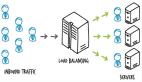
微服务架构是目前在软件工程界广泛采用的一种做法。 采用这种体系结构样式的组织发现自己正在处理分布式故障的增加的复杂性(除了实现业务逻辑的复杂性之外)。
分布式计算的谬论有据可查,但难以发现。 结果,构建大规模,可靠的分布式系统架构是一个难题。 作为必然的结果,当我们向网络中引入网络交互的复杂性时,在非分布式系统中看起来不错的代码可能会成为一个巨大的问题。
在生产代码中遇到故障模式数年并根源导致它们进入各种代码位后,我(和许多其他人一样)来确定一些更常见的故障模式。 这些在公司和语言堆栈之间略有不同(取决于内部基础结构和工具的成熟度),但是其中一个或多个通常是导致生产问题的原因。
这是一些代码检查指南,它们是我检查与分布式环境中的系统间通信有关的代码的基本清单。 并非所有这些方法始终都适用,但是它们都是非常基本的问题,因此我觉得机械地将此列表下标,将缺失的项目标记为进一步的讨论很有用且令人放心。 从这个意义上讲,这是一个愚蠢的清单,您可能始终希望遵循该清单。
调用远程系统时,远程系统出现故障时会发生什么?
无论系统设计了多大的维护,它都会在某些时候失效-这是在生产环境中运行软件的事实。 它可能由于错误,某些基础结构问题,流量突然激增或忽略的缓慢衰减而失败,但失败了。 呼叫者如何处理此故障将确定整个体系结构的弹性和健壮性。
- 定义错误处理路径:在代码中必须有明确定义的错误处理路径,而不仅仅是让您的系统在最终用户面前爆炸。 无论是设计合理的错误页面,具有错误度量标准的异常日志,还是具有后备机制的断路器,都必须明确地处理错误。
- 制定恢复计划:考虑代码中的每个远程交互,并弄清楚我们需要做什么来恢复被中断的工作。 我们的工作流程是否需要保持有状态,以便从故障点被触发? 我们是否将所有失败的有效负载发布到重试队列/数据库表,并在远程系统恢复运行时重试它们? 我们是否有脚本来比较两个系统的数据库并以某种方式使其同步? 在部署实际代码之前,应实施并部署明确的,最好是系统的恢复计划。
远程系统变慢时会发生什么?
这比完全失败更隐患,因为我们不知道远程系统是否正常工作。 为了处理这种情况,应始终检查以下内容。
始终在远程系统调用上设置超时:这包括远程API调用,事件发布和数据库调用上的超时。 我在太多的代码中发现了这个简单的缺陷,以至于它同时令人震惊,但并非无法预料。 检查是否为调用中的所有远程系统设置了有限且合理的超时,以避免由于某种原因远程系统无响应时在等待中浪费资源。
- 超时重试:网络和系统不可靠,重试是系统弹性的绝对必要条件。 重试通常会消除系统间交互中的许多"漏洞"。 如果可能,请在重试中使用某种退避(固定的,指数的)。 在重试机制上增加一点抖动可以使呼吸变得有些呼吸。 如果负载很大,则将被调用的系统放置在房间中,可能会提高成功率。 重试的另一面是幂等,我们将在本文后面介绍。
- 使用断路器:并没有预包装此功能的许多实现,但是我看到公司在内部编写自己的包装器。 如果您有这种选择,请一定要练习。 如果您不这样做,请考虑投资建设它。 有一个定义良好的框架来定义发生错误时的后备情况,这是一个很好的先例
- 不要像失败一样处理超时-超时不是失败,而是不确定的情况,应该以支持解决不确定性的方式进行处理。 我们应该建立明确的解决机制,使系统可以在发生超时的情况下保持同步。 范围从简单的对帐脚本到有状态的工作流再到死信队列等等。
- 以可控制的方式使用批处理:如果要处理大量数据,请进行批处理远程调用(API调用,数据库读取),而不是一对一地进行,以消除网络开销。 但是请记住,批处理大小越大,总的延迟就越大,可能失败的工作单元也就越大。 因此,优化批处理以提高性能和容错能力。
在构建系统时,其他人将调用
- 所有API都必须是幂等的:这是重试API超时的另一面。 仅当您的API安全重试且不会引起意外副作用时,调用方才可以重试。 API是指同步API和任何消息传递接口-客户端可以发布同一条消息两次(或者代理可以发送两次)。
- 明确定义响应时间和吞吐量SLA,并遵循它们进行编码:在分布式系统中,快速失败比让呼叫者等待要好得多。 诚然,吞吐量SLA难以实现(分布式速率限制本身很难解决),但是我们应该认识到我们的SLA,并规定如果要解决这些问题,可以主动使呼叫失败。 另一个重要的方面是知道下游系统的响应时间,以便您可以确定系统最快的速度。
- 定义和限制批处理API:如果要公开批处理API,则最大批处理大小应由我们希望的SLA明确定义和限制。 这是兑现SLA的必然结果。
- 事先考虑可观察性:可观察性意味着能够分析系统的行为而不必关注系统内部。 事先考虑一下您应该收集有关系统的哪些指标以及应收集哪些数据,这些数据将使您能够回答以前未提出的问题。 然后对系统进行检测以获取此数据。 执行此操作的强大机制是识别系统的域模型并在域中每次发生事件时发布事件(例如,接收到请求ID 123,返回请求123的响应-请注意如何使用这两个"域"事件 得出称为"响应时间"的新指标。原始数据>>预先确定的汇总)。
一般准则
- 主动缓存:网络是多变的,因此请尽可能多地缓存数据,以尽可能接近数据的使用情况。 当然,您的缓存机制也可以是远程的(例如,在另一台计算机上运行的Redis服务器),但是至少您可以将数据带入您的控制域并减少其他系统的负载。
- 考虑故障单位:如果一个API或一条消息代表多个工作单元(批量),那么故障的单位是什么? 整个有效负载应全部失败一次,还是各个单元可以独立成功或失败。 在部分成功的情况下,API是否以成功或失败代码响应?
- 在系统边缘隔离外部域对象:从长远来看,这是我看到的又一个麻烦。 我们不应该以重用的名义在整个系统中使用其他系统的域对象。 这将我们的系统与另一个系统对实体的建模耦合在一起,并且每次其他系统发生更改时,我们都会进行大量重构。 我们应该始终构建自己的实体表示,并将外部有效负载转换为该架构,然后在系统内部使用它。
我希望您发现这些准则有助于减少分布式系统代码中最常见的错误。 我想听听您是否认为其他一些考虑因素很容易应用但非常有效-我们可以在此处添加它们!