1 什么是LRU
LRU(Least recently used)最近最少使用,它的核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。因此 LRU 算法会根据数据的历史访问记录来进行排序,如果空间不足,就会淘汰掉最近最少使用的数据。
2 LRU 实现原理
由于 LRU 算法会将最近使用的数据优先级上升,因此需要数据结构支持排序,链表非常合适。
为什么不考虑数组呢?
由于 LRU 算法,一般都会应用在访问比较频繁的场景,因此,对数据的移动会频繁,而数组一旦移动,需要将移动到值的位置后面的所有数据的位置全部改变,效率比较低,不推荐使用。
3 双向链表之LinkedHashMap
前面我们分析到 LRU 的算法实现,可以使用链表实现,java 中 LinkedHashMap 就是一个双向链表。
LinkedHashMap是HashMap的子类,在HashMap数据结构的基础上,还维护着一个双向链表链接所有entry,这个链表定义了迭代顺序,通常是数据插入的顺序。
我们来看看LinkedHashMap的源码:
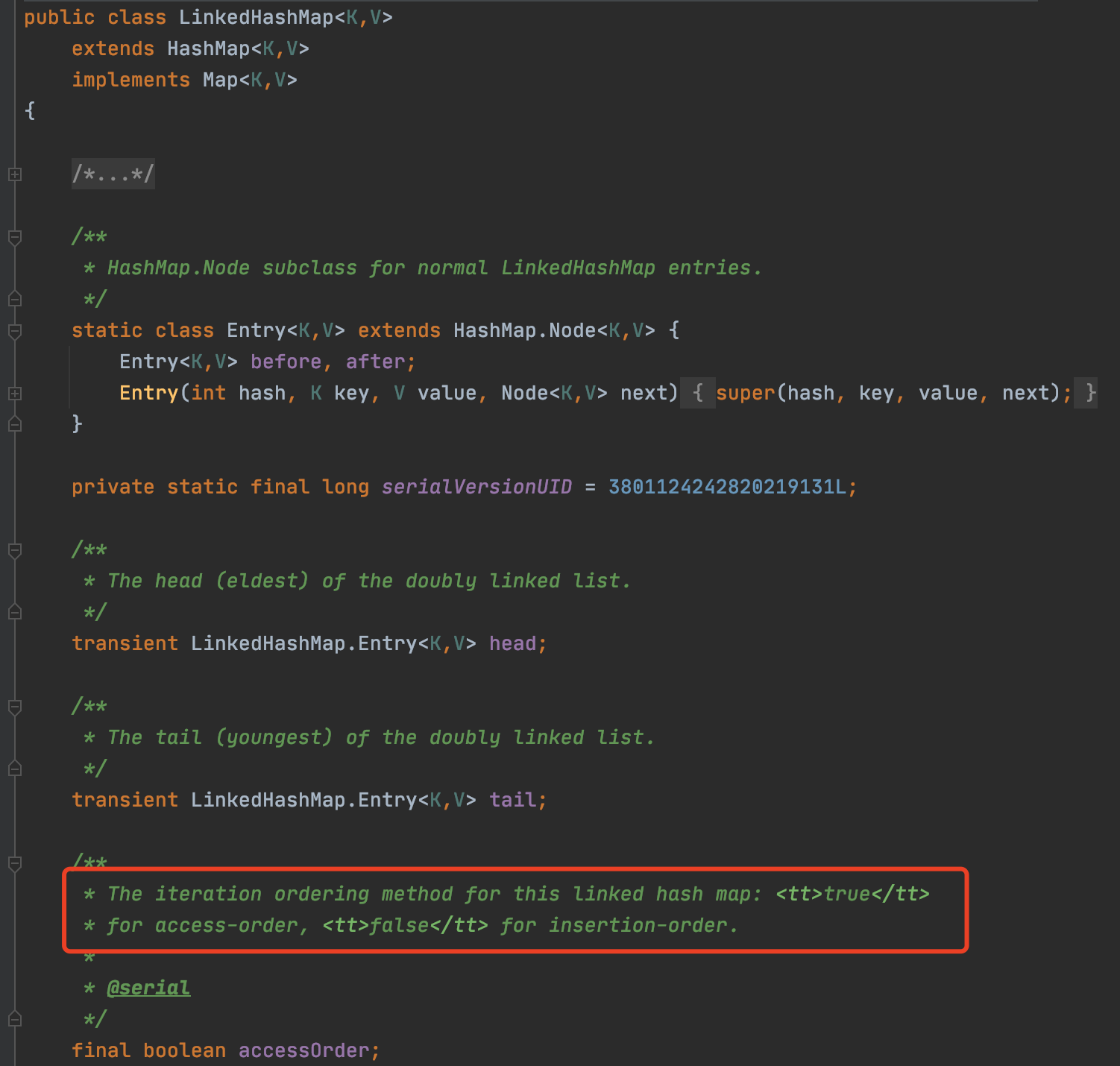
从源码中的定义可以看到,accessOrder 属性可以指定遍历 LinkedHashMap 的顺序,true 表示按照访问顺序,false 表示按照插入顺序,默认为 false。
由于LRU对访问顺序敏感,因此使用true来简单验证一下:
- public class LRUTest {
- public static void main(String[] args) {
- LinkedHashMap<String, Object> map = new LinkedHashMap<>(16, 0.75f, true);
- map.put("a", 1);
- map.put("b", 2);
- map.put("c", 3);
- System.out.println("before get " + map);
- map.get("a");
- System.out.println("after get" + map);
- }}
运行结果如下:
- before get {a=1, b=2, c=3}
- after get{b=2, c=3, a=1}
可以看到通过 accessOrder = true,可以让 LinkedHashMap 按照访问顺序进行排序。
那么 LinkedHashMap 是怎么做的呢?
