一、什么是Hive?
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。Hive支持HSQL,是一种类SQL。
也由于这种机制导致Hive最大的缺点是慢。MapReduce调度本身只适合批量,长周期任务,类似查询这种要求短平快的业务,代价太高。
二、什么是Impala?
Impala是用于处理存储在Hadoop集群中的大量数据的MPP(大规模并行处理)SQL查询引擎。它是一个用C++和Java编写的开源软件。与其他Hadoop的SQL引擎相比,它提供了高性能和低延迟。
换句话说,Impala是性能最高的SQL引擎(提供类似RDBMS的体验),它提供了访问存储在Hadoop分布式文件系统中的数据的最快方法。
三、Hive vs Impala
Impala与Hive都是构建在Hadoop之上的数据查询工具,各有不同的侧重适应面,但从客户端使用来看Impala与Hive有很多的共同之处,如数据表元数据、ODBC/JDBC驱动、SQL语法、灵活的文件格式、存储资源池等。Impala与Hive在Hadoop中的关系如下图所示。
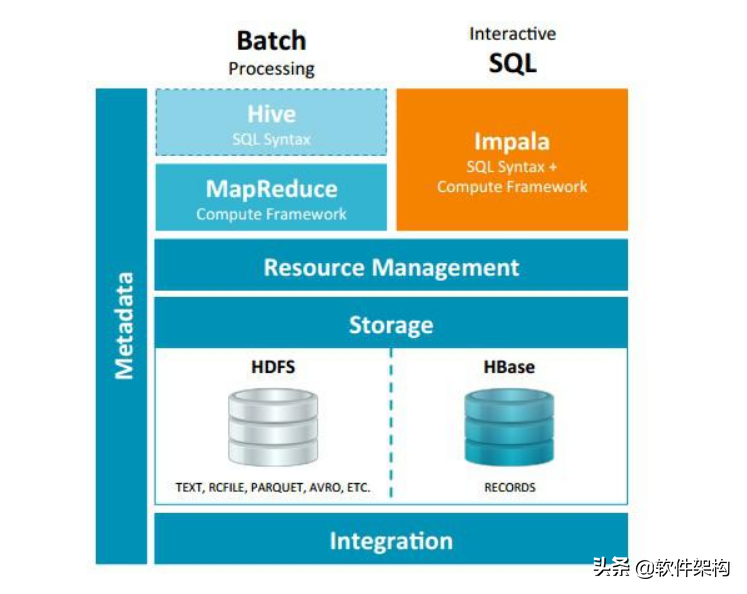
Hive适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询,Impala给数据分析人员提供了快速实验、验证想法的大数据分析工具。可以先使用Hive进行数据转换处理,之后使用Impala在Hive处理后的结果数据集上进行快速的数据分析。
Impala没有使用 MapReduce进行并行计算,虽然MapReduce是非常好的并行计算框架,但它更多的面向批处理模式,而不是面向交互式的SQL执行。与 MapReduce相比:Impala把整个查询分成一执行计划树,而不是一连串的MapReduce任务。在分发执行计划后,Impala使用拉式获取数据的方式获取结果,把结果数据组成按执行树流式传递汇集,减少了把中间结果写入磁盘的步骤,再从磁盘读取数据的开销。Impala使用服务的方式避免每次执行查询都需要启动的开销,即相比Hive没了MapReduce启动时间。
四、处理数据的方式
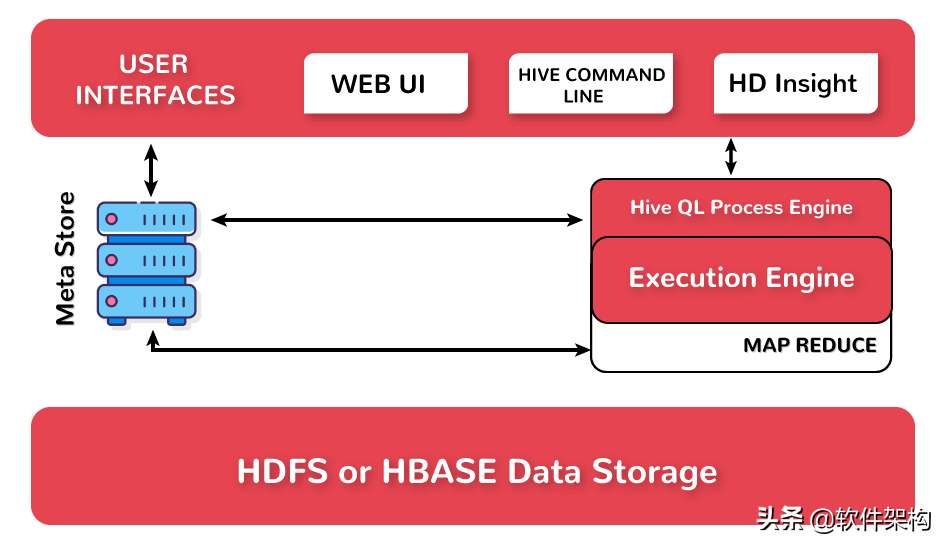
(1)Hive处理数据的方式
