不再需要担心数据库性能优化的日子已经一去不复返了。
随着时代的进步,每一个新的创业者都想打造下一个Facebook,再加上收集每一个可能的数据点以提供更好的机器学习预测的心态,作为开发者,我们需要准备好我们的API,比以往任何时候都要好,以提供可靠而高效的终端,应该能够在海量数据中游刃有余。
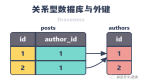
如果你做过一段时间的后台或者数据库架构,你可能已经做过分页查询了,比如这样。

对吧?
但是,如果你确实建立了这样的分页,我很抱歉的跟你说,你已经做错了。
你不同意我的观点?你不需要。Slack、Shopify和Mixmax都在用我们今天要讲的这个概念来分页他们的API。
我想请你说出一个没有处理过分页OFFSET和LIMIT的后端开发人员,对于MVP和低数据列表中的分页,它“有效”。
今天我们要讨论的是被广泛使用的(错误的)实现方式存在哪些问题,以及如何实现高性能的分页。
OFFSET和LIMIT有什么问题?
正如我们在上几段中简要探讨的那样,OFFSET和LIMIT非常适合于数据使用量很少甚至没有的项目。
当你的数据库开始收集的数据超过了服务器在内存中的存储量时,问题就出现了,你仍然需要对这些数据进行高性能的分页。
要做到这一点,数据库需要在每次请求分页时执行一次低效的全表扫描(在此期间可能会发生插入和删除,我们不希望数据过时!)。
| 什么是全表扫描?全表扫描(又名顺序扫描)是指在数据库中进行扫描,顺序读取表中的每一条记录,然后检查遇到的列的条件是否有效。这种类型的扫描被认为是最慢的,因为从磁盘上读取的I/O量很大,包括多次寻找以及昂贵的磁盘到内存的传输。 |
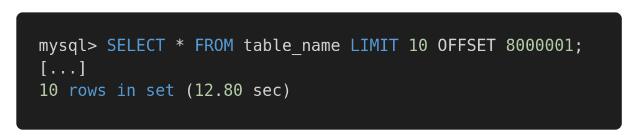
这意味着,如果你有100.000.000个用户,而你要求的OFFSET是50.000.000,那么它将需要获取所有这些记录(甚至不需要!),将它们放在内存中,然后才会得到在LIMIT中指定的20个结果。
因此,要在网站上显示这样的分页:
- 50.000 to 50.020 of 100.000
首先需要获取50.000行,看看这效率低下吗?
你应该使用什么
这是你应该使用的:

这是基于游标的分页。
你应该存储最后接收到的主键(通常是一个ID)和Limit,而不是在本地存储当前offset和limit将其与每个请求一起传递,这样查询最终可能与此类似。
为什么?因为通过显式传递最新的读取行,你可以根据有效的索引键告诉数据库确切从哪里开始搜索,而不必考虑该范围之外的任何行。
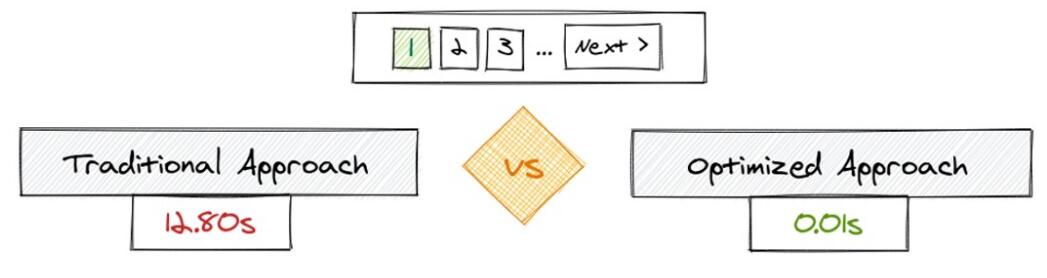
以下面的比较为例:
针对我们的优化版本:

接收到的记录完全相同,但是第一个查询花费了12.80秒,第二个查询花费了0.01秒。你能体会到差异吗?
注意事项
为了使游标分页能够无缝地工作,你需要有一个独特的、有顺序的列(或列),比如一个独特的整数ID,在某些特定的情况下,这可能是一个问题。
和以往一样,我的建议是一定要考虑每个表架构的优缺点,以及你需要在每个表中执行哪种查询。如果你需要在查询中处理大量相关数据,Rick James的“Lists article”文章可能会为你提供更深入的指导。
如果我们手中的问题与没有主键有关,比如我们有一个多对多的关系表,传统的OFFSET/LIMIT的方法在这些情况下总是可以使用的,然而这将重新引入潜在的较慢的查询。因此,我建议在要分页的表中使用自动递增的主键,即使只是出于分页的目的。
总结
这其中最主要的启示应该是,无论你的查询是用1k行还是用1M行,都要时刻检查你的查询性能如何。可扩展性是极其重要的,如果从一开始就能正确地实施,肯定可以避免未来许多头痛的问题。
哦。而且,请不要忘记学习索引并explain queries。
如果你正在寻找如何在ElasticSearch上实现光标分页,请随时查看文章ElasticSearch--你应该这样分页你的结果。
ElasticSearch--你应该这样分页你的结果:
https://medium.com/@tmateus/elasticsearch-this-is-how-you-should-paginate-your-results-5d1c71bfe060