我们看下get方法
- public V get(Object key) {
- Node<K,V> e;
- // 获取node
- if ((e = getNode(hash(key), key)) == null)
- return null;
- // 如果 accessOrder = true,则执行afterNodeAccess方法
- if (accessOrder)
- afterNodeAccess(e);
- return e.value;
- }
再看下afterNodeAccess方法,发现进行移动节点,到此移动节点的原理我们了解了
- void afterNodeAccess(Node<K,V> e) { // move node to last
- LinkedHashMap.Entry<K,V> last;
- if (accessOrder && (last = tail) != e) {
- LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; p.after = null; if (b == null)
- head = a; else
- b.after = a; if (a != null)
- a.before = b; else
- last = b;
- if (last == null)
- head = p; else {
- p.before = last;
- last.after = p; } tail = p; ++modCount; }}
目前,如果使用 LinkedHashMap 做LRU,还有一个问题困扰着我们,就是如果容量有限,该如何淘汰旧数据?
我们回过头看看 put 方法
- public V put(K key, V value) {
- return putVal(hash(key), key, value, false, true);
- }
- final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
- Node<K,V>[] tab; Node<K,V> p; int n, i;
- if ((tab = table) == null || (n = tab.length) == 0)
- n = (tab = resize()).length;
- if ((p = tab[i = (n - 1) & hash]) == null)
- tab[i] = newNode(hash, key, value, null);
- else {
- Node<K,V> e; K k;
- if (p.hash == hash &&
- ((k = p.key) == key || (key != null && key.equals(k))))
- e = p;
- else if (p instanceof TreeNode)
- e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
- else {
- for (int binCount = 0; ; ++binCount) {
- if ((e = p.next) == null) {
- p.next = newNode(hash, key, value, null);
- if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
- treeifyBin(tab, hash);
- break;
- }
- if (e.hash == hash &&
- ((k = e.key) == key || (key != null && key.equals(k))))
- break;
- p = e;
- }
- }
- if (e != null) { // existing mapping for key
- V oldValue = e.value;
- if (!onlyIfAbsent || oldValue == null)
- e.value = value;
- afterNodeAccess(e);
- return oldValue;
- }
- }
- ++modCount;
- if (++size > threshold)
- resize();
- afterNodeInsertion(evict);
- return null;
- }
- void afterNodeInsertion(boolean evict) { // possibly remove eldest
- LinkedHashMap.Entry<K,V> first;
- if (evict && (first = head) != null && removeEldestEntry(first)) {
- K key = first.key;
- removeNode(hash(key), key, null, false, true);
- }
- }
从put方法中逐步看下来,最终我们发现,如果 removeEldestEntry(first) 方法返回true,则会移除 head,这样就淘汰了最近都没使用的数据。完全符合LRU。
4 最简单的LRU实现
根据上面分析,我们可以如下实现一个最简单的LRU
- public class LRUCache<K,V> extends LinkedHashMap<K,V> {
- private int cacheSize;
- public LRUCache(int cacheSize) {
- // 注意:此处需要让 accessOrder = true
- super(cacheSize, 0.75f, true);
- this.cacheSize = cacheSize;
- }
- /**
- * 判断元素个数是否超过缓存的容量,超过需要移除
- */
- @Override
- protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
- return size() > cacheSize;
- }
- }