HiveQL通过CLI/Web UI或者thrift 、odbc 或 jdbc接口的外部接口提交,经过complier编译器,运用Metastore中的元数据进行类型检测和语法分析,生成一个逻辑计划(logical plan),然后通过简单的优化处理,产生一个以有向无环图DAG数据结构形式展现的MapReduce任务。
(2)Impala处理数据的方式
每当用户使用提供的任何接口发起查询时,集群中的Impalads之一就会接受该查询。 此Impalad被视为该特定查询的协调程序。
在接收到查询后,查询协调器使用Hive元存储中的表模式验证查询是否合适。 然后,它从HDFS名称节点(NameNode)收集关于执行查询所需的数据的位置的信息,并将该信息发送到其他Impalad以便执行查询。
所有其他Impala守护程序读取指定的数据块并处理查询。 一旦所有守护程序完成其任务,查询协调器将收集结果并将其传递给用户。
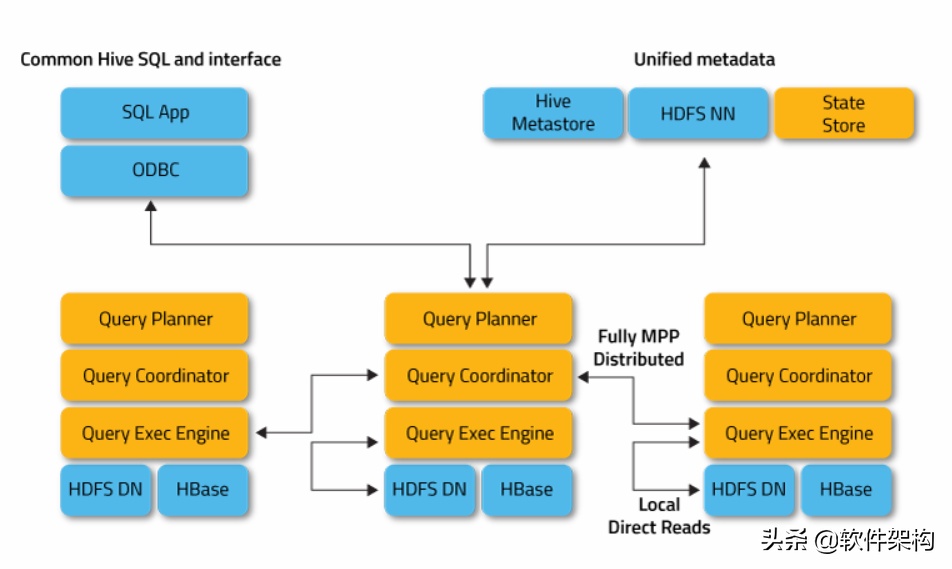
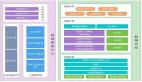
黄色部分是 Imapla模块,蓝色部分为运行 Impala 依赖的其他模块。Impala 整体分为两部分:StateStore 和 Impalad。
StateStore 是 Impala 的一个子服务,用来监控集群中各个节点的健康状况,提供节点注册,错误检测等功能。
Impala Daemon 进程是运行在集群每个节点上的守护进程,每个节点上这个进程名称为Impalad。
Impalad 运行在 DataNode 节点上,主要有两个作用 :
- 一是协调Client提交的 Query 的执行,给其他Impalad分配任务,收集其他Impalad的执行结果进行汇总;
- 二是这个Impalad也会执行其他Impalad给其分配的任务,执行这部分任务主要就是对本地HDFS和HBase中的数据进行操作。
Impala中表的元数据存储借用的是Hive的,也就是表的元数据信息存储在Hive的Metastore中。
位于HDFS数据节点DataNode上的每个Impalad进程,都具有如下几个模块:
- Query Planner;
- Query Coordinator;
- Query Exec Engine;
Query Planner 接收来自SQL APP和ODBC的SQL语句,解释成功执行计划。Query Coordinator将执行计划进行优化和拆分,形成执行计划片段,调度这些片段分发到各个节点上,由各个节点上的Query Exec Engine 负责执行,最后返回中间结果,这些中间结果经过聚集之后,最终返回给用户。