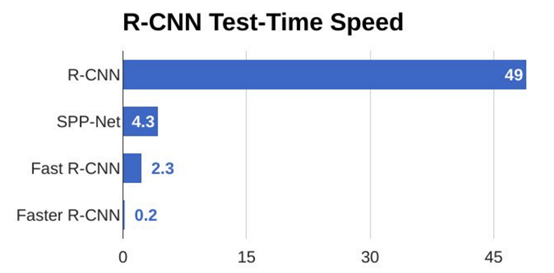
即便如此,区域建议检测模型对于嵌入式系统来说还是不够,因为这些模型太笨重,而且对于大多数实时评分案例来说速度也不够快——最后一例是大约每秒检测5张图